本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Kubernetes 控制平面
Kubernetes 控制平面包含 Kubernetes API Server、Kubernetes Controller Manager、Scheduler 和其他 Kubernetes 運作所需的元件。這些元件的可擴展性限制會根據您在叢集中執行的內容而有所不同,但對擴展影響最大的區域包括 Kubernetes 版本、使用率和個別節點擴展。
限制工作負載和節點爆量
重要
為了避免在控制平面上達到 API 限制,您應該限制一次將叢集大小增加兩位數百分比的擴展峰值 (例如,1000 個節點到 1100 個節點,或一次 4000 到 4500 個 Pod)。
EKS 控制平面會隨著叢集的成長自動擴展,但擴展速度有所限制。當您首次建立 EKS 叢集時,控制平面將無法立即擴展到數百個節點或數千個 Pod。若要進一步了解 EKS 如何改善擴展,請參閱此部落格文章
擴展大型應用程式需要基礎設施才能調整以完全準備就緒 (例如暖機負載平衡器)。若要控制擴展速度,請確定您是根據應用程式的正確指標進行擴展。CPU 和記憶體擴展可能無法準確預測您的應用程式限制,並且在 Kubernetes Horizontal Pod Autoscaler (HPA) 中使用自訂指標 (例如每秒請求) 可能是更好的擴展選項。
若要使用自訂指標,請參閱 Kubernetes 文件
安全地擴展節點和 Pod
取代長時間執行的執行個體
定期取代節點可避免組態偏離,以及只有在延長運作時間後才會發生的問題 (例如記憶體流失緩慢),以維持叢集的運作狀態。自動化替換將為您提供節點升級和安全修補的良好程序和實務。如果定期取代叢集中的每個節點,則維護持續維護所需的個別程序就較少。
使用 Karpenter 的存留時間 (TTL) 設定,在執行個體執行一段時間後取代執行個體。自我管理節點群組可以使用 max-instance-lifetime設定自動循環節點。受管節點群組目前沒有此功能,但您可以在 GitHub 上在此處
移除未充分利用的節點
當節點沒有執行中的工作負載時,您可以使用 Kubernetes Cluster Autoscaler 中的縮減閾值搭配 --scale-down-utilization-thresholdttlSecondsAfterEmpty佈建器設定。
使用 Pod 中斷預算和安全節點關閉
從 Kubernetes 叢集移除 Pod 和節點需要控制器更新多個資源 (例如 EndpointSlices)。頻繁或太快地執行此操作可能會導致 API 伺服器限流和應用程式中斷,因為變更會傳播到控制器。Pod 中斷預算
執行 Kubectl 時使用用戶端快取
無效率地使用 kubectl 命令可以為 Kubernetes API 伺服器新增額外的負載。您應該避免重複執行 kubectl 的指令碼或自動化 (例如在 的迴圈中),或在沒有本機快取的情況下執行命令。
kubectl 具有用戶端快取,可從叢集快取探索資訊,以減少所需的 API 呼叫數量。快取預設為啟用,每 10 分鐘重新整理一次。
如果您從容器執行 kubectl 或沒有用戶端快取,您可能會遇到 API 限流問題。建議您透過掛載 來保留叢集快取--cache-dir,以避免進行不必要的 API 呼叫。
停用 kubectl 壓縮
在 kubeconfig 檔案中停用 kubectl 壓縮可減少 API 和用戶端 CPU 使用量。根據預設,伺服器會壓縮傳送至用戶端的資料,以最佳化網路頻寬。這會為每個請求在用戶端和伺服器上新增 CPU 負載,而且如果您有足夠的頻寬,停用壓縮可以減少額外負荷和延遲。若要停用壓縮,您可以使用 --disable-compression=true旗標或在 disable-compression: true kubeconfig 檔案中設定 。
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
碎片叢集自動擴展器
Kubernetes Cluster Autoscaler 已經過測試
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
API 優先順序和公平性
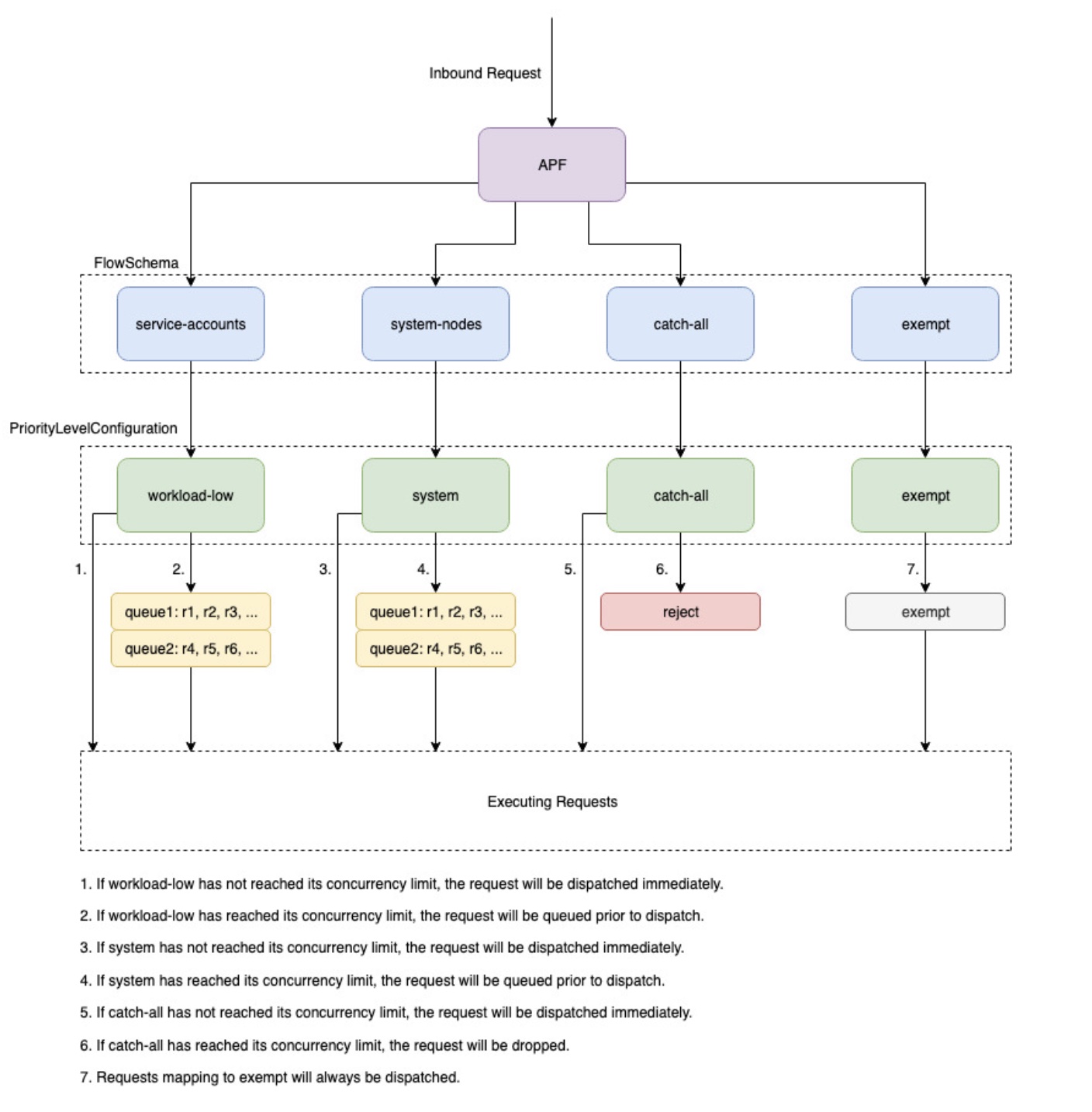
概觀
為了避免在請求增加期間超載,API Server 會限制其在特定時間可以有未完成的傳輸中請求數量。一旦超過此限制,API Server 將開始拒絕請求,並將「太多請求」的 429 HTTP 回應碼傳回給用戶端。伺服器捨棄請求並在稍後讓用戶端重試,最好對請求數量和控制平面超載沒有伺服器端限制,這可能會導致效能降低或無法使用。
Kubernetes 用來設定這些傳輸中請求如何分成不同請求類型的機制稱為 API Priority and Fairness--max-requests-inflight和 --max-mutating-requests-inflight旗標指定的值,設定其可接受之傳輸中請求的總數。EKS 會針對這些旗標使用 400 和 200 個請求的預設值,允許在指定時間總共傳送 600 個請求。不過,當它將控制平面擴展到較大的大小以回應增加的使用率和工作負載流失時,它會相應地一直增加傳輸中請求配額,直到 2000 年 (可能會有所變更)。APF 指定如何在不同的請求類型之間進一步細分這些傳輸中請求配額。請注意,EKS 控制平面具有至少 2 個 API 伺服器註冊到每個叢集的高可用性。這表示您的叢集可以處理的傳輸中請求總數是每個 kube-apiserver 的傳輸中配額集的兩倍 (如果水平擴展,則更高)。這相當於最大 EKS 叢集上每秒數千個請求。
兩種類型的 Kubernetes 物件稱為 PriorityLevelConfigurations 和 FlowSchemas,可設定在不同請求類型之間分割請求總數的方式。這些物件由 API Server 自動維護,EKS 會針對指定的 Kubernetes 次要版本使用這些物件的預設組態。PriorityLevelConfigurations 代表允許請求總數的一小部分。例如,高工作負載 PriorityLevelConfiguration 在總共 600 個請求中配置 98 個。分配給所有 PriorityLevelConfigurations 的請求總和將等於 600 (或略高於 600,因為如果指定層級被授予一小部分請求,則 API 伺服器會四捨五入)。若要檢查叢集中的 PriorityLevelConfigurations,以及分配給每個叢集的請求數量,您可以執行下列命令。以下是 EKS 1.32 的預設值:
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_nominal_limit_seats apiserver_flowcontrol_nominal_limit_seats{priority_level="catch-all"} 13 apiserver_flowcontrol_nominal_limit_seats{priority_level="exempt"} 0 apiserver_flowcontrol_nominal_limit_seats{priority_level="global-default"} 49 apiserver_flowcontrol_nominal_limit_seats{priority_level="leader-election"} 25 apiserver_flowcontrol_nominal_limit_seats{priority_level="node-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="system"} 74 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245
第二種類型的物件是 FlowSchemas。具有指定屬性集的 API Server 請求會分類在相同的 FlowSchema 下。這些屬性包括已驗證的使用者或請求的屬性,例如 API 群組、命名空間或資源。FlowSchema 也會指定這類請求應對應的 PriorityLevelConfiguration。這兩個物件一起說:「我想要這種類型的請求計入這種傳輸中的請求份額。」 當請求命中 API 伺服器時,它會檢查其每個 FlowSchemas,直到找到符合所有必要屬性的請求為止。如果多個 FlowSchemas 符合請求,API Server 將選擇具有最小相符優先順序的 FlowSchema,該優先順序指定為 物件中的屬性。
您可以使用此命令檢視 FlowSchemas 與 PriorityLevelConfigurations 的映射:
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations 可以有佇列、拒絕或豁免的類型。對於佇列和拒絕類型,會針對該優先順序層級的處理中請求數量上限強制執行限制,不過,當達到該限制時,行為會有所不同。例如,高工作負載 PriorityLevelConfiguration 使用類型 Queue,並有 98 個請求可供控制器管理員、端點控制器、排程器、eks 相關控制器以及在 kube-system 命名空間中執行的 Pod 使用。由於使用類型 Queue,API Server 會嘗試將請求保留在記憶體中,並希望處理中的請求數目在這些請求逾時之前低於 98。如果指定的請求在佇列中逾時,或已排入佇列的請求太多,API Server 只能捨棄請求並傳回用戶端 429。請注意,佇列可能會阻止請求接收 429,但會因為請求的end-to-end延遲增加而遭到權衡。
現在,請考慮對應至具有類型 Reject 之 catch-all PriorityLevelConfiguration 的所有截獲 FlowSchema。如果用戶端達到 13 個傳輸中請求的限制,API Server 將不會執行佇列,並且會立即捨棄具有 429 回應碼的請求。最後,與類型為豁免的 PriorityLevelConfiguration 對應的請求絕不會收到 429,且一律會立即分派。這用於高優先順序請求,例如 healthz 請求或來自 system:masters 群組的請求。
監控 APF 和捨棄的請求
若要確認是否因為 APF 而捨棄任何請求,apiserver_flowcontrol_rejected_requests_total可以監控 的 API 伺服器指標,以檢查受影響的 FlowSchemas 和 PriorityLevelConfigurations。例如,此指標顯示 100 個來自服務帳戶 FlowSchema 的請求因低工作負載佇列中的請求逾時而遭到捨棄:
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
若要檢查指定的 PriorityLevelConfiguration 與接收 429 秒的接近程度,或因佇列而經歷增加的延遲,您可以比較並行限制與使用中的並行之間的差異。在此範例中,我們有 100 個請求的緩衝區。
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_nominal_limit_seats.*workload-low' apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_executing_seats.*workload-low' apiserver_flowcontrol_current_executing_seats{flow_schema="service-accounts",priority_level="workload-low"} 145
若要檢查指定的 PriorityLevelConfiguration 是否遇到佇列,但不一定捨棄請求,apiserver_flowcontrol_current_inqueue_requests可以參考 的 指標:
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
其他有用的 Prometheus 指標包括:
-
apiserver_flowcontrol_dispatched_requests_total
-
apiserver_flowcontrol_request_execution_seconds
-
apiserver_flowcontrol_request_wait_duration_seconds
如需 APF 指標
防止捨棄的請求
變更工作負載以防止 429
當 APF 因指定的 PriorityLevelConfiguration 而捨棄請求超過其允許的最大傳輸中請求數量時,受影響 FlowSchemas 中的用戶端可以減少在指定時間執行的請求數量。這可以透過減少在 429 個期間內提出的請求總數來完成。請注意,長時間執行的請求,例如昂貴的清單呼叫,特別有問題,因為它們在執行的整個期間都算是傳輸中請求。減少這些昂貴請求的數量或最佳化這些清單呼叫的延遲 (例如,透過減少每個請求擷取的物件數量或使用監看請求切換到 ),有助於減少指定工作負載所需的並行總數。
變更 APF 設定以防止 429
警告
只有在您知道正在做什麼時,才能變更預設 APF 設定。設定錯誤的 APF 設定可能會導致 API 伺服器請求遭到捨棄,並造成嚴重的工作負載中斷。
防止捨棄請求的另一種方法是變更安裝在 EKS 叢集上的預設 FlowSchemas 或 PriorityLevelConfigurations。EKS 會為指定 Kubernetes 次要版本安裝 FlowSchemas 和 PriorityLevelConfigurations 的上游預設設定。如果修改,API Server 會自動將這些物件調整回其預設值,除非物件上的下列註釋設定為 false:
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
在高階,APF 設定可以修改為:
-
將更多傳輸中容量分配給您關心的請求。
-
隔離可能讓其他請求類型容量不足的非必要或昂貴請求。
這可以透過變更預設 FlowSchemas 和 PriorityLevelConfigurations 或建立這些類型的新物件來完成。運算子可以增加相關 PriorityLevelConfigurations 物件的 assuredConcurrencyShares 值,以增加配置的傳輸中請求部分。此外,如果應用程式可以處理在發出請求之前排入佇列而導致的額外延遲,則可以增加可在指定時間排入佇列的請求數量。
或者,您可以建立客戶工作負載特有的新 FlowSchema 和 PriorityLevelConfigurations 物件。請注意,將更多 assuredConcurrencyShares 配置到現有的 PriorityLevelConfigurations 或新的 PriorityLevelConfigurations 將導致其他儲存貯體可以處理的請求數量減少,因為整體限制將保持為每個 API 伺服器 600 個傳輸中。
變更 APF 預設值時,應在非生產叢集上監控這些指標,以確保變更設定不會導致意外的 429s:
-
apiserver_flowcontrol_rejected_requests_total應監控所有 FlowSchemas 的 指標,以確保沒有任何儲存貯體開始捨棄請求。 -
apiserver_flowcontrol_current_executing_seats應比較apiserver_flowcontrol_nominal_limit_seats和 的值,以確保使用中的並行不會違反該優先順序層級的限制。
定義新 FlowSchema 和 PriorityLevelConfiguration 的一個常見使用案例是用於隔離。假設我們想要隔離長期執行的清單事件呼叫,從 Pod 到他們自己的請求份額。這將防止來自使用現有服務帳戶 FlowSchema 的 Pod 的重要請求接收 429s 並被請求容量綁定。請記住,傳輸中請求的總數有限,不過,此範例顯示可以修改 APF 設定,以便更好地分割指定工作負載的請求容量:
隔離清單事件請求的 FlowSchema 物件範例:
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
此 FlowSchema 會擷取服務帳戶在預設命名空間中發出的所有事件呼叫清單。
-
比對優先順序 8000 低於現有服務帳戶 FlowSchema 所使用的 9000 值,因此這些清單事件呼叫將比對 list-events-default-service-accounts,而不是 service-accounts。
-
我們使用全部的 PriorityLevelConfiguration 來隔離這些請求。此儲存貯體僅允許這些長時間執行的清單事件呼叫使用 13 個處理中的請求。一旦 Pod 嘗試同時發出超過 13 個請求,就會開始收到 429 個請求。
擷取 API 伺服器中的資源
從 API 伺服器取得資訊是任何大小叢集的預期行為。隨著您擴展叢集中的資源數量,請求頻率和資料量可能會很快成為控制平面的瓶頸,並導致 API 延遲和速度變慢。根據延遲的嚴重性,如果不小心,會導致非預期的停機時間。
了解您的請求,以及避免這類問題的第一步有多頻繁。以下是根據擴展最佳實務限制查詢數量的指引。本節中的建議會從已知可擴展最佳選項開始依序提供。
使用共用資訊提供者
建置與 Kubernetes API 整合的控制器和自動化時,您通常需要從 Kubernetes 資源取得資訊。如果您定期輪詢這些資源,可能會對 API 伺服器造成大量負載。
使用來自 client-go 程式庫的資訊提供者
控制器應避免在沒有標籤和欄位選擇器的情況下輪詢整個叢集的資源,尤其是在大型叢集中。每個未篩選的輪詢都需要用戶端透過 API 伺服器從等化傳送許多不必要的資料。透過根據標籤和命名空間進行篩選,您可以減少 API 伺服器需要執行的工作量,以完整記錄傳送至用戶端的請求和資料。
最佳化 Kubernetes API 用量
使用自訂控制器或自動化呼叫 Kubernetes API 時,請務必將呼叫限制為僅需要的資源。如果沒有限制,可能會在 API 伺服器上造成不需要的載入和 等。
建議您盡可能使用 Watch 引數。沒有引數時,預設行為是列出物件。若要使用監看而非清單,您可以將 附加?watch=true到 API 請求的結尾。例如,若要使用監看功能取得預設命名空間中的所有 Pod:
/api/v1/namespaces/default/pods?watch=true
如果您要列出物件,您應該限制要列出的範圍和傳回的資料量。您可以透過將limit=500引數新增至請求來限制傳回的資料。fieldSelector 引數和/namespace/路徑對於確保您的清單視需要縮小範圍很有用。例如,若要僅列出預設命名空間中執行中的 Pod,請使用下列 API 路徑和引數。
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
或列出所有執行 的 Pod:
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
限制監看呼叫或列出物件的另一個選項是使用 resourceVersions ,您可以在 Kubernetes 文件中閱讀這些內容resourceVersion 引數,您將會收到可用的最新版本,該版本需要對資料庫而言最昂貴且最慢的刻板讀取。resourceVersion 取決於您嘗試查詢的資源,可在 metadata.resourseVersion 欄位中找到。如果使用監看呼叫,而不是只列出呼叫,也建議這樣做
有一個特殊resourceVersion=0的可用項目,將從 API 伺服器快取傳回結果。這可以減少刻印負載,但不支援分頁。
/api/v1/namespaces/default/pods?resourceVersion=0
建議將具有 resourceVersion 的 watch 設定為從先前清單或 watch 接收到的最新已知值。這會在 client-go 中自動處理。但是,如果您使用其他語言的 k8s 用戶端,建議您再次檢查。
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
如果您在沒有任何引數的情況下呼叫 API,它將是 API 伺服器和 等的最密集資源。此呼叫將取得所有命名空間中的所有 Pod,而不會分頁或限制範圍,並且需要從 等方讀取規定人數。
/api/v1/pods
防止 DaemonSet 雷擊雜草
DaemonSet 可確保所有 (或部分) 節點執行 Pod 的副本。當節點加入叢集時, daemonset-controller 會為這些節點建立 Pod。當節點離開叢集時,會收集這些 Pod。刪除 DaemonSet 會清除其建立的 Pod。
DaemonSet 的一些典型用途如下:
-
在每個節點上執行叢集儲存協助程式
-
在每個節點上執行日誌集合協助程式
-
在每個節點上執行節點監控協助程式
在具有數千個節點的叢集上,建立新的 DaemonSet、更新 DaemonSet 或增加節點數量可能會導致在控制平面上放置高負載。如果 DaemonSet Pod 在 Pod 啟動時發出昂貴的 API 伺服器請求,可能會導致大量並行請求在控制平面上使用大量資源。
在正常操作中,您可以使用 RollingUpdate來確保逐步推出新的 DaemonSet Pod。透過RollingUpdate更新策略,在您更新 DaemonSet 範本之後,控制器會終止舊的 DaemonSet Pod,並以受控方式自動建立新的 DaemonSet Pod。在整個更新過程中,每個節點上最多都會執行一個 DaemonSet Pod。您可以將 maxUnavailable設為 1、 maxSurge 設為 0,以及 minReadySeconds 設為 60,以執行逐步推展。如果您未指定更新策略,Kubernetes 會預設為以 RollingUpdate maxUnavailable 1、0 和 maxSurge 0 minReadySeconds建立 。
minReadySeconds: 60
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
如果已建立 DaemonSet 且在所有節點上具有預期的 Pod 數量,則 RollingUpdate可確保逐步推出新的 DaemonSet Ready Pod。在某些情況下,可能會在RollingUpdate策略未涵蓋的特定條件下產生雜湊問題。
防止在 DaemonSet 建立時產生雜湊雜湊
根據預設,無論RollingUpdate組態為何,kube-controller-manager 中的 daemonset-controller 都會在您建立新的 DaemonSet 時,同時為所有相符節點建立 Pod。若要在建立 DaemonSet 後強制逐步推展 Pod,您可以使用 NodeSelector或 NodeAffinity。這將建立符合零節點的 DaemonSet,然後您可以逐漸更新節點,使其有資格以受控速率從 DaemonSet 執行 Pod。您可以遵循以下方法:
-
將標籤新增至 的所有節點
run-daemonset=false。
kubectl label nodes --all run-daemonset=false
-
使用
NodeAffinity設定建立您的 DaemonSet,以符合任何沒有run-daemonset=false標籤的節點。一開始,這將導致您的 DaemonSet 沒有對應的 Pod。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
以受控速率從節點移除
run-daemonset=false標籤。您可以使用此 bash 指令碼做為範例:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
或者,從 DaemonSet 物件中移除
NodeAffinity設定。請注意,這也會觸發RollingUpdate,並逐漸取代所有現有的 DaemonSet Pod,因為 DaemonSet 範本已變更。
防止節點橫向擴展上的雜湊雜湊
與 DaemonSet 建立類似,快速建立新節點可能會導致大量 DaemonSet Pod 同時啟動。您應該以受控速率建立新的節點,讓控制器以相同的速率建立 DaemonSet Pod。如果無法這麼做,您可以使用 讓新節點最初不符合現有 DaemonSet 的資格NodeAffinity。接下來,您可以逐步將標籤新增至新節點,讓 daemonset-controller 以受控速率建立 Pod。您可以遵循以下方法:
-
將標籤新增至 的所有現有節點
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
使用
NodeAffinity設定更新您的 DaemonSet,以符合任何具有run-daemonset=true標籤的節點。請注意,這也會觸發 ,RollingUpdate並逐漸取代所有現有的 DaemonSet Pod,因為 DaemonSet 範本已變更。在進入下一個步驟之前RollingUpdate,您應該等待 完成。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
在叢集中建立新的節點。請注意,這些節點不會有
run-daemonset=true標籤,因此 DaemonSet 不會符合這些節點。 -
以受控速率將
run-daemonset=true標籤新增至新節點 (目前沒有run-daemonset標籤)。您可以使用此 bash 指令碼做為範例:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
或者,從 DaemonSet 物件移除
NodeAffinity設定,並從所有節點移除run-daemonset標籤。
防止 DaemonSet 更新上的雜湊雜湊
RollingUpdate 政策只會遵守 之 DaemonSet Pod maxUnavailable的設定Ready。如果 DaemonSet NotReady 僅有 Pod NotReady 或大量 Pod,且您更新其範本,則 daemonset-controller 會同時為任何 Pod 建立新的 NotReady Pod。如果 Pod NotReady 數量很大,例如 Pod 持續當機循環或無法提取映像,這可能會導致雷擊問題。
若要在更新 DaemonSet 且有 Pod 時強制逐步推出 NotReady Pod,您可以暫時將 DaemonSet 上的更新策略從 變更為 RollingUpdate OnDelete。使用 OnDelete更新 DaemonSet 範本後,控制器會在您手動刪除舊的 Pod 之後建立新的 Pod,讓您可以控制新 Pod 的推出。您可以遵循以下方法:
-
檢查您的 DaemonSet
NotReady中是否有任何 Pod。 -
如果否,您可以安全地更新 DaemonSet 範本,且
RollingUpdate策略將確保逐步推出。 -
如果是,您應該先更新 DaemonSet 以使用
OnDelete策略。
updateStrategy: type: OnDelete
-
接著,使用所需的變更更新您的 DaemonSet 範本。
-
在此更新之後,您可以透過以受控速率發出刪除 Pod 請求來刪除舊的 DaemonSet Pod。您可以使用此 bash 指令碼做為範例,其中 DaemonSet 名稱在 kube-system 命名空間中為 fluentd-elasticsearch:
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
最後,您可以將 DaemonSet 更新回先前的
RollingUpdate策略。
