本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
適用於 Ranger 與 Amazon EMR 整合的 Apache Spark 外掛程式
Amazon EMR 整合了 EMR RecordServer,可為 SparkSQL 提供精細分級的存取控制。EMR 的 RecordServer 是一個具特殊權限的程序,在啟用 Apache Ranger 的叢集的所有節點上執行。在 Spark 驅動程式或執行程式執行 SparkSQL 陳述式時,所有中繼資料和資料請求都會通過 RecordServer。若要進一步了解 EMR RecordServer,請參閱 搭配 Apache Ranger 使用的 Amazon EMR 元件 頁面。
支援的功能
| SQL 陳述式/Ranger 動作 | STATUS | 支援的 EMR 版本 |
|---|---|---|
|
SELECT |
支援 |
從 5.32 開始 |
|
SHOW DATABASES |
支援 |
從 5.32 開始 |
|
SHOW COLUMNS |
支援 |
從 5.32 開始 |
|
SHOW TABLES |
支援 |
從 5.32 開始 |
|
SHOW TABLE PROPERTIES |
支援 |
從 5.32 開始 |
|
DESCRIBE TABLE |
支援 |
從 5.32 開始 |
|
INSERT OVERWRITE |
支援 |
從 5.34 和 6.4 開始 |
| INSERT INTO | 支援 | 從 5.34 和 6.4 開始 |
|
ALTER TABLE |
支援 |
從 6.4 開始 |
|
CREATE TABLE |
支援 |
從 5.35 和 6.7 開始 |
|
CREATE DATABASE |
支援 |
從 5.35 和 6.7 開始 |
|
DROP TABLE |
支援 |
從 5.35 和 6.7 開始 |
|
DROP DATABASE |
支援 |
從 5.35 和 6.7 開始 |
|
DROP VIEW |
支援 |
從 5.35 和 6.7 開始 |
|
CREATE VIEW |
不支援 |
在使用 SparkSQL 時支援下列功能:
-
可以在資料庫、資料表和資料欄層級建立對 Hive 中繼存放區內的資料表和政策的精細分級的存取控制。
-
Apache Ranger 政策可以包括對使用者和群組的授權政策和拒絕政策。
-
稽核事件提交至 CloudWatch Logs。
重新部署服務定義以使用 INSERT、ALTER 或 DDL 陳述式
注意
從 Amazon EMR 6.4 開始,您可以將 Spark SQL 與陳述式搭配使用:INSERT INTO、INSERT OVERWRITE 或 ALTER TABLE。從 Amazon EMR 6.7 開始,您可以使用 Spark SQL 建立或捨棄資料庫和資料表。如果您在 Apache Ranger 伺服器上已有安裝並部署了 Apache Spark 服務定義,請使用下列程式碼重新部署服務定義。
# Get existing Spark service definition id calling Ranger REST API and JSON processor curl --silent -f -u<admin_user_login>:<password_for_ranger_admin_user>\ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id # Download the latest Service definition wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json # Update the service definition using the Ranger REST API curl -u<admin_user_login>:<password_for_ranger_admin_user>-X PUT -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<Spark service definition id from step 1>'
安裝服務定義
安裝 EMR 的 Apache Spark 服務定義需要設定 Ranger Admin 伺服器。請參閱 設定 Ranger Admin 伺服器以與 Amazon EMR 整合。
請遵循下列步驟安裝 Apache Spark 服務定義:
步驟 1:透過 SSH 連接到 Apache Ranger Admin 伺服器
例如:
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal
步驟 2:下載服務定義和 Apache Ranger Admin 伺服器外掛程式
在暫時目錄中,下載服務定義。Ranger 2.x 版支援此服務定義。
mkdir /tmp/emr-spark-plugin/ cd /tmp/emr-spark-plugin/ wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
步驟 3:安裝適用於 Amazon EMR 的 Apache Spark 外掛程式
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
步驟 4:註冊適用於 Amazon EMR 的 Apache Spark 服務定義
curl -u *<admin users login>*:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef'
如果此命令成功執行,您會在 Ranger Admin UI 中看到一個稱為 "AMAZON-EMR-SPARK" 的新服務,如下列影像所示 (顯示的是 Ranger 2.0 版)。
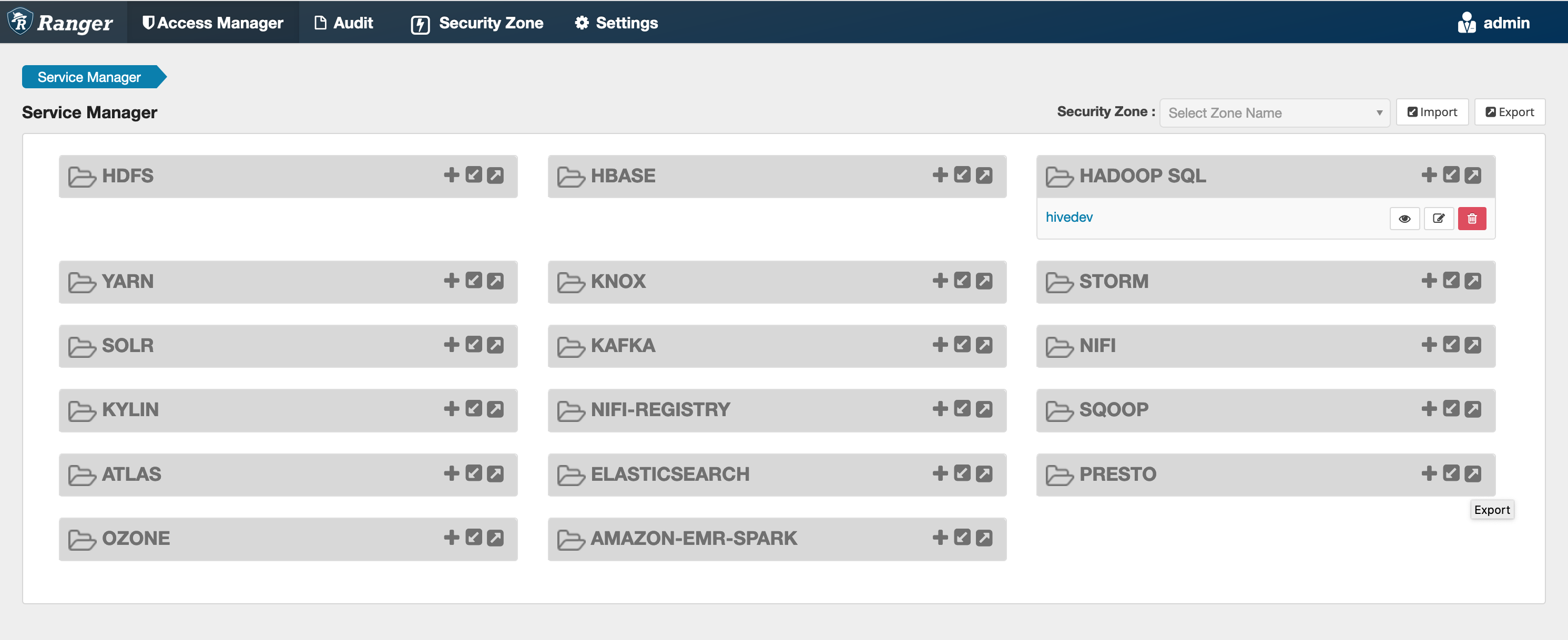
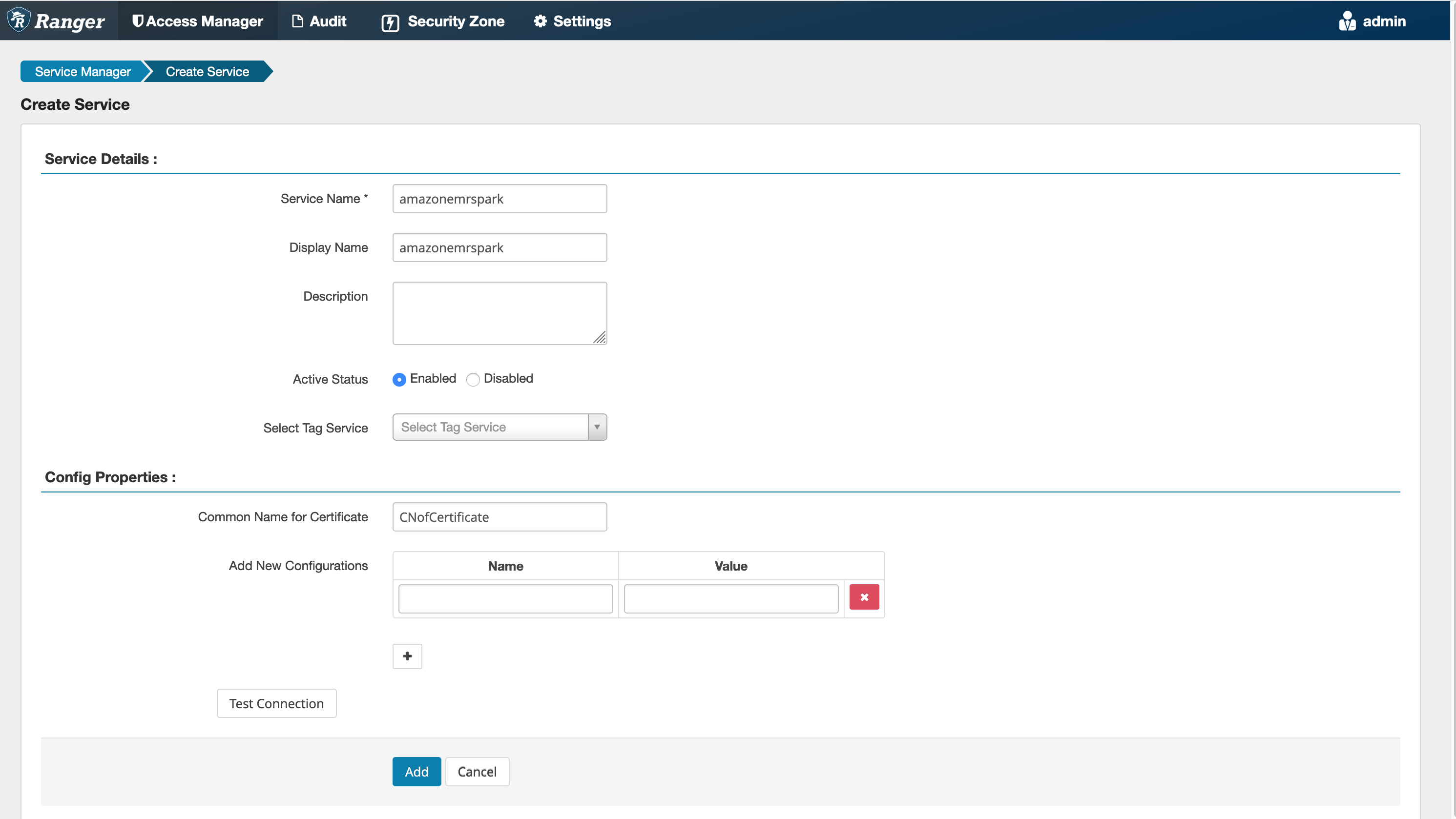
步驟 5:建立 AMAZON-EMR-SPARK 應用程式的執行個體
服務名稱 (如果顯示):將使用的服務名稱。建議的值為 amazonemrspark。請記下此服務名稱,因為建立 EMR 安全組態時需要此名稱。
顯示名稱:要為此執行個體顯示的名稱。建議的值為 amazonemrspark。
憑證的通用名稱:憑證內的 CN 欄位用於從用戶端外掛程式連接至管理伺服器。此值必須與為外掛程式建立的 TLS 憑證中的 CN 欄位相符。
注意
此外掛程式的 TLS 憑證應已在 Ranger Admin 伺服器上的信任存放區中註冊。如需詳細資訊,請參閱Apache Ranger 與 Amazon EMR 整合的 TLS 憑證。
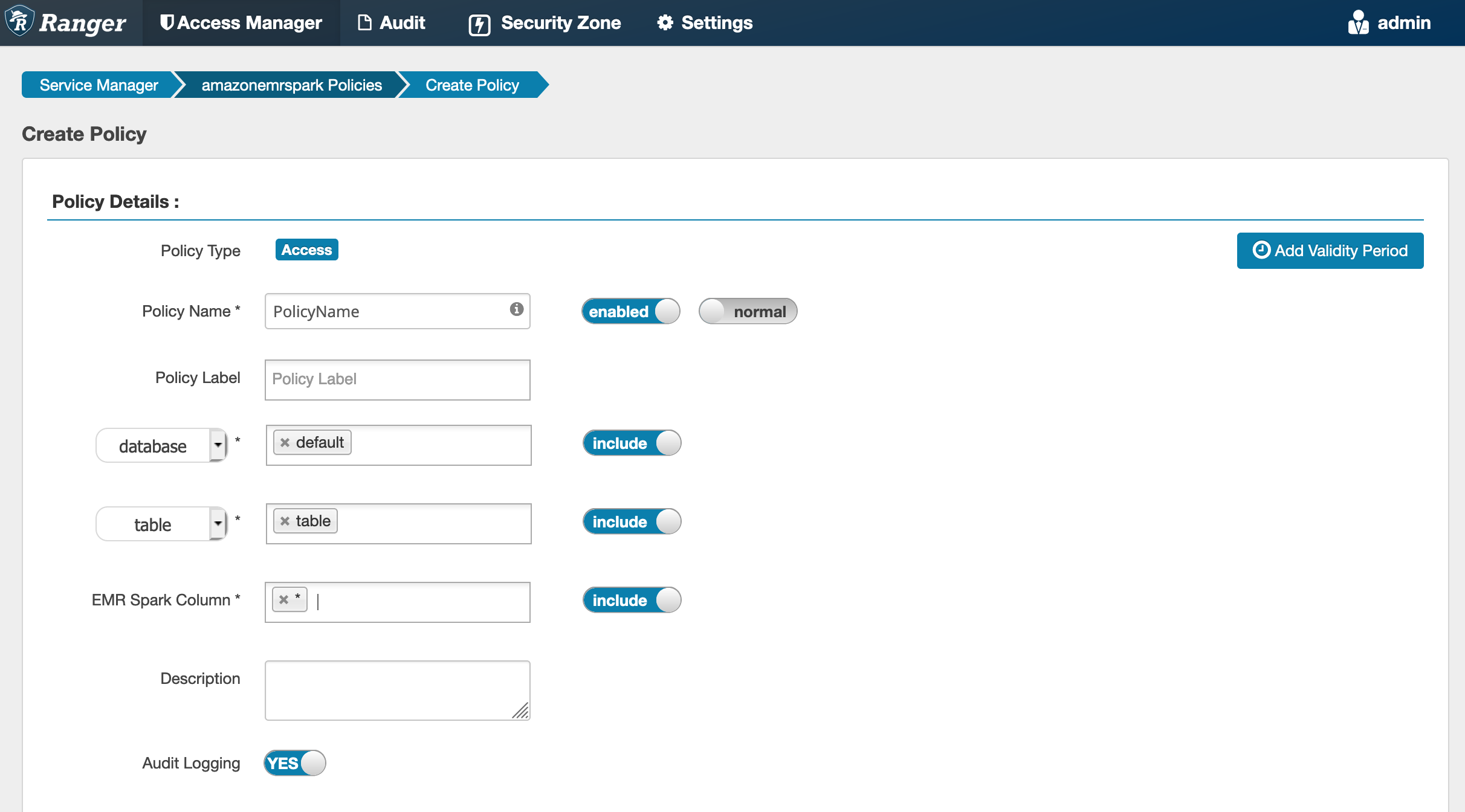
建立 SparkSQL 政策
建立新政策時,要填入的欄位如下:
政策名稱:此政策的名稱。
政策標籤:您可以放在此政策上的標籤。
資料庫:此政策套用的資料庫。萬用字元 "*" 代表所有資料庫。
資料表:此政策套用的資料表。萬用字元 "*" 代表所有資料表。
EMR Spark 資料欄:此政策套用的資料欄。萬用字元 "*" 代表所有資料欄。
描述:此政策的描述。
若要指定使用者和群組,請在下方輸入使用者和群組以授予許可。您也可以為允許條件和拒絕條件指定排除。
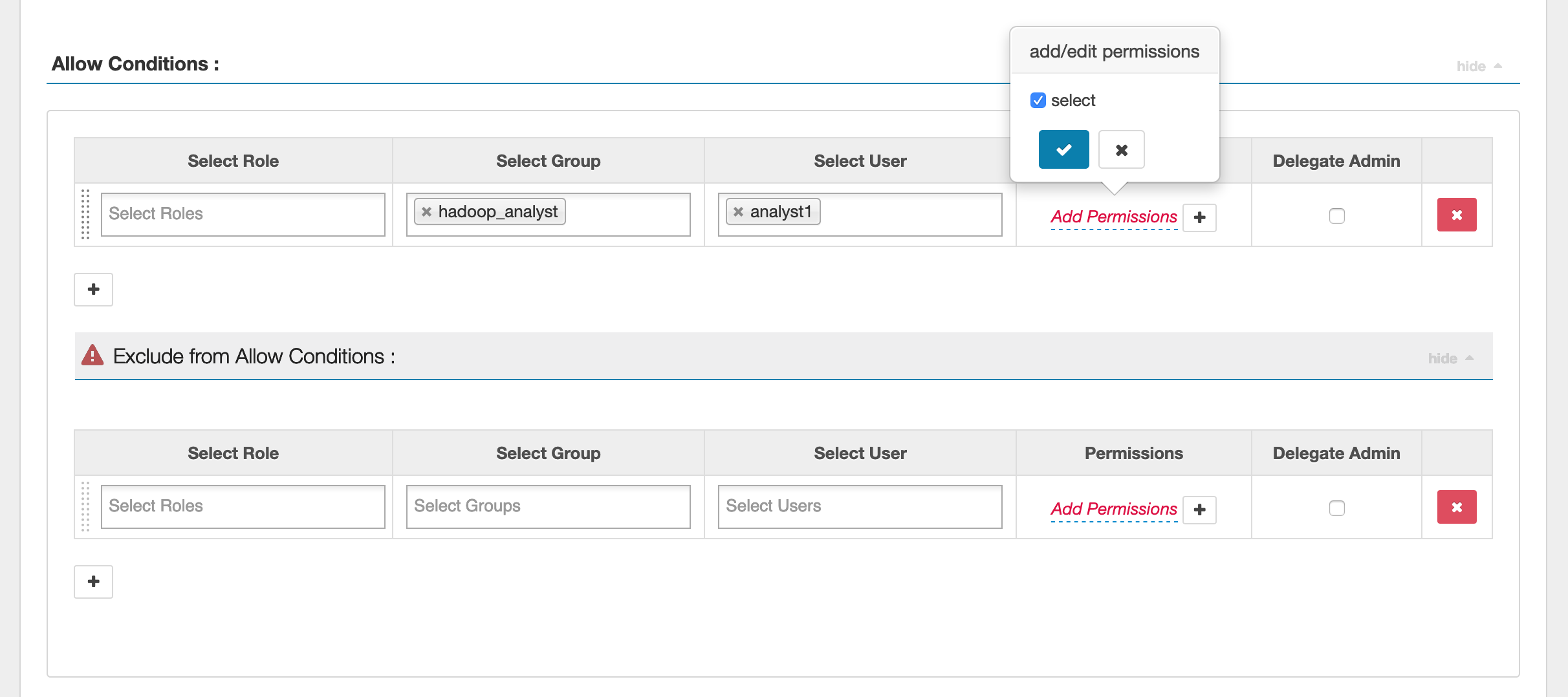
在指定允許和拒絕條件之後,按一下儲存。
考量事項
EMR 叢集內的每個節點都必須能夠連接至連接埠 9083 上的主要節點。
限制
以下是 Apache Spark 外掛程式的目前限制:
-
EMR RecordServer 將一律連接至在 Amazon EMR 叢集上執行的 HMS。視需要將 HMS 設定為連接至遠端模式。您不應將設定值放在 Apache Spark Hive-site.xml 組態檔案內。
-
使用 CSV 或 Avro 上的 Spark 資料來源建立的資料表無法使用 EMR RecordServer 讀取。使用 Hive 建立和寫入資料,並使用 Record 讀取。
-
不支援 Delta Lake、Hudi 和 Iceberg 資料表。
-
使用者必須具有預設資料庫的存取權。這是 Apache Spark 的需求。
-
Ranger Admin 伺服器不支援自動完成。
-
適用於 Amazon EMR 的 SparkSQL 外掛程式不支援資料列篩選條件或資料遮罩。
-
將 ALTER TABLE 與 Spark SQL 搭配使用時,分割區位置必須是資料表位置的子目錄。不支援將資料插入到分割區位置與資料表位置不同的分割區。
