本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
HBase on Amazon S3 (Amazon S3 儲存模式)
當您在 Amazon EMR 5.2.0 版或更新版本上執行 HBase 時,即可啟用 HBase on Amazon S3,其可提供下列優勢:
HBase 根目錄儲存在 Amazon S3 中,包括 HBase 儲存檔案和資料表中繼資料。這些資料在叢集外是持久性的,可在 Amazon EC2 可用區域之間使用,並且不需使用快照或其他方法進行復原。
在 Amazon S3 中儲存檔案時,您可以使用 HDFS 內的 3 倍複寫功能,並依據運算需求 (而非資料需求) 來設定 Amazon EMR 叢集規模。
使用 Amazon EMR 5.7.0 版或更新版本時,您能夠設定僅供讀取複本叢集,藉此維護 Amazon S3 中的唯讀資料複本。您可以在主叢集無法使用時,從僅供讀取複本叢集存取資料來同時執行讀取操作。
在 Amazon EMR 6.2.0 至 7.3.0 版中,持久性 HFile 追蹤使用稱為 的 HBase 系統資料表
hbase:storefile,直接追蹤用於讀取操作的 HFile 路徑。此功能預設為啟用,無需執行手動遷移。在高於 7.3.0 的版本中,會使用檔案追蹤器追蹤 HFile 路徑,將 HFile 路徑直接儲存在儲存體目錄中的中繼檔案中。
注意
使用 7.4.0 之前 Amazon EMR 版本且正在遷移至 EMR-7.4.0 及更新版本的使用者,請參閱從先前的 HBase 版本遷移,並遵循可用的升級文件以確保順利轉換。
下圖顯示與 HBase on Amazon S3 相關的 HBase 元件。
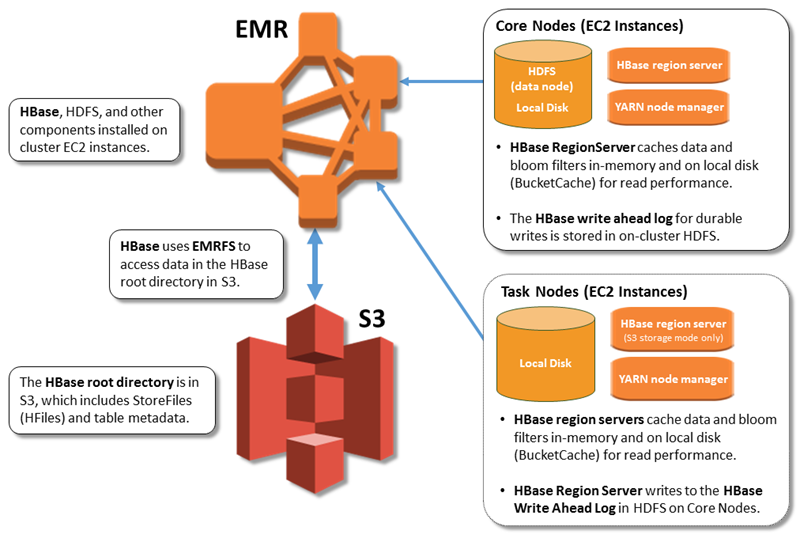
啟用 HBase on Amazon S3
您可以使用 Amazon EMR 主控台、 或 Amazon EMR API 在 Amazon S3 上啟用 HBase。 AWS CLI組態在叢集建立期間是一個選項。如果您選擇使用主控台,請前往 Advanced options (進階選項) 選擇該設定。若您選擇使用 AWS CLI,請利用 --configurations 選項來提供 JSON 組態物件。組態物件屬性指定了 Amazon S3 中的儲存模式的和根目錄位置。您指定的 Amazon S3 位置應與 Amazon EMR 叢集的所在區域相同。一次只能有一個作用中的叢集可以在 Amazon S3 中使用相同的 HBase 根目錄。如需使用 的主控台步驟和詳細的 create-cluster 範例 AWS CLI,請參閱 使用 HBase 建立叢集。範例組態物件顯示於以下的 JSON 片段中。
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
注意
如果您使用 Amazon S3 儲存貯體作為 HBase 的 rootdir,則必須在 Amazon S3 URI 的結尾加上斜線。例如,您必須使用 "hbase.rootdir: s3://amzn-s3-demo-bucket/" 而不是 "hbase.rootdir: s3://amzn-s3-demo-bucket",以避免問題。
使用僅供讀取複本叢集
在您使用 HBase on Amazon S3 設定主叢集後,您可以建立和設定僅供讀取複本叢集,該叢集提供唯讀存取至相同資料以做為主叢集。如果主叢集無法使用,而您需要同時存取查詢資料或不中斷存取時,這非常有用。Amazon EMR 5.7.0 版及更新版本提供僅供讀取複本功能。
主叢集和僅供讀取複本叢集是以相同方法設定,但僅有一處重要的不同。兩個都指向相同的 hbase.rootdir 位置。不過,僅供讀取複本叢集的 hbase 分類包含了 "hbase.emr.readreplica.enabled":"true" 屬性。
僅供讀取複本叢集專為唯讀操作而設計,不應對其執行手動壓縮或寫入動作。對於 7.4.0 之前的 Amazon EMR 版本,建議您在啟用僅供讀取複本功能時停用僅供讀取複本叢集上的壓縮。此預防措施是必要的,因為在主要叢集上啟用持久性 HFile 追蹤功能時,僅供讀取複本叢集可能會壓縮系統資料表,進而可能導致主要叢集上的 FileNotFoundException。在僅供讀取複本叢集上停用壓縮可防止主要叢集和僅供讀取複本叢集之間的資料不一致。
例如,假設 主題稍早所示主要叢集的 JSON 分類,7.4.0 之前 EMR 版本的僅供讀取複本叢集組態如下:
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
對於 7.3.0 之後的 Amazon EMR 版本,我們現在使用 存放檔案追蹤功能,因此不需要停用壓縮。
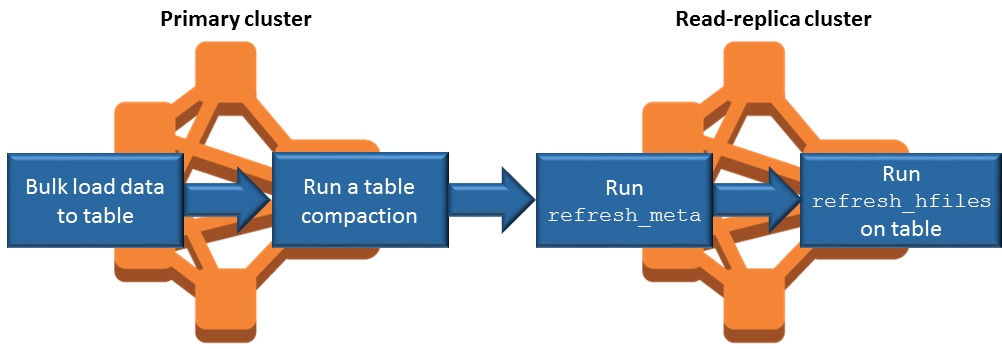
在您新增資料時同步僅供讀取複本
由於僅供讀取複本使用主叢集寫入至 Amazon S3 的 HBase StoreFiles 和中繼資料,因此僅供讀取複本的狀態僅與 Amazon S3 資料儲存一樣新。當您寫入資料時,以下指導有助於降低主叢集和僅供讀取複本之間的時間延遲。
盡可能在主叢集上大量載入資料。如需詳細資訊,請參閱 Apache HBase 文件中的大量載入
。 在新增資料後,將儲存檔案寫入至 Amazon S3 的排清應盡快進行。手動排清或調整排清設定以盡量減少延遲。
如果壓縮可能會自動執行,請執行手動壓縮以避免壓縮觸發時間不一致。
在僅供讀取複本叢集上,當任何中繼資料變更時 (例如,當發生 HBase 區域分割或壓縮,或新增或移除資料表時),請執行
refresh_meta命令。在僅供讀取複本叢集上,當表格中新增或變更記錄時,請執行
refresh_hfiles命令。
持久性 HFile 追蹤
持久性 HFile 追蹤使用稱為 hbase:storefile 的 HBase 系統資料表,來直接追蹤用於讀取操作的 HFile 路徑。在其他資料新增至 HBase 時,新的 HFile 路徑會新增至資料表。這消除了重新命名操作作為關鍵寫入路徑 HBase 操作中的遞交機制,並透過從 hbase:storefile 系統資料表而不是檔案系統目錄清單中讀取來改善開啟 HBase 區域時的復原時間。此功能預設為在 Amazon EMR 6.2.0 版至 7.3.0 版上啟用,不需要任何手動遷移步驟。
注意
使用 HBase storefile 系統資料表的持久性 HFile 追蹤不支援 HBase 區域複寫功能。如需有關 HBase 區域複寫的詳細資訊,請參閱時間軸一致性高可用讀取
停用持久性 HFile 追蹤
持久性 HFile 追蹤預設為從 Amazon EMR 6.2.0 版開始啟用。若要停用持久性 HFile 追蹤,請在啟動叢集時指定下列組態覆寫:
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
注意
在重新設定 Amazon EMR 叢集時,必須更新所有執行個體群組。
手動同步 Storefile 資料表
建立新的 HFile 執行個體時,storefile 資料表會保持在最新狀態。不過,如果 storefile 資料表因任何原因與資料檔案不同步,則以下命令可用於手動同步資料:
同步線上區域的 storefile 資料表:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
同步離線區域的 storefile 資料表:
移除 storefile 資料表 znode。
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]指派區域 (在 'hbase shell' 中執行)。
hbase cli> assign '<region name>'如果指派失敗。
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
擴展 Storefile 資料表
依預設,storefile 資料表分成四個區域。如果 storefile 資料表仍處於繁重的寫入負載下,則可以手動進一步分割此資料表。
若要分割特定的熱區域,請使用下列命令 (在 'hbase shell' 中執行)。
hbase cli> split '<region name>'
若要分割資料表,請使用下列命令 (在 'hbase shell' 中執行)。
hbase cli> split 'hbase:storefile'
存放檔案追蹤
根據預設,我們使用 FileBasedStoreFileTracker 實作。此實作會直接在存放區目錄中建立新的檔案,避免需要重新命名操作。它會將遞交的 hfile 執行個體清單保留在記憶體中,並以每個儲存目錄中的中繼檔案為後盾。每當遞交新的 hfile 時,指定存放區中追蹤的檔案清單都會更新,並使用清單內容寫入新的中繼檔案,並捨棄先前的中繼檔案,其中包含過期的清單。如需存放檔案追蹤的詳細資訊,請參閱 Apache HBase 參考指南中的存放檔案追蹤
FileBasedStoreFile 追蹤器實作預設為啟用,從 Amazon EMR 7.4.0 版開始:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker" }
若要停用 FileBasedStoreFileTracker 實作,請在啟動叢集時指定下列組態覆寫:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker" }
注意
在重新設定 Amazon EMR 叢集時,必須更新所有執行個體群組。
營運考量事項
HBase 區域伺服器使用 BlockCache 將資料讀取存放在記憶體中,而 BucketCache 將資料讀取存放在本機磁碟上。此外,區域伺服器使用 MemStore 儲存記憶體中的資料寫入,並使用預先寫入日誌將資料寫入 HDFS,然後才將資料寫入至 Amazon S3 中的 HBase StoreFiles。叢集的讀取效能與從內部記憶體或磁碟快取擷取記錄的頻率有關。快取遺失是由於該記錄是從 Amazon S3 中的 StoreFile 中讀取的,比從 HDFS 讀取有更高的延遲和更高的標準偏差。此外,Amazon S3 所能達成的最大請求率低於本機快取的最大請求率,因此快取資料對於大量讀取的工作負載可能很重要。如需有關 Amazon S3 效能的詳細資訊,請參閱《Amazon Simple Storage Service 使用者指南》中的效能優化。
為了改善效能,我們建議您在 EC2 執行個體儲存體中盡可能對資料集多進行緩存。由於 BucketCache 使用區域伺服器的 EC2 執行個體儲存體,您可以選擇使用足夠執行個體儲存體的 EC2 執行個體類型,並新增 Amazon EBS 儲存以適應所需的快取大小。您也可以使用 hbase.bucketcache.size 屬性在附加的執行個體存放區與 EBS 磁碟區增加 BucketCache 規模。預設設定為 8,192 MB。
對於寫入,MemStore 排清頻率和主次要壓縮過程中存在的 StoreFiles 數量,可能會大幅地提高區域伺服器回應時間。如需最佳效能,請考慮增加 MemStore 排清與 HRegion 區塊乘數大小,如此會增加主要壓縮之間的經過時間,但若您使用僅供讀取複本,則會增加一致性的延遲。在某些情況下,使用較大的檔案區塊規模 (但小於 5 GB) 可以在 EMRFS 中觸發 Amazon S3 分段上傳功能,從而獲得更好的效能。Amazon EMR 的區塊大小預設為 128 MB。如需詳細資訊,請參閱HDFS 組態。我們很少看到超過 1 GB 區塊大小的客戶,同時透過排清和壓縮對效能進行基準測試。此外,當需要壓縮更少的 StoreFiles 時,HBase 壓縮和區域伺服器能夠以最佳方式執行。
由於大型目錄需要重新命名,資料表可能需要很長的時間才能在 Amazon S3 上刪除。考慮停用表格,而不是刪除。
這是一個會清除舊 WAL 檔案和存放檔案的 HBase 清理工具程序。Amazon EMR 5.17.0 版及更新版本會全面啟用該清理工具,而您也能使用下列組態屬性來控制清理工具的行為。
| 組態屬性 | 預設值 | 描述 |
|---|---|---|
|
|
1 |
配置為清除過期大型 HFiles 的執行緒數量。 |
|
|
1 |
配置為清除過期小型 HFiles 的執行緒數量。 |
|
|
設定為所有可用核心的四分之一。 |
用來掃描 oldWALs 目錄的執行緒數量。 |
|
|
2 |
用來清除 oldWALs 目錄下 WAL 檔案的執行緒數量。 |
在 Amazon EMR 5.17.0 和更早版本中執行繁重的工作負載時,清理操作會影響查詢效能,因此建議您僅在離峰時段啟用清理工具。清理工具有如下的 HBase shell 命令:
cleaner_chore_enabled查詢清理工具是否已啟用。cleaner_chore_run手動執行清理工具以移除檔案。cleaner_chore_switch啟用或停用清理工具,並傳回清理工具之前的狀態。例如,cleaner_chore_switch true啟用清理工具。
HBase on Amazon S3 效能調校屬性
當您使用 HBase on Amazon S3 時,可以調整下列參數來微調您的工作負載效能。
| 組態屬性 | 預設值 | 描述 |
|---|---|---|
|
|
8,192 |
在區域伺服器 Amazon EC2 執行個體儲存體,與 BucketCache 儲存體 EBS 磁碟區所保留的磁碟空間量 (MB)。該設定會套用於所有區域伺服器執行個體。較大的 BucketCache 規模通常代表著效能的增進 |
|
|
134217728 |
Memstore 排清至 Amazon S3 的資料限制 (位元組) 已觸發。 |
|
|
4 |
在更新被封鎖時決定 MemStore 上限的乘數。如果 MemStore 超過 |
|
|
10 |
在更新被封鎖之前,可存在於存放區的最大數量 StoreFiles。 |
|
|
10737418240 |
在區域分割之前的大小上限。 |
關閉和還原叢集而不遺失資料
為了確保在關閉 Amazon EMR 叢集時不會遺失尚未寫入至 Amazon S3 的資料,您應將 MemStore 快取排清至 Amazon S3,才能寫入新的存放區檔案。首先,您需要停用所有資料表。當您新增步驟到叢集時,可以使用以下步驟組態。如需詳細資訊,請參閱《Amazon EMR 管理指南》中的使用 AWS CLI 和主控台來使用步驟。
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
或者,您也可以直接執行下列 bash 命令。
bash /usr/lib/hbase/bin/disable_all_tables.sh
在停用所有資料表之後,使用 HBase Shell 和下列命令排清 hbase:meta 資料表。
flush 'hbase:meta'
然後,您可以執行 Amazon EMR 叢集上提供的 Shell 指令碼,以排清 MemStore 快取。您可以新增它作為步驟,或使用叢集上的 AWS CLI來直接執行。此指令碼會停用所有 HBase 資料表,這會導致每個區域伺服器中的 MemStore 排清至 Amazon S3。如果該指令碼成功完成,則該資料將保留在 Amazon S3 中,且叢集可以終止。
若要重新啟動具有相同 HBase 資料的叢集,請在 中 AWS Management Console 或使用hbase.rootdir組態屬性指定與上一個叢集相同的 Amazon S3 位置。
