本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在本機開發和測試 AWS Glue 任務指令碼
開發和測試 AWS Glue for Spark 工作指令碼時,可使用多個選項:
AWS Glue Studio 主控台
Visual editor (視覺化編輯器)
指令碼編輯器
AWS Glue Studio 筆記本
互動式工作階段
Jupyter 筆記本
Docker 映像檔
本機開發
遠端開發
AWS Glue Studio ETL 程式庫
本機開發
您可根據自己的需求選擇上述任何選項。
如果不想要使用程式碼或不想使用大量程式碼,那麼 AWS Glue Studio 視覺化編輯器是個不錯的選擇。
如果您偏好互動式筆記本體驗,那麼 AWS Glue Studio 筆記本是個不錯的選擇。如需詳細資訊,請參閱搭配 AWS Glue Studio 和 AWS Glue 使用筆記本。如果想要使用自己的本機環境,那麼互動式工作階段是個不錯的選擇。如需詳細資訊,請參閱搭配 AWS Glue 使用互動式工作階段。
如果您偏好採用本機/遠端開發,那麼 Docker 映像檔是個不錯的選擇。這有助於您在任何地方開發和測試 AWS Glue for Spark 工作指令碼,而不會產生 AWS Glue 成本。
如果您偏好不使用 Docker 的本機開發模式,那麼在本機安裝 AWS Glue ETL 程式庫目錄是個不錯的選擇。
使用 AWS Glue Studio 開發
AWS Glue Studio 視覺化編輯器是一個新的圖形介面,有助於在 AWS Glue 更加輕鬆地内建立、執行、監控擷取、轉換和負載 (ETL) 任務。您可以用視覺化方式撰寫資料轉換工作流程,並在 AWS Glue 的 Apache Spark 型無伺服器 ETL 引擎上順暢地執行它們。您可以在任務的每個步驟中檢查結構描述和資料結果。如需詳細資訊,請參閱《AWS Glue Studio 使用者指南》。
使用互動式工作階段進行開發
使用互動式工作階段允許您自行選擇要建置和測試應用程式的環境。如需詳細資訊,請參閱搭配 AWS Glue 使用互動式工作階段。
使用 Docker 映像檔進行開發
注意
本節中的指示尚未在 Microsoft Windows 作業系統上進行測試。
如需 Windows 平台上的本機開發和測試,請參閱部落格在未使用 AWS 帳戶的情況下,在本機建置 AWS Glue ETL 管道
對於已準備用於生產的資料平台而言,AWS Glue 任務的開發流程和 CI/CD 管道是關鍵的主題。您可以靈活地開發和測試 Docker 容器中的 AWS Glue 任務。AWS Glue 在 Docker Hub 上託管 Docker 映像檔,以運用其他公用程式設定開發環境。您可透過 AWS Glue ETL 程式庫,使用您偏好的 IDE、筆記本或 REPL。本主題說明如何使用 Docker 映像檔,開發和測試 Docker 容器中的 AWS Glue 4.0 版任務。
以下 Docker 映像檔可用於 Docker Hub 上的 AWS Glue。
對於 AWS Glue 4.0 版:
amazon/aws-glue-libs:glue_libs_4.0.0_image_01若為 AWS Glue 3.0 版:
amazon/aws-glue-libs:glue_libs_3.0.0_image_01若為 AWS Glue 2.0 版:
amazon/aws-glue-libs:glue_libs_2.0.0_image_01
這些映像檔適用於 x86_64。建議您在此架構上進行測試。然而,在不支援的基礎映像上重製本機開發解決方案可能可行。
此範例說明在本機上使用 amazon/aws-glue-libs:glue_libs_4.0.0_image_01 並執行容器。此容器映像檔已通過 AWS Glue 3.3 版 Spark 任務的測試。該映像檔包含下列項目:
Amazon Linux
AWS Glue ETL 程式庫 (aws-glue-libs
) Apache Spark 3.3.0
Spark 歷史記錄伺服器
Jupyter Lab
Livy
與其他程式庫的相依性 (與 AWS Glue 任務系統中的同一組程式庫之間)
根據您的需求填妥下列其中一個區段︰
將容器設定為使用 spark-submit
將容器設定為使用 REPL Shell (PySpark)
將容器設定為使用 Pytest
將容器設定為使用 Jupyter Lab
將容器設定為使用 Visual Studio Code
先決條件
在開始之前,請務必安裝 Docker 並確保 Docker 常駐程式正在執行。如需安裝說明,請參閱 Mac
如需有關在本機開發 AWS Glue 程式碼的詳細資訊,請參閱本機開發限制。
設定 AWS
若要啟用來自容器的 AWS API 呼叫,請按照以下步驟設定 AWS 憑證。我們會在下列各節中使用此 AWS 具名設定檔。
-
設定 AWS CLI,配置已命名的設定檔。如需 AWS CLI 組態的詳細資訊,請參閱 AWS CLI 文件中的組態和憑證檔案設定。
在終端機執行下列命令︰
PROFILE_NAME="<your_profile_name>"
您可能還需要設定 AWS_LEGION 環境變數,以指定要傳送請求的目標 AWS 區域。
設定和執行容器
透過 spark-submit 命令設定容器或執行 PySpark 程式碼需進一步完成下列步驟:
從 Docker Hub 擷取映像檔
執行容器。
從 Docker Hub 擷取映像檔
執行以下命令可從 Docker Hub 中擷取映像檔:
docker pull amazon/aws-glue-libs:glue_libs_4.0.0_image_01
執行容器
然後再使用此映像檔執行容器。您可根據自己的需求選擇下列任何選項。
spark-submit
執行 AWS Glue 任務指令碼的方法是在容器上執行 spark-submit 命令。
編寫指令碼並將其儲存為
/local_path_to_workspace目錄下的sample1.py。本主題的附錄列有範本程式碼。$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME}執行下列命令可在容器上執行
spark-submit命令以提交新的 Spark 應用程式:$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_spark_submit amazon/aws-glue-libs:glue_libs_4.0.0_image_01 spark-submit /home/glue_user/workspace/src/$SCRIPT_FILE_NAME ...22/01/26 09:08:55 INFO DAGScheduler: Job 0 finished: fromRDD at DynamicFrame.scala:305, took 3.639886 s root |-- family_name: string |-- name: string |-- links: array | |-- element: struct | | |-- note: string | | |-- url: string |-- gender: string |-- image: string |-- identifiers: array | |-- element: struct | | |-- scheme: string | | |-- identifier: string |-- other_names: array | |-- element: struct | | |-- lang: string | | |-- note: string | | |-- name: string |-- sort_name: string |-- images: array | |-- element: struct | | |-- url: string |-- given_name: string |-- birth_date: string |-- id: string |-- contact_details: array | |-- element: struct | | |-- type: string | | |-- value: string |-- death_date: string ...-
(選用) 設定
spark-submit以符合您的環境。例如,可以將相依項與--jars組態一起傳遞。如需詳細資訊,請參閱 Spark 文件中的使用 spark-submit 啟動應用程式。
REPL Shell (Pyspark)
採互動式開發模式時,可執行 REPL (read-eval-print loop) Shell。
執行以下命令可在容器上執行 PySpark 命令以啟動 REPL Shell:
$ docker run -it -v ~/.aws:/home/glue_user/.aws -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pyspark amazon/aws-glue-libs:glue_libs_4.0.0_image_01 pyspark ... ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.1.1-amzn-0 /_/ Using Python version 3.7.10 (default, Jun 3 2021 00:02:01) Spark context Web UI available at http://56e99d000c99:4040 Spark context available as 'sc' (master = local[*], app id = local-1643011860812). SparkSession available as 'spark'. >>>
Pytest
單位測試時,AWS Glue Spark 任務指令碼可使用 pytest。
執行下列命令以完成前置作業。
$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ UNIT_TEST_FILE_NAME=test_sample.py $ mkdir -p ${WORKSPACE_LOCATION}/tests $ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}
執行下列命令可在測試套件上執行 pytest:
$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pytest amazon/aws-glue-libs:glue_libs_4.0.0_image_01 -c "python3 -m pytest" starting org.apache.spark.deploy.history.HistoryServer, logging to /home/glue_user/spark/logs/spark-glue_user-org.apache.spark.deploy.history.HistoryServer-1-5168f209bd78.out *============================================================= test session starts ============================================================= *platform linux -- Python 3.7.10, pytest-6.2.3, py-1.11.0, pluggy-0.13.1 rootdir: /home/glue_user/workspace plugins: anyio-3.4.0 *collected 1 item * tests/test_sample.py . [100%] ============================================================== warnings summary =============================================================== tests/test_sample.py::test_counts /home/glue_user/spark/python/pyspark/sql/context.py:79: DeprecationWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead. DeprecationWarning) -- Docs: https://docs.pytest.org/en/stable/warnings.html ======================================================== 1 passed, *1 warning* in 21.07s ========================================================
Jupyter Lab
您可在筆記本上啟動 Jupyter 以進行互動式開發和臨機操作查詢。
執行下列命令可啟動 Jupyter Lab:
$ JUPYTER_WORKSPACE_LOCATION=/local_path_to_workspace/jupyter_workspace/ $ docker run -it -v ~/.aws:/home/glue_user/.aws -v $JUPYTER_WORKSPACE_LOCATION:/home/glue_user/workspace/jupyter_workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 -p 8998:8998 -p 8888:8888 --name glue_jupyter_lab amazon/aws-glue-libs:glue_libs_4.0.0_image_01 /home/glue_user/jupyter/jupyter_start.sh ... [I 2022-01-24 08:19:21.368 ServerApp] Serving notebooks from local directory: /home/glue_user/workspace/jupyter_workspace [I 2022-01-24 08:19:21.368 ServerApp] Jupyter Server 1.13.1 is running at: [I 2022-01-24 08:19:21.368 ServerApp] http://faa541f8f99f:8888/lab [I 2022-01-24 08:19:21.368 ServerApp] or http://127.0.0.1:8888/lab [I 2022-01-24 08:19:21.368 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).使用本機電腦的 Web 瀏覽器開啟 http://127.0.0.1:8888/lab,即可查看 Jupyter Lab 使用者介面。
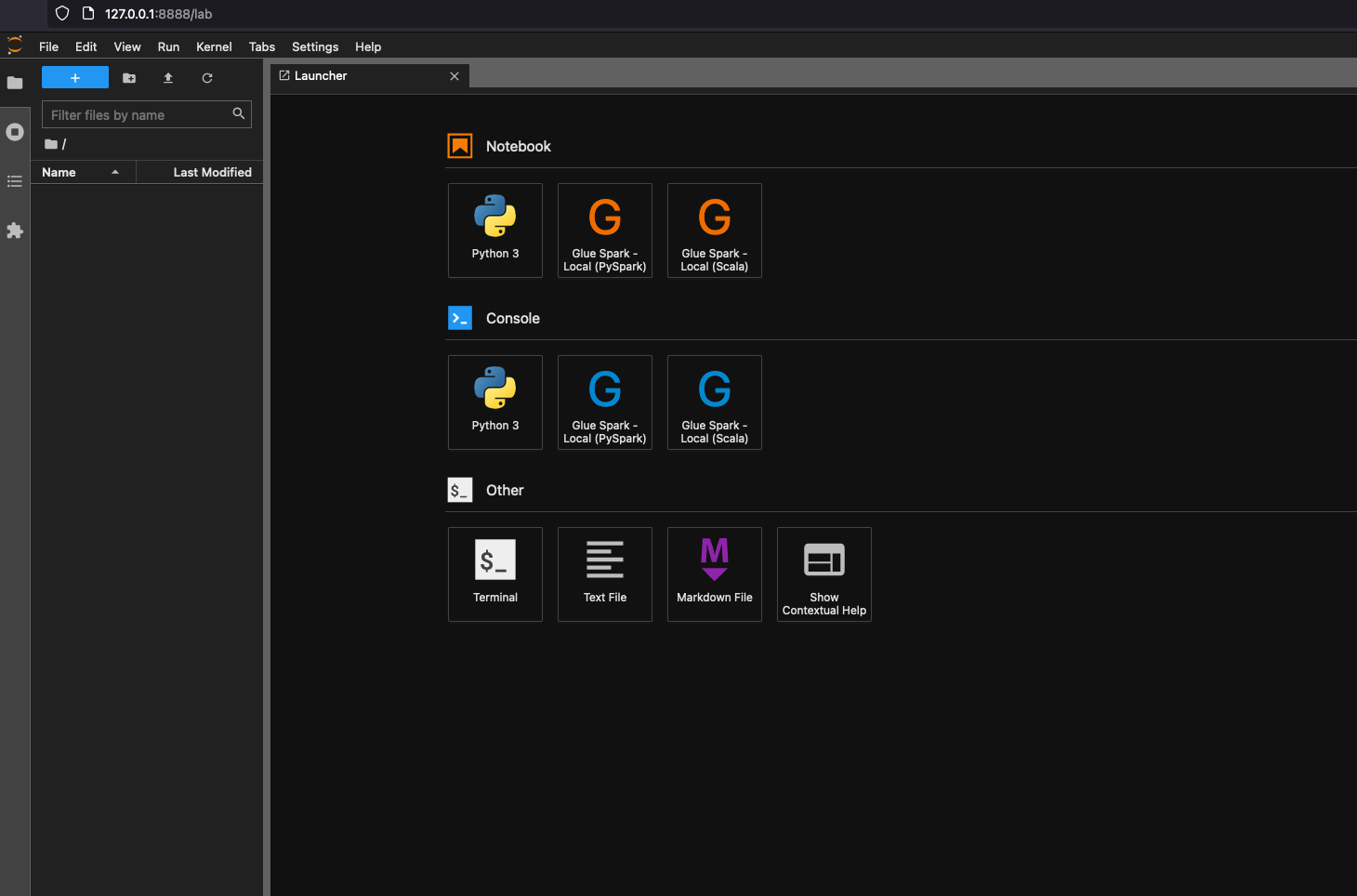
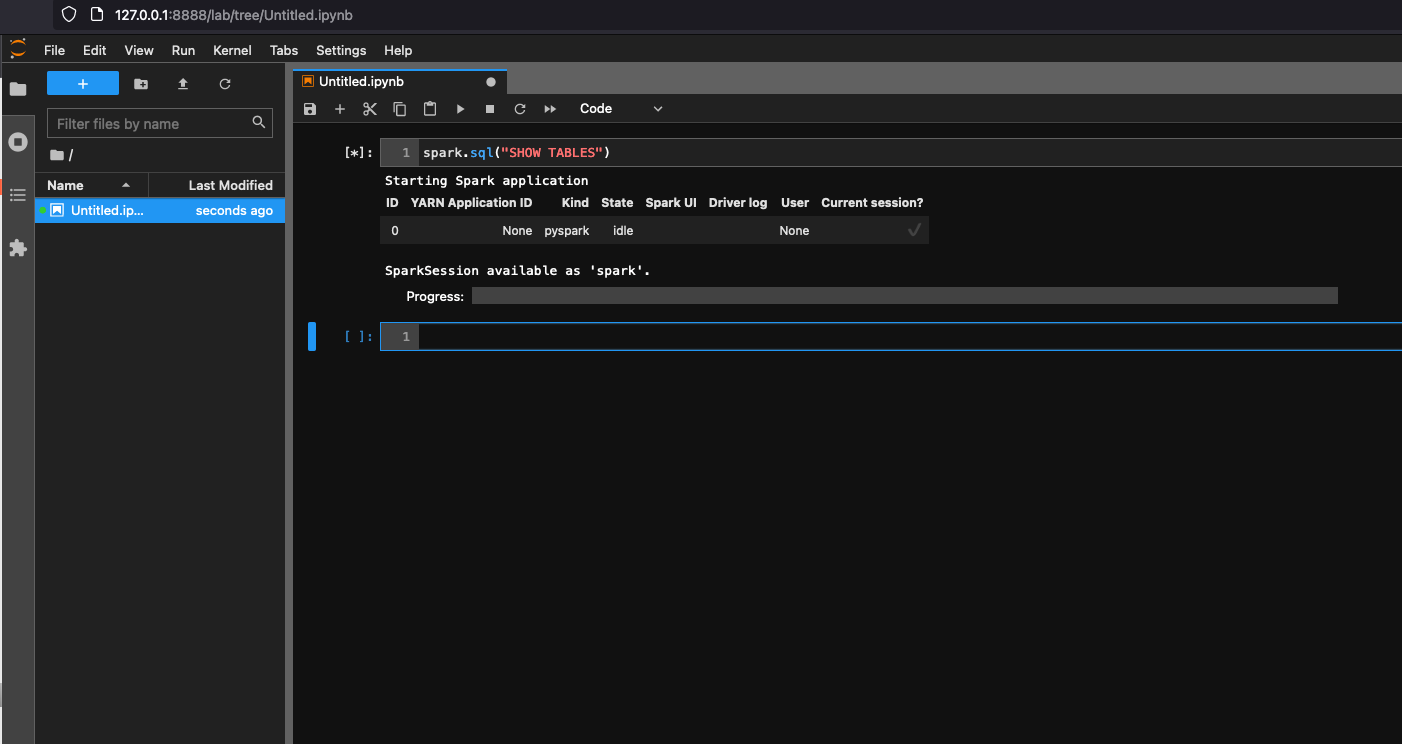
選擇 Notebook (筆記本) 之下的 Glue Spark Local (PySpark) (本機 Glue Spark (PySpark))。即可開始使用互動式 Jupyter 筆記本使用者介面來開發程式碼。
將容器設為使用 Visual Studio Code
事前準備:
安裝 Visual Studio Code。
安裝 Python
。 在 Visual Studio Code 中開啟 workspace (工作區) 資料夾。
選擇設定。
選擇 Workspace (工作區)。
選擇 Open Settings (JSON) (開啟設定 (JSON))。
將下列 JSON 貼上並儲存。
{ "python.defaultInterpreterPath": "/usr/bin/python3", "python.analysis.extraPaths": [ "/home/glue_user/aws-glue-libs/PyGlue.zip:/home/glue_user/spark/python/lib/py4j-0.10.9-src.zip:/home/glue_user/spark/python/", ] }
步驟:
執行 Docker 容器。
$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pyspark amazon/aws-glue-libs:glue_libs_4.0.0_image_01 pyspark啟動 Visual Studio Code。
選擇左側選單中的 Remote Explorer (遠端檔案總管),然後選擇
amazon/aws-glue-libs:glue_libs_4.0.0_image_01。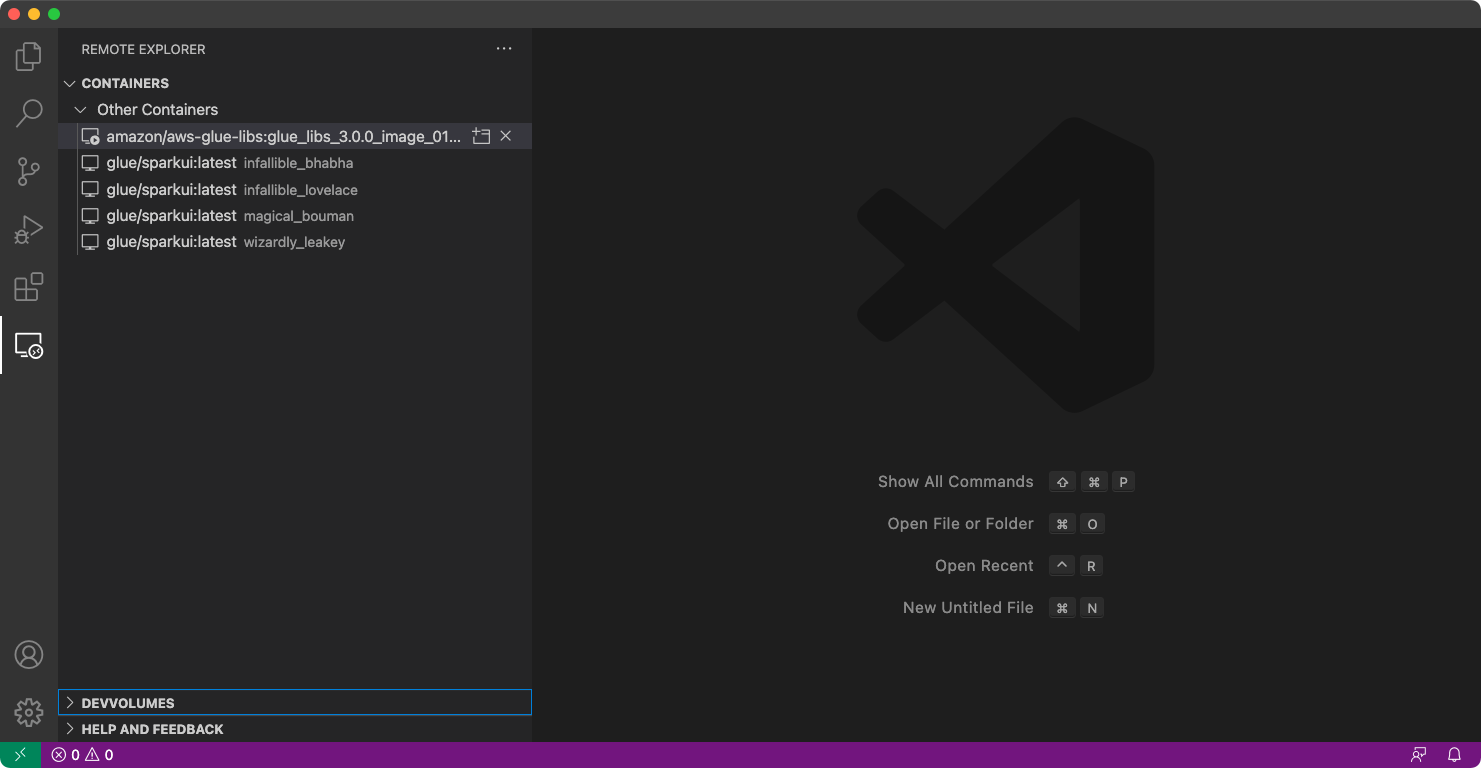
按一下滑鼠右鍵,選擇 Attach to Container (連接至容器)。若顯示對話方塊,請選擇 Got it (我知道了)。
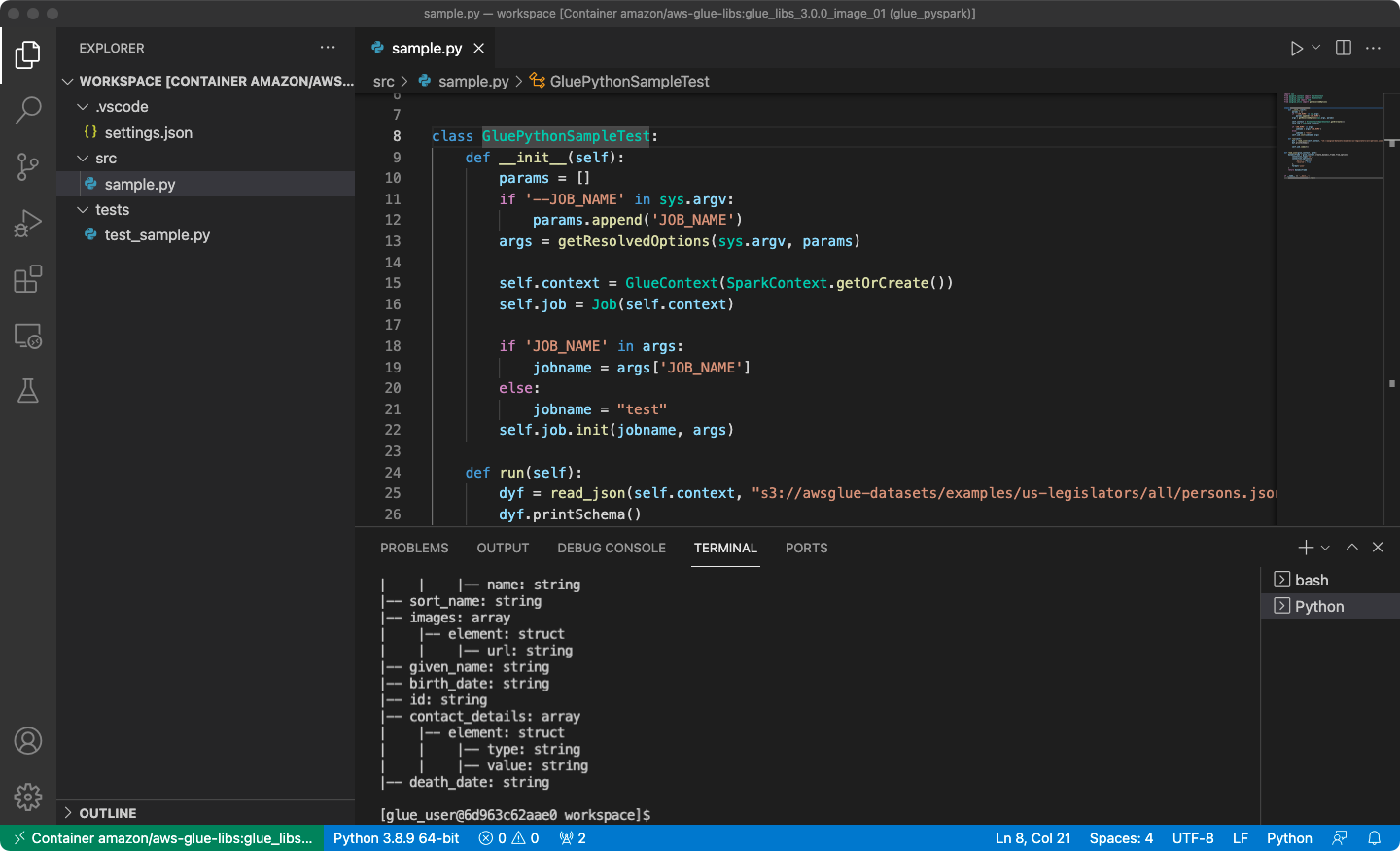
打開
/home/glue_user/workspace/.建立 Glue PySpark 指令碼,然後選擇 Run (執行)。
您會看到指令碼成功執行。
附錄:測試用的 AWS Glue 任務範本程式碼
本附錄內含的 AWS Glue 任務範本程式碼為供您測試之用的指令碼。
sample.py:透過 Amazon S3 API 呼叫以使用 AWS Glue ETL 程式庫的範本程式碼
import sys from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.utils import getResolvedOptions class GluePythonSampleTest: def __init__(self): params = [] if '--JOB_NAME' in sys.argv: params.append('JOB_NAME') args = getResolvedOptions(sys.argv, params) self.context = GlueContext(SparkContext.getOrCreate()) self.job = Job(self.context) if 'JOB_NAME' in args: jobname = args['JOB_NAME'] else: jobname = "test" self.job.init(jobname, args) def run(self): dyf = read_json(self.context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json") dyf.printSchema() self.job.commit() def read_json(glue_context, path): dynamicframe = glue_context.create_dynamic_frame.from_options( connection_type='s3', connection_options={ 'paths': [path], 'recurse': True }, format='json' ) return dynamicframe if __name__ == '__main__': GluePythonSampleTest().run()
上述程式碼需有 AWS IAM 的 Amazon S3 許可。您需授予 IAM 受管政策 arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess 或 IAM 自訂政策,才能調用 ListBucket 和 GetObject 作為 Amazon S3 路徑。
test_sample.py:sample.py 單位測試用的範本程式碼。
import pytest from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.utils import getResolvedOptions import sys from src import sample @pytest.fixture(scope="module", autouse=True) def glue_context(): sys.argv.append('--JOB_NAME') sys.argv.append('test_count') args = getResolvedOptions(sys.argv, ['JOB_NAME']) context = GlueContext(SparkContext.getOrCreate()) job = Job(context) job.init(args['JOB_NAME'], args) yield(context) job.commit() def test_counts(glue_context): dyf = sample.read_json(glue_context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json") assert dyf.toDF().count() == 1961
使用 AWS Glue ETL 程式庫進行開發
您可在公有 Amazon S3 儲存貯體中使用 AWS Glue ETL 程式庫,並將其提供給 Apache Maven 建置系統使用。如此一來,您就能在本機開發及測試 Python 和 Scala 擷取、傳輸和載入 (ETL) 指令碼,而無需連線至網路。建議使用 Docker 映像檔進行本地開發,因為它提供了正確設定的環境以使用此程式庫。
本機開發適用於所有 AWS Glue 版本,包括 AWS Glue 0.9 版、1.0 版、2.0 版及更新版本。如需 AWS Glue 適用的 Python 和 Apache Spark 版本相關資訊,請參閱 Glue version job property。
該程式庫會隨 Amazon 軟體授權 (https://aws.amazon.com/asl
本機開發限制
使用 AWS Glue Scala 程式庫在本機進行開發時,請謹記下列限制。
-
避免使用 AWS Glue 程式庫建立 Jar 組合 (「fat Jar」或「uber Jar」),因為這可能導致下列功能遭停用:
-
AWS Glue Parquet 寫入器 (在 AWS Glue 中使用 Parquet 格式)
上述功能只能在 AWS Glue 任務系統中使用。
-
本地開發不支援 FindMatches 轉換。
-
進行本機開發時,不支援向量化 SIMD CSV 讀取器。
-
進行本機開發時,不支援用於從 S3 路徑載入 JDBC 驅動程式的屬性 customJdbcDriverS3Path。或者,您可以在本機下載 JDBC 驅動程式並從中載入。
-
進行本機開發時,不支援 Glue Data Quality。
在本機開發 Python
您需要先完成一些事前準備步驟,才能接著使用 AWS Glue 公用程式來測試及提交 Python ETL 指令碼。
在本機開發 Python 的事前準備
請完成下列步驟以準備在本機開發 Python:
-
複製 GitHub 的 AWS Glue Python 儲存庫 (https://github.com/awslabs/aws-glue-libs
)。 -
執行下列作業之一:
若為 AWS Glue 0.9 版,請簽出分支
glue-0.9。若為 AWS Glue 1.0 版,請簽出分支
glue-1.0。AWS Glue 0.9 以上的所有版本都援 Python 3。若為 AWS Glue 2.0 版,請簽出分支
glue-2.0。若為 AWS Glue 3.0 版,請簽出分支
glue-3.0。若為 AWS Glue 4.0 版,請簽出
master分支。
-
從以下位置安裝 Apache Maven:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-common/apache-maven-3.6.0-bin.tar.gz
。 -
從以下位置安裝 Apache Spark 分發:
若為 AWS Glue 0.9 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-0.9/spark-2.2.1-bin-hadoop2.7.tgz
若為 AWS Glue 1.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-1.0/spark-2.4.3-bin-hadoop2.8.tgz
若為 AWS Glue 2.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-2.0/spark-2.4.3-bin-hadoop2.8.tgz
若為 AWS Glue 3.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-3.0/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3.tgz
對於 AWS Glue 4.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-4.0/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0.tgz
-
匯出
SPARK_HOME環境變數,並以擷取自 Spark 存檔的根位置來設定該變數。例如:若為 AWS Glue 0.9 版:
export SPARK_HOME=/home/$USER/spark-2.2.1-bin-hadoop2.7若為 AWS Glue 1.0 版和 2.0 版:
export SPARK_HOME=/home/$USER/spark-2.4.3-bin-spark-2.4.3-bin-hadoop2.8若為 AWS Glue 3.0 版:
export SPARK_HOME=/home/$USER/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3對於 AWS Glue 4.0 版:
export SPARK_HOME=/home/$USER/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0
執行 Python ETL 指令碼
透過適用於本機開發的 AWS Glue Jar 檔案,您即可在本機執行 AWS Glue Python 套件。
請使用下列公用程式和架構來測試 Python 指令碼,並予以執行。下表所列的命令皆需從 AWS Glue Python 套件
| 公用程式 | 命令 | 說明 |
|---|---|---|
| AWS Glue Shell | ./bin/gluepyspark |
在與 AWS Glue ETL 程式庫整合的 shell 中輸入並執行 Python 指令碼。 |
| AWS Glue Submit (提交) | ./bin/gluesparksubmit |
提交要執行的完整 Python 指令碼。 |
| Pytest | ./bin/gluepytest |
撰寫並執行 Python 程式碼的單元測試。請務必在 PATH 中安裝並使用 pytest 模組。如需詳細資訊,請參閱 Pytest 文件 |
在本機開發 Scala
您需要先完成一些事前準備步驟,然後發出 Maven 命令,才能在本機執行 Scala ETL 指令碼。
在本機開發 Scala 的事前準備
請完成下列步驟以準備在本機開發 Scala:
步驟 1:安裝軟體
在此步驟中,您需要安裝軟體並設定必要的環境變數。
-
從以下位置安裝 Apache Maven:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-common/apache-maven-3.6.0-bin.tar.gz
。 -
從以下位置安裝 Apache Spark 分發:
若為 AWS Glue 0.9 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-0.9/spark-2.2.1-bin-hadoop2.7.tgz
若為 AWS Glue 1.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-1.0/spark-2.4.3-bin-hadoop2.8.tgz
若為 AWS Glue 2.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-2.0/spark-2.4.3-bin-hadoop2.8.tgz
若為 AWS Glue 3.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-3.0/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3.tgz
對於 AWS Glue 4.0 版:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-4.0/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0.tgz
-
匯出
SPARK_HOME環境變數,並以擷取自 Spark 存檔的根位置來設定該變數。例如:若為 AWS Glue 0.9 版:
export SPARK_HOME=/home/$USER/spark-2.2.1-bin-hadoop2.7若為 AWS Glue 1.0 版和 2.0 版:
export SPARK_HOME=/home/$USER/spark-2.4.3-bin-spark-2.4.3-bin-hadoop2.8若為 AWS Glue 3.0 版:
export SPARK_HOME=/home/$USER/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3對於 AWS Glue 4.0 版:
export SPARK_HOME=/home/$USER/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0
步驟 2:設定 Maven 專案
您可使用以下 pom.xml 檔案做為 AWS Glue Scala 應用程式的範本。它包含必要的 dependencies、repositories 和 plugins 元素。以下列其中一項取代 Glue version 字串:
-
適用於 AWS Glue 4.0 版的
4.0.0 -
適用於 AWS Glue 3.0 版的
3.0.0 -
適用於 AWS Glue 1.0 或 2.0 版的
1.0.0 -
適用於 AWS Glue 0.9 版的
0.9.0
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.amazonaws</groupId> <artifactId>AWSGlueApp</artifactId> <version>1.0-SNAPSHOT</version> <name>${project.artifactId}</name> <description>AWS ETL application</description> <properties> <scala.version>2.11.1 for AWS Glue 2.0 or below, 2.12.7 for AWS Glue 3.0 and 4.0</scala.version> <glue.version>Glue version with three numbers (as mentioned earlier)</glue.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> <!-- A "provided" dependency, this will be ignored when you package your application --> <scope>provided</scope> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>AWSGlueETL</artifactId> <version>${glue.version}</version> <!-- A "provided" dependency, this will be ignored when you package your application --> <scope>provided</scope> </dependency> </dependencies> <repositories> <repository> <id>aws-glue-etl-artifacts</id> <url>https://aws-glue-etl-artifacts.s3.amazonaws.com/release/</url> </repository> </repositories> <build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <!-- see http://davidb.github.com/scala-maven-plugin --> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.4.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.6.0</version> <executions> <execution> <goals> <goal>java</goal> </goals> </execution> </executions> <configuration> <systemProperties> <systemProperty> <key>spark.master</key> <value>local[*]</value> </systemProperty> <systemProperty> <key>spark.app.name</key> <value>localrun</value> </systemProperty> <systemProperty> <key>org.xerial.snappy.lib.name</key> <value>libsnappyjava.jnilib</value> </systemProperty> </systemProperties> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-enforcer-plugin</artifactId> <version>3.0.0-M2</version> <executions> <execution> <id>enforce-maven</id> <goals> <goal>enforce</goal> </goals> <configuration> <rules> <requireMavenVersion> <version>3.5.3</version> </requireMavenVersion> </rules> </configuration> </execution> </executions> </plugin> <!-- The shade plugin will be helpful in building a uberjar or fatjar. You can use this jar in the AWS Glue runtime environment. For more information, see https://maven.apache.org/plugins/maven-shade-plugin/ --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <configuration> <!-- any other shade configurations --> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
執行 Scala ETL 指令碼
請從 Maven 專案的根目錄執行以下命令,藉此執行 Scala ETL 指令碼。
mvn exec:java -Dexec.mainClass="mainClass" -Dexec.args="--JOB-NAMEjobName"
使用該指令碼主要類別的完全合格類別名稱來取代 mainClass,並將 jobName 替換成所需任務名稱。
設定測試環境
如需設定本機測試環境的範例,請參閱下列部落格文章:
如果您想要使用開發端點或筆記本來測試 ETL 指令碼,請參閱使用開發端點來開發指令碼。
注意
開發端點不支援用於 AWS Glue 2.0 版任務。如需詳細資訊,請參閱以縮短的啟動時間執行 Spark ETL 任務。
