本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
節點和工作負載效率
有效率地處理工作負載和節點可降低複雜性/成本,同時提高效能和規模。規劃此效率時需要考慮許多因素,而且在權衡方面,相較於每個功能的一個最佳實務設定,最簡單的方式是考慮。讓我們在下一節深入探索這些權衡。
節點選擇
使用略大的節點大小 (4-12xlarge) 會增加我們用來執行 Pod 的可用空間,因為它可減少用於「額外負荷」的節點百分比,例如 DaemonSets
注意
由於 k8s 以一般規則水平擴展,因此對於大多數應用程式而言,採取 NUMA 大小節點的效能影響並不合理,因此建議低於該節點大小的範圍。
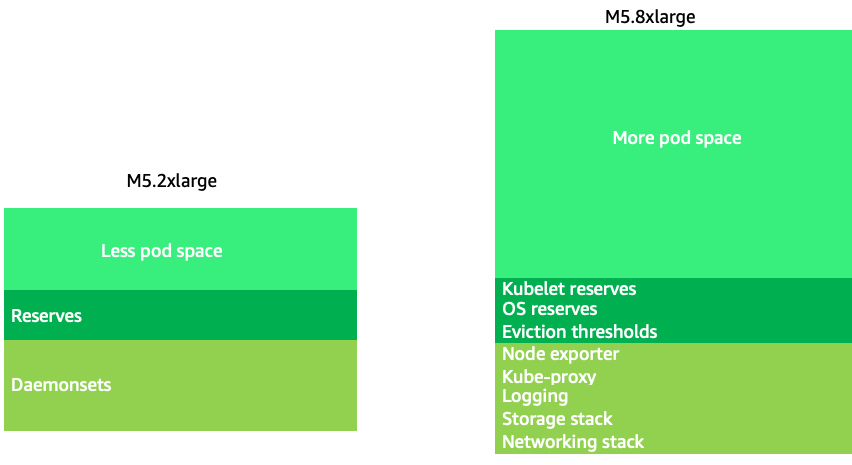
大型節點大小可讓我們在每個節點擁有較高百分比的可用空間。不過,此模型可以透過使用太多 Pod 封裝節點來導致錯誤或使節點飽和,進而達到極端。監控節點飽和度是成功使用較大節點大小的關鍵。
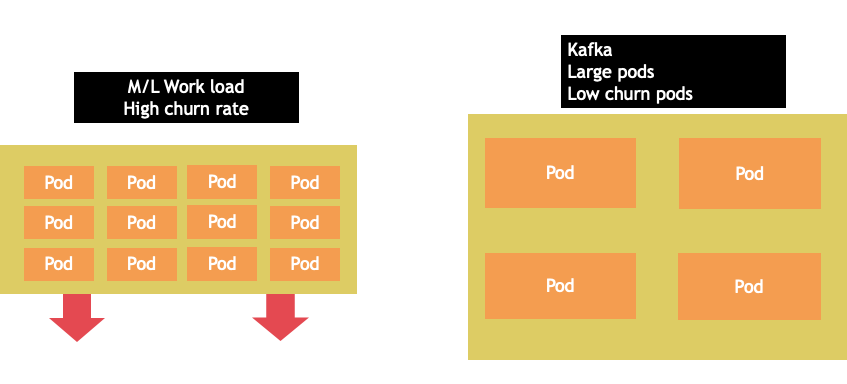
節點選擇很少是 one-size-fits-all 提案。通常最好將具有顯著不同流失率的工作負載分割為不同的節點群組。4xlarge 系列執行個體最能提供具有高流失率的小型批次工作負載,而 Kafka 等大型應用程式需要 8 個 vCPU,而 12xlarge 系列更能提供低流失率。
注意
節點大小非常大的另一個考量因素是,因為 CGROUPS 不會從容器化應用程式中隱藏 vCPU 總數。動態執行時間通常會產生意外數量的作業系統執行緒,造成難以進行故障診斷的延遲。對於這些應用程式,建議使用 CPU 鎖定
節點儲存貯體封裝
Kubernetes 與 Linux 規則
在 Kubernetes 上處理工作負載時,需要注意兩組規則。Kubernetes 排程器的規則,使用請求值來排程節點上的 Pod,然後排程 Pod 之後會發生什麼情況,這是 Linux 的領域,而不是 Kubernetes。
Kubernetes 排程器完成後,一組新的規則接管 Linux 完全公平排程器 (CFS)。關鍵點是 Linux CFS 沒有核心的概念。我們將討論為什麼在核心中思考可能會導致最佳化規模工作負載的重大問題。
在 核心中思考
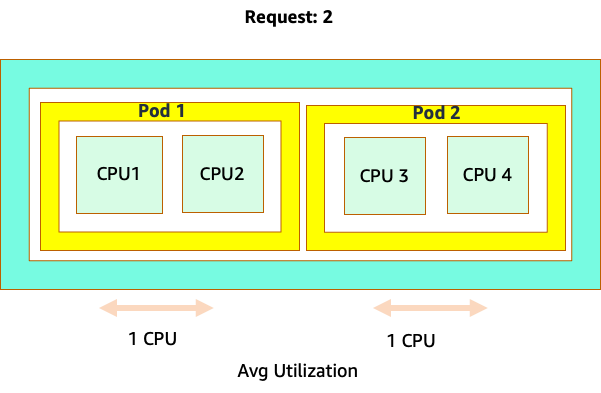
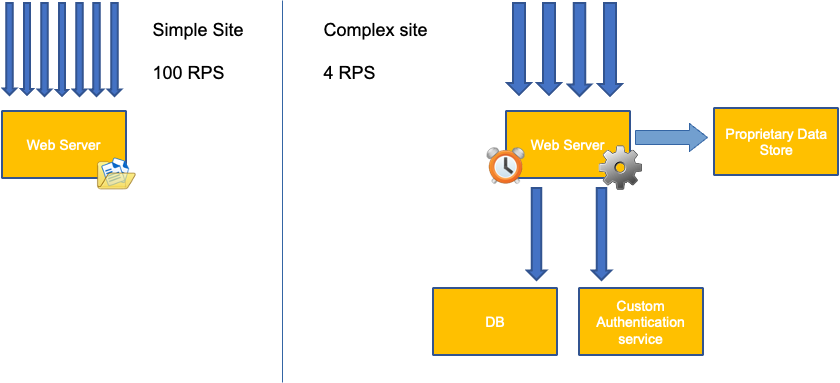
混淆開始是因為 Kubernetes 排程器確實具有核心的概念。從 Kubernetes 排程器的角度來看,如果我們查看具有 4 個 NGINX Pod 的節點,每個節點都有一個核心集的請求,節點看起來會像這樣。
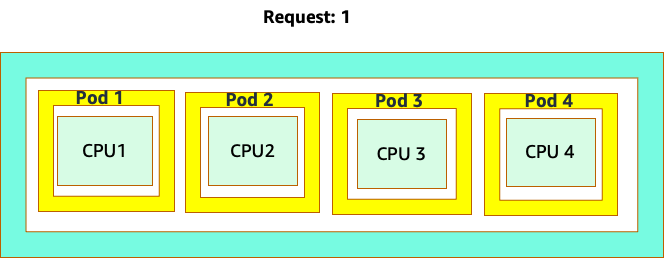
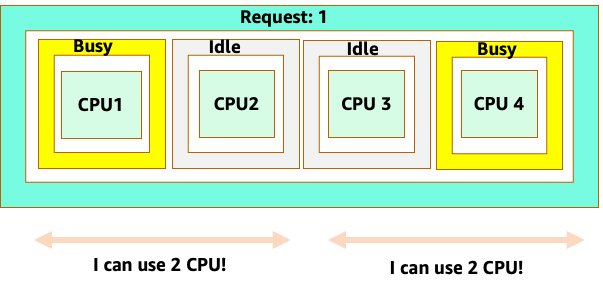
不過,讓我們進行思考實驗,了解這與 LinuxCFS 觀點的差異。使用 Linux MCU 系統時要記住的最重要事項是:忙碌容器 (CGROUPS) 是計入共用系統的唯一容器。在這種情況下,只有第一個容器處於忙碌狀態,因此允許它在節點上使用所有 4 個核心。
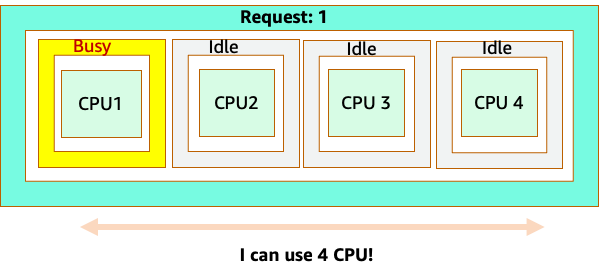
為什麼這很重要? 假設我們在開發叢集中執行效能測試,其中 NGINX 應用程式是該節點上唯一忙碌的容器。當我們將應用程式移至生產環境時,會發生下列情況:NGINX 應用程式需要 4 個 vCPU 的資源,但由於節點上的所有其他 Pod 都忙碌中,因此我們的應用程式效能受到限制。
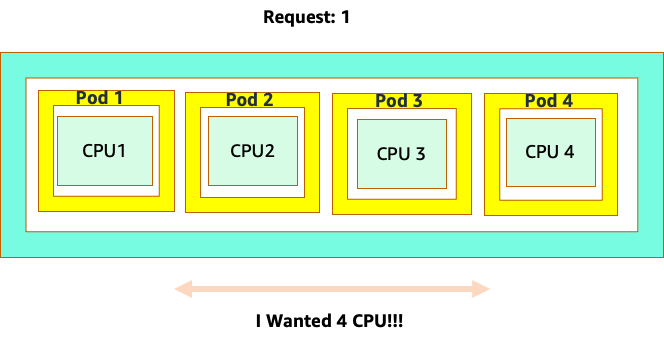
這種情況會導致我們在不必要的情況下新增更多容器,因為我們不允許應用程式擴展到他們的「sweet spot」`。讓我們更詳細"sweet spot"地探索 的這個重要概念。
應用程式正確調整大小
每個應用程式都有無法再接受流量的特定點。超過此點可能會增加處理時間,甚至會在推送遠超過此點時捨棄流量。這稱為應用程式的飽和點。為了避免擴展問題,我們應該在應用程式達到飽和點之前嘗試擴展應用程式。讓我們將此點稱為甜點。
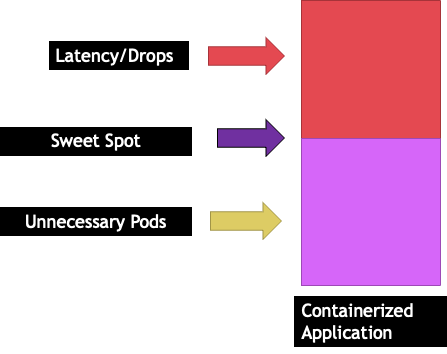
我們需要測試每個應用程式,以了解其甜點。這裡不會有通用指引,因為每個應用程式都不同。在此測試期間,我們嘗試了解顯示應用程式飽和點的最佳指標。使用率指標通常用於表示應用程式飽和,但這可能會快速導致擴展問題 (我們將在稍後的章節中詳細探討此主題)。一旦我們擁有這個 "`sweet spot"`,就可以使用它來有效率地擴展工作負載。
相反地,如果我們在甜點之前順利擴展並造成不必要的 Pod,會發生什麼情況? 讓我們在下一節探索。
Pod 擴展
若要了解建立不必要的 Pod 如何快速失控,讓我們來看看左側的第一個範例。處理每秒 100 個請求時,此容器的正確垂直擴展會佔用大約兩個 vCPUs 使用率。不過,如果我們透過將請求設定為一半核心來少佈建請求值,現在我們實際需要的每個 Pod 都需要 4 個 Pod。進一步加劇此問題,如果我們的 HPA
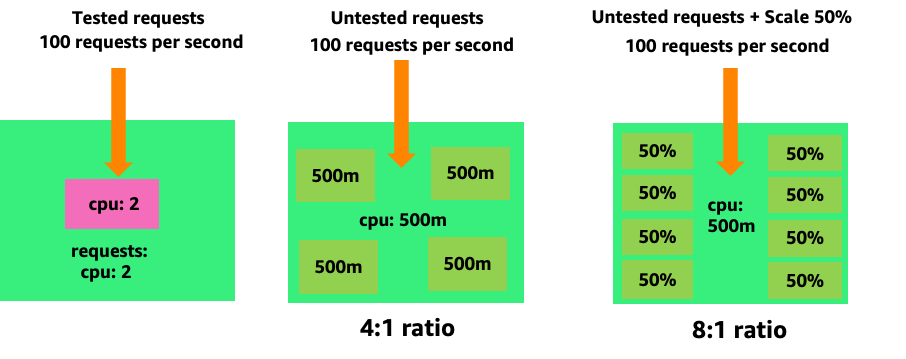
向上擴展此問題,我們可以快速了解此問題如何解決。部署 10 個 Pod,其甜點設定不正確,可能會快速旋轉至 80 個 Pod,以及執行它們所需的額外基礎設施。
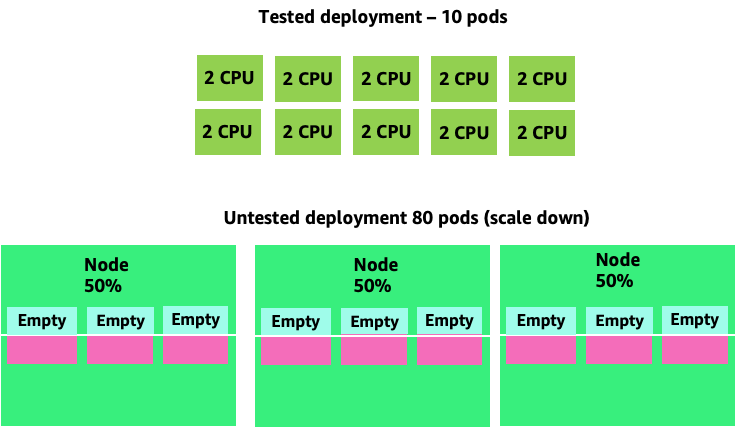
現在我們了解不允許應用程式在其甜甜圈中運作的影響,讓我們回到節點層級,並詢問 Kubernetes 排程器和 Linux MCU 之間的這種差異為什麼如此重要?
使用 HPA 擴展和縮減規模時,我們可能會有許多空間來配置更多 Pod 的案例。這會是錯誤的決策,因為左側描述的節點已經達到 100% CPU 使用率。在不切實際但理論上可能的情況下,我們可以有另一個極端的節點完全滿,但 CPU 使用率為零。
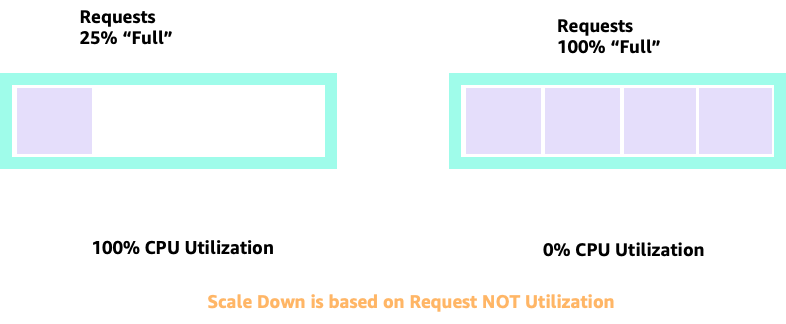
設定請求
將請求設定為該應用程式的 "sweet spot" 值會很有吸引力,但這會導致效率低下,如下圖所示。在這裡,我們已將請求值設定為 2 個 vCPU,但這些 Pod 的平均使用率大部分時間只會執行 1 個 CPU。此設定會導致我們浪費 50% 的 CPU 週期,這是無法接受的。
這可讓我們對問題做出複雜的答案。在清空中無法考慮容器使用率;一個必須考慮節點上執行的其他應用程式。在下列範例中,本質上爆量的容器會與兩個低 CPU 使用率容器混合,這些容器可能受到記憶體限制。以這種方式,我們允許容器到達他們的甜點,而無需對節點課稅。
要從中採取的重要概念是,使用核心的 Kubernetes 排程器概念來了解 Linux 容器效能可能會導致決策不佳,因為它們無關。
注意
Linux MCU 有其強而有力的點。對於 I/O 型工作負載尤其如此。不過,如果您的應用程式使用不含附屬項目的完整核心,而且沒有 I/O 需求,CPU 鎖定可能會從此程序中移除很大的複雜性,並受到這些警告的鼓勵。
使用率與飽和度
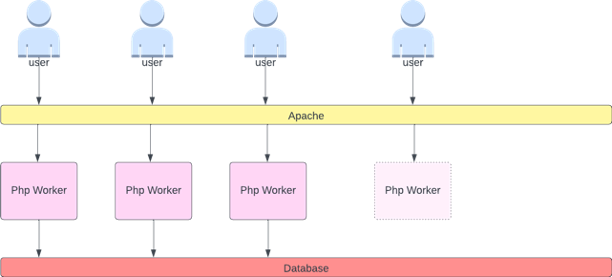
應用程式擴展的常見錯誤是僅使用擴展指標的 CPU 使用率。在複雜的應用程式中,這幾乎一律是應用程式實際上因請求而飽和的不良指標。在左側範例中,我們看到所有請求實際上都在命中 Web 伺服器,因此 CPU 使用率在飽和的情況下追蹤良好。
在真實世界的應用程式中,其中一些請求可能會由資料庫層或身分驗證層等提供服務。在這種情況下,請注意,CPU 不會在飽和的情況下追蹤,因為請求是由其他實體提供服務。在這種情況下,CPU 是飽和的極差指標。
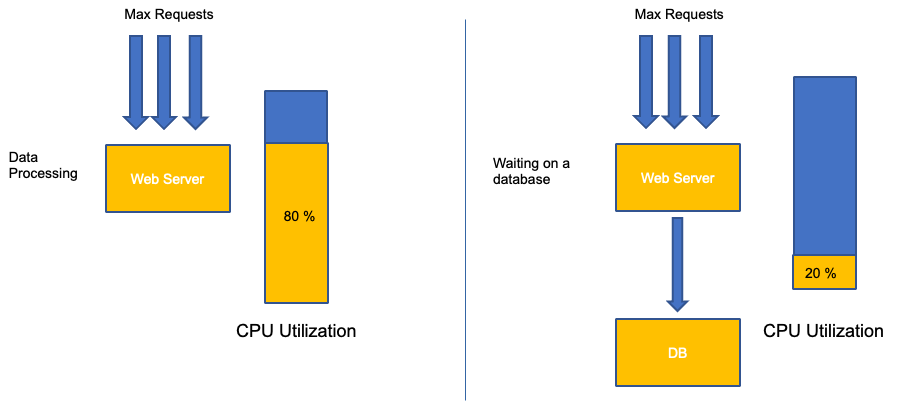
在應用程式效能中使用錯誤的指標,是 Kubernetes 中不必要且無法預測擴展的首要原因。為您正在使用的應用程式類型挑選正確的飽和度指標時,必須特別小心。請務必注意,沒有一個大小適合所有可以提供的建議。根據所使用的語言和有問題的應用程式類型,有一組不同的飽和度指標。
我們可能會認為此問題僅與 CPU 使用率有關,但其他常見的指標,例如每秒請求數,也可能與上述討論的問題完全相同。請注意,請求也可以前往資料庫層、身分驗證層,而不是由我們的 Web 伺服器直接服務,因此 Web 伺服器本身的真實飽和度指標很差。
遺憾的是,在挑選正確的飽和指標時,沒有簡單的答案。以下是一些需要考慮的指導方針:
-
了解您的語言執行時間 - 具有多個作業系統執行緒的語言與單一執行緒應用程式的反應不同,因此對節點的影響不同。
-
了解正確的垂直擴展 - 在擴展新 Pod 之前,您希望應用程式垂直擴展中有多少緩衝?
-
哪些指標真正反映應用程式的飽和 - Kafka Producer 的飽和指標與複雜的 Web 應用程式截然不同。
-
節點上的所有其他應用程式如何互相影響 - 在清空節點上的其他工作負載時,應用程式效能不會完成。
若要結束本節,可以很容易地將上述內容關閉為過於複雜且不必要的。我們通常會遇到問題,但我們不知道問題的真正本質,因為我們查看錯誤的指標。在下一節中,我們將探討發生這種情況的方式。
節點飽和度
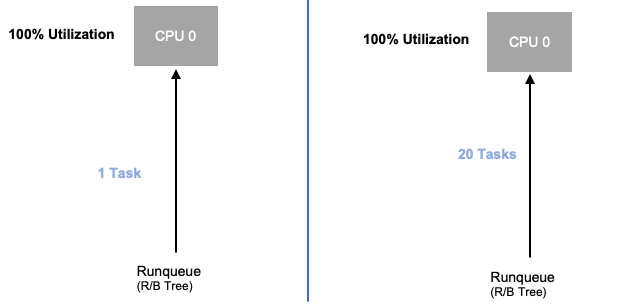
現在我們已經探索應用程式飽和,讓我們從節點的觀點來看這個相同的概念。讓我們採用 100% 使用的兩個 CPUs,以查看使用率與飽和度之間的差異。
左側的 vCPU 是 100% 使用的,但沒有其他任務正在等待在此 vCPU 上執行,因此從理論上來說,這相當有效率。同時,我們在第二個範例中有 20 個單一執行緒應用程式等待 vCPU 處理。現在,所有 20 個應用程式在等待 vCPU 處理時都會遇到某種類型的延遲。換句話說,右側的 vCPU 是飽和的。
只有當我們只查看使用率時,我們才會看到此問題,但我們可能會將此延遲歸因於無關的內容,例如聯網,這會導致我們走錯路徑。
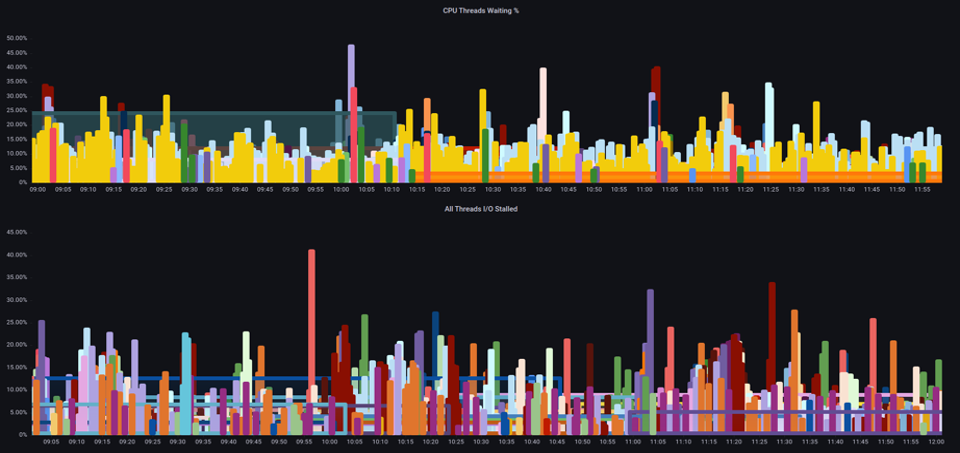
請務必檢視飽和指標,而不只是在增加任何指定時間在節點上執行的 Pod 總數時的使用率指標,因為我們可以輕易地錯過擁有過度飽和節點的事實。對於此任務,我們可以使用壓力停止資訊指標,如下圖所示。
PromQL - 停滯的 I/O
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
注意
如需壓力停止指標的詳細資訊,請參閱 https://https://facebookmicrosites.github.io/psi/docs/overview*
透過這些指標,我們可以判斷執行緒是否在 CPU 上等待,或即使方塊上的每個執行緒都停滯在等待資源,例如記憶體或 I/O。 例如,我們可以看到執行個體上每個執行緒在 1 分鐘內停滯等待輸入/輸出的百分比。
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
使用此指標,我們可以在上圖中看到箱子上的每個執行緒停滯了 45% 在高水位處等待輸入/輸出的時間,這表示我們在該分鐘拋棄了所有這些 CPU 週期。了解發生這種情況有助於我們回收大量的 vCPU 時間,從而提高擴展效率。
HPA V2
建議使用 HPA API 的 autoscaling/v2 版本。在某些邊緣情況下,較舊版本的 HPA API 可能會卡住擴展。它還僅限於在每個擴展步驟期間加倍的 Pod,這為需要快速擴展的小型部署產生了問題。
Autoscaling/v2 可讓我們更靈活地包含多個擴展條件,並在使用自訂和外部指標 (非 K8s 指標) 時,讓我們有很大的靈活性。
例如,我們可以擴展最高三個值 (請參閱以下內容)。如果所有 Pod 的平均使用率超過 50%、如果自訂指標每秒輸入封包超過平均 1,000,或輸入物件超過每秒 10K000 個請求,我們會進行擴展。
注意
這只是為了顯示自動擴展 API 的彈性,我們建議避免在生產環境中難以進行故障診斷的過於複雜的規則。
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
不過,我們了解了將此類指標用於複雜 Web 應用程式的風險。在這種情況下,我們會使用自訂或外部指標,準確反映應用程式飽和與使用率,以提供更好的服務。HPAv2 能夠根據任何指標進行擴展,從而實現這一點,但我們仍然需要找到該指標並將其匯出到 Kubernetes 以供使用。
例如,我們可以查看 Apache 中的作用中執行緒佇列計數。這通常會建立「更順暢」的擴展設定檔 (該詞彙很快就會更詳細)。如果執行緒處於作用中狀態,則無論該執行緒是在資料庫層上等待還是在本機服務請求,如果使用所有應用程式執行緒,這是應用程式飽和的良好指示。
我們可以使用此執行緒耗盡做為訊號,以建立具有完整可用執行緒集區的新 Pod。這也讓我們能夠控制希望應用程式中的緩衝區在繁重流量期間吸收的大小。例如,如果總執行緒集區為 10,則擴展 4 個使用的執行緒與 8 個使用的執行緒會對擴展應用程式時可用的緩衝產生重大影響。設定 4 對需要在繁重負載下快速擴展的應用程式來說很有意義,其中設定 8 會更有效率地使用我們的資源,如果我們有足夠的時間因為請求數量緩慢增加,而不是隨著時間大幅增加而擴展。
在擴展方面,「平滑」一詞是什麼意思? 請注意下表,我們使用 CPU 做為指標。此部署中的 Pod 會在短時間內激增,從 50 個 Pod 開始,最多只有 250 個 Pod 才能立即縮減規模。這是叢集上 churn 的主要原因。
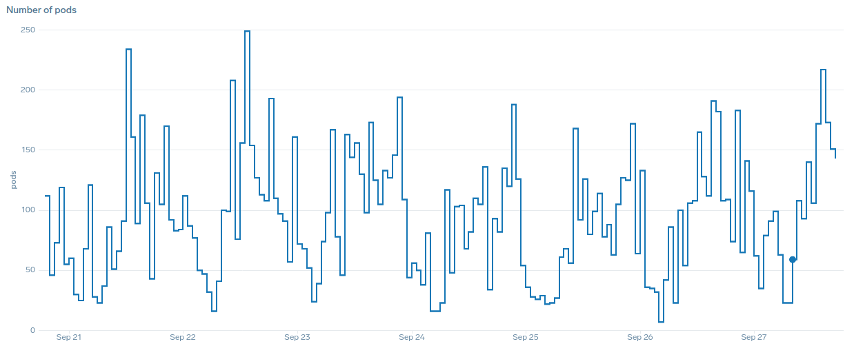
請注意,在我們變更為反映應用程式正確甜點 (圖表中部) 的指標後,如何順利擴展。我們的擴展現在是有效率的,並且我們的 Pod 可以透過調整請求設定來完全擴展我們提供的前端空間。現在,一小群 Pod 正在執行數百個 Pod 之前執行的工作。真實世界資料顯示,這是 Kubernetes 叢集可擴展性的第一大因素。
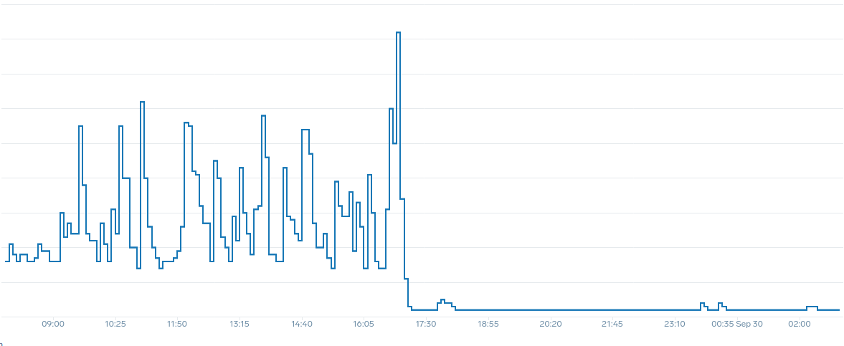
關鍵重點是 CPU 使用率只是應用程式和節點效能的一個維度。使用 CPU 使用率做為節點和應用程式的唯一運作狀態指標,會造成擴展、效能和成本方面的問題,這些都是緊密連結的概念。應用程式和節點的效能越高,您需要擴展的規模就越少,進而降低成本。
尋找和使用正確的飽和指標來擴展特定應用程式,也可讓您監控和警示該應用程式的真實瓶頸。如果略過此關鍵步驟,則報告效能問題會難以理解,如果不是不可能的話。
設定 CPU 限制
為了完整說明本章節的誤會主題,我們將說明 CPU 限制。簡言之,限制是與容器相關聯的中繼資料,容器具有每 100 毫秒重設一次的計數器。這有助於 Linux 追蹤特定容器在 100 毫秒期間內在節點上使用多少 CPU 資源。
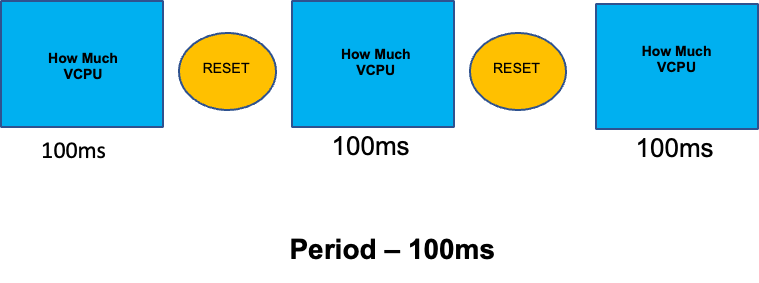
設定限制的常見錯誤是假設應用程式為單一執行緒,且僅在其「`assigned」` vCPU 上執行。在上一節中,我們了解到,CFS 不會指派核心,實際上,執行大型執行緒集區的容器會排程在盒上的所有可用 vCPU。
如果 64 個作業系統執行緒跨 64 個可用核心執行 (從 Linux 節點的角度來看),則在全部 64 個核心上執行的時間加總後,我們將使 100 毫秒期間內使用過 CPU 時間的總帳單變得相當大。由於這可能只會在垃圾回收程序期間發生,因此很容易錯過這類情況。這就是為什麼在嘗試設定限制之前,必須使用指標來確保一段時間內的正確用量。
幸運的是,我們有一個方法可以查看應用程式中所有執行緒正在使用多少 vCPU。我們將container_cpu_usage_seconds_total為此目的使用 指標。
由於限流邏輯每 100 毫秒就會發生,而此指標是每秒指標,我們將 PromQL 以符合此 100 毫秒期間。如果您想要深入了解此 PromQL 陳述式工作,請參閱下列部落格
PromQL 查詢:
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

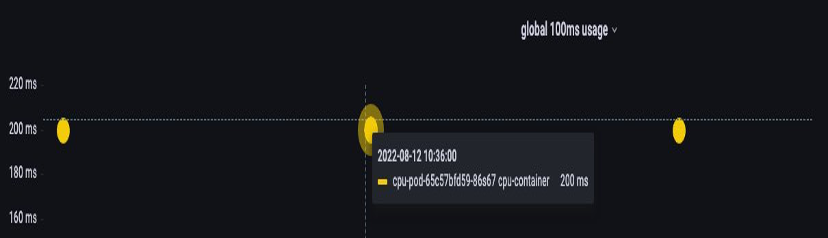
一旦我們認為我們擁有正確的價值,就可以在生產環境中設定限制。然後,需要查看我們的應用程式是否因為意外情況而受到調節。我們可以透過查看 container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10
記憶體
記憶體配置是另一個範例,其中很容易混淆 Linux CGroup 行為的 Kubernetes 排程行為。這是更細微的主題,因為 CGroup v2 在 Linux 和 Kubernetes 中處理記憶體的方式發生重大變更,而 Kubernetes 已變更其語法以反映這一點;如需更多詳細資訊,請參閱此部落格
與 CPU 請求不同,記憶體請求會在排程程序完成後未使用。這是因為我們無法像使用 CPU 一樣壓縮 CGroup v1 中的記憶體。這讓我們只具有記憶體限制,旨在完全終止 Pod 以作為記憶體洩漏的故障安全。這是全部或部分的樣式主張,但現在我們已獲得解決此問題的新方法。
首先,請務必了解,為容器設定正確數量的記憶體並不簡單。Linux 中的檔案系統將使用記憶體做為快取,以改善效能。此快取會隨著時間成長,而且很難知道有多少記憶體適合快取,但可以回收,而不會對應用程式效能造成重大影響。這通常會導致錯誤解譯記憶體用量。
具備「壓縮」記憶體的能力是 CGroup v2 背後的主要驅動因素之一。如需有關為何需要 CGroup V2 的更多歷史記錄,請參閱 Chris Down 在 LISA21 的簡報
所幸,Kubernetes 現在的概念為 memory.min和 memory.high下requests.memory。這讓我們可以選擇積極釋出此快取記憶體,以供其他容器使用。一旦容器達到記憶體上限,核心就可以積極回收該容器的記憶體,直到 設定的值為止memory.min。因此,當節點受到記憶體壓力時,可提供更多彈性。
關鍵問題會變成要memory.min設為哪個值? 這是記憶體壓力停滯指標發揮作用的地方。我們可以使用這些指標來偵測容器層級的記憶體「當機」。然後,我們可以使用 fbtaxmemory.min透過尋找此記憶體中斷來偵測 的正確值,並動態將memory.min值設定為此設定。
Summary
若要總結 區段,您可以輕鬆整合下列概念:
-
使用率和飽和度
-
具有 Kubernetes Scheduler 邏輯的 Linux 效能規則
必須特別小心,將這些概念分開。效能和擴展會在深度層級上連結。不必要的擴展會產生效能問題,進而產生擴展問題。
