本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
進行 OOM 例外與任務異常的除錯
您可以針對 AWS Glue 中的記憶體不足 (OOM) 例外和任務異常進行除錯。下列的段落所說明的除錯案例,是針對 Apache Spark 驅動程式或 Spark 執行器的記憶體不足 (OOM) 例外進行除錯。
進行驅動程式 OOM 例外的除錯
在這個案例中,Spark 任務會從 Amazon Simple Storage Service (Amazon S3) 讀取大量的小型檔案。接著將檔案轉換成 Apache Parquet 格式,然後寫入到 Amazon S3。Spark 驅動程式的記憶體即將用盡。輸入的 Amazon S3 資料在不同的 Amazon S3 分割區中,具有超過 100 萬個檔案。
分析程式碼如下:
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path") data.write.format("parquet").save(output_path)
在 AWS Glue 主控台上視覺化已分析的指標
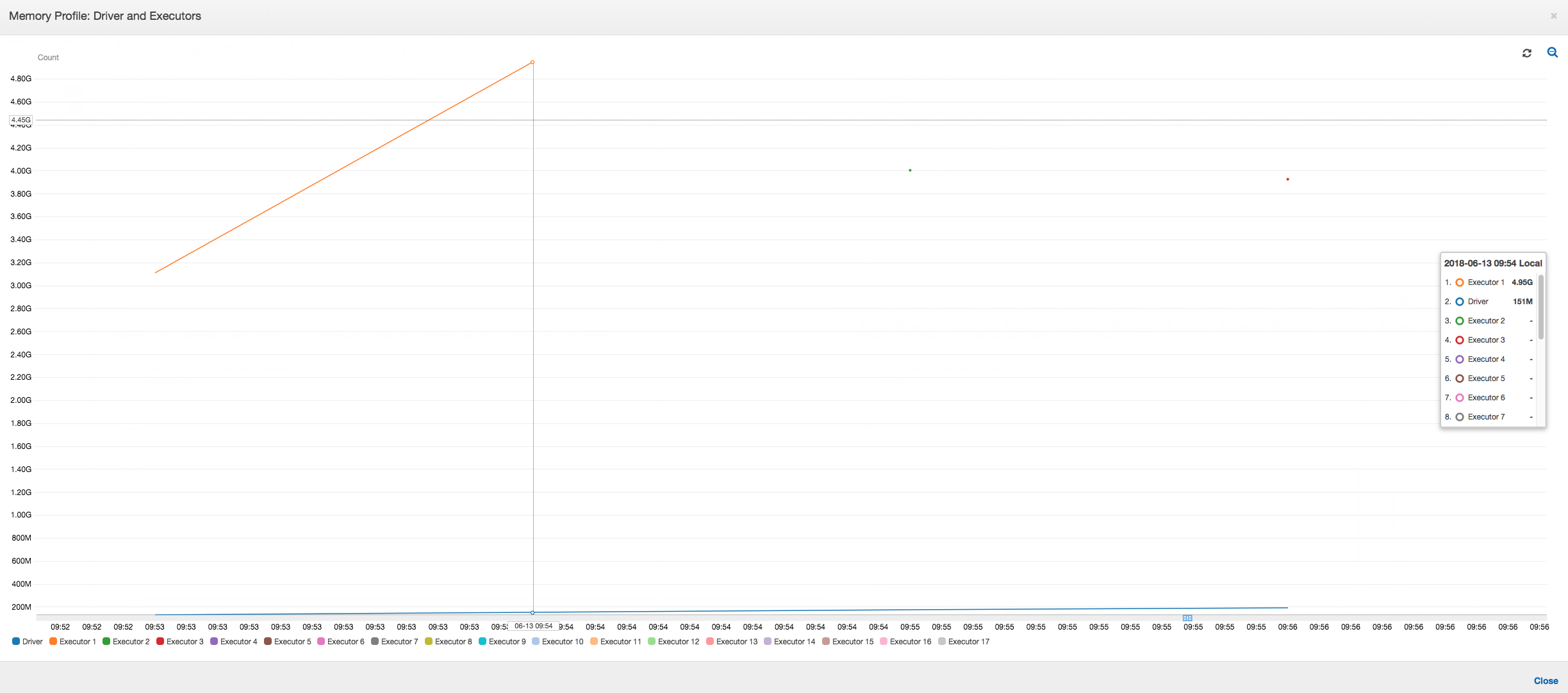
下列的圖表顯示驅動程式和執行器的記憶體使用量百分比。此用量曲線是由一個資料點繪製而成,而此資料點是過去一分鐘內所呈報值的平均值。您可以看到在任務的記憶體使用狀況圖中,驅動程式記憶體很快地就超過 50% 的安全使用量門檻。另一方面,所有執行器的整體平均記憶體使用量仍然低於 4%。這明顯地顯示出這項 Spark 任務中驅動程式執行的異常狀況。
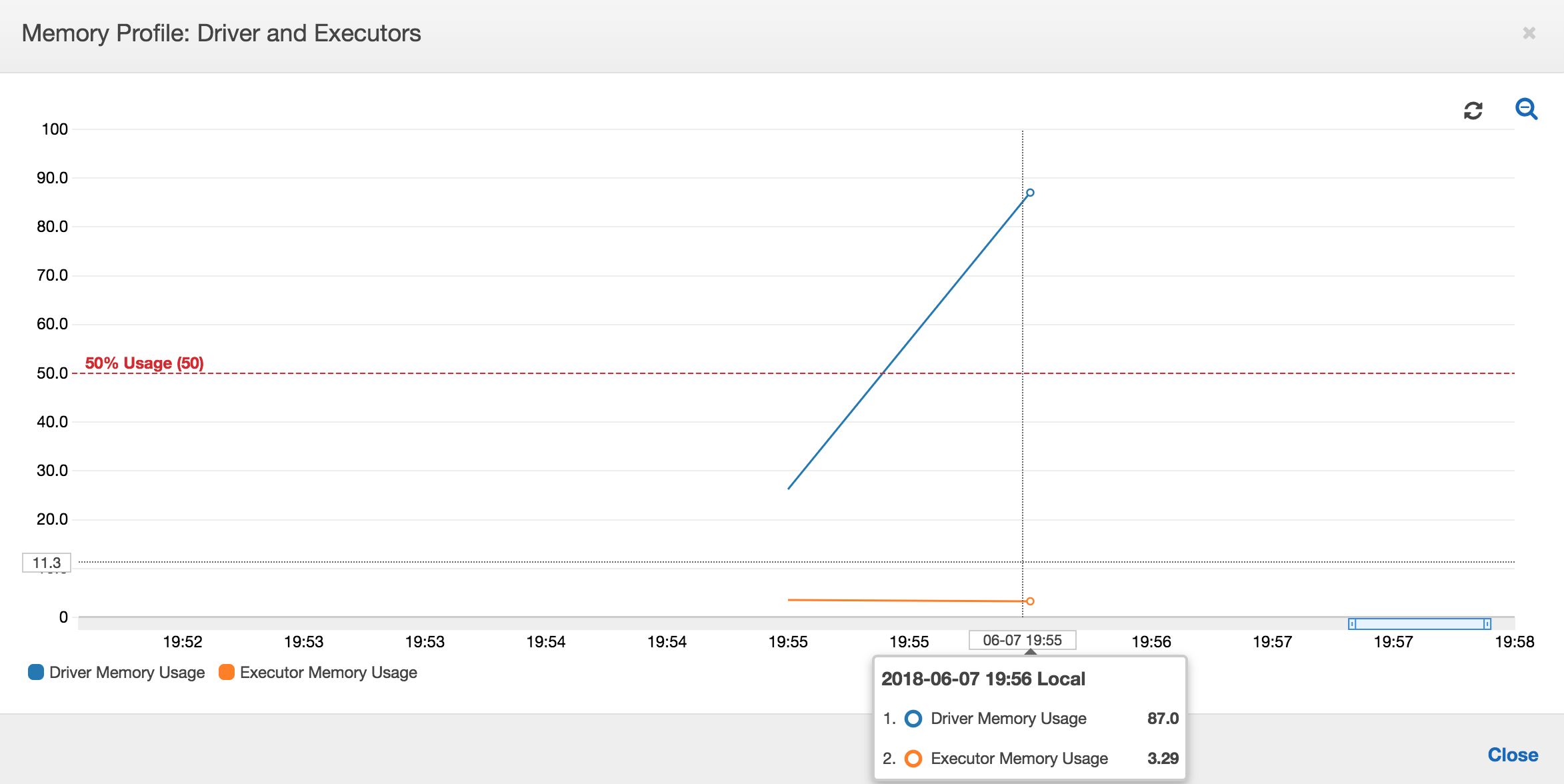
工作的執行很快地失敗,在 主控台的 History (歷程記錄)AWS Glue 索引標籤中,顯示了下列的錯誤訊息:Command Failed with Exit Code 1 (指令執行失敗,結束代碼 1)。這個錯誤字串代表任務因系統錯誤而失敗,在此案例中,是因為驅動程式的記憶體用盡。

在主控台的 History (歷程記錄) 索引標籤中,選擇 Error logs (錯誤日誌) 連結,來確認 CloudWatch Logs 所提供關於驅動程式 OOM 的資訊。在任務的錯誤日誌中搜尋「Error」,確認這的確是讓任務失敗的 OOM 例外:
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh -c "kill -9 12039"...
在任務的 History (歷程記錄) 索引標籤中,選擇 Logs (日誌)。您可於任務開始時在 CloudWatch Logs 找到驅動程式執行的追蹤。Spark 驅動程式會試著列出所有目錄中的所有檔案、建立 InMemoryFileIndex,並針對每個檔案啟動一個任務。這會導致 Spark 驅動程式必須在記憶體中維持大量的狀態顯示,以追蹤所有的任務。該驅動程式會針對大量檔案的完整清單建立快取,以維持記憶體內的索引,進而造成驅動程式的 OOM。
利用分組功能來修正處理多個檔案的問題
您可以利用 中的分組AWS Glue功能,來修正處理多個檔案的問題。使用動態框架時,以及輸入資料集包含大量檔案 (超過 50,000 個) 時,分組功能就會自動啟用。分組功能可讓您將多個檔案合併為一個群組,讓任務處理整個群組而非單一檔案。因此,Spark 驅動程式儲存於記憶體中的狀態顯示會大幅減少,追蹤的任務也減少。關於手動啟用資料集的分組功能,詳細資訊請參閱 讀取在大型群組中的輸入檔案。
若要查看 AWS Glue 任務的記憶體使用狀況,請在啟用分組功能的狀況下,分析下列程式碼:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
您可以在 AWS Glue 任務狀況分析中,監控記憶體的使用狀況和 ETL 資料的移動。
在 AWS Glue 任務的整個任務期間內,驅動程式都會以低於 50% 的記憶體使用量閥值來執行。執行器會串流來自 Amazon S3 的資料、進行處理,然後將資料輸出寫入到 Amazon S3。因此,執行器在任何時點所使用的記憶體皆少於 5%。

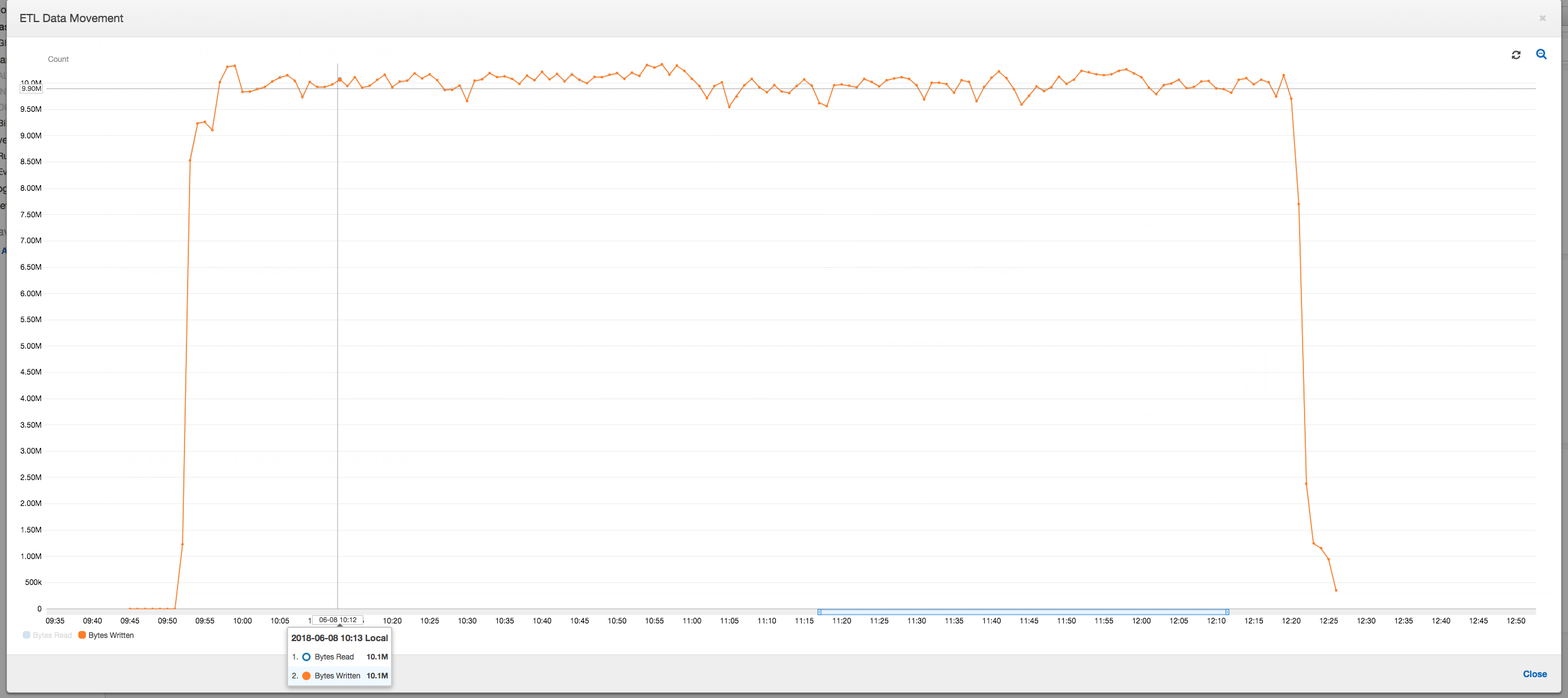
下列的資料移動狀況圖,顯示了所有執行器隨著任務的進行,過去一分鐘內讀取和寫入的 Amazon S3 位元組總數。這兩種動作都會遵循相同的模式,讓資料分散透過所有執行器串流。這項任務會在不到三小時內處理完所有的一百萬個檔案。
進行執行器 OOM 例外的除錯
在此案例中,您可以了解如何針對 Apache Spark 執行器可能會發生的 OOM 例外,來進行除錯。下列的程式碼使用了 Spark MySQL 讀取器,來將包含約 3,400 萬行的大型資料表,讀取到 Spark DataFrame 中。接著再以 Parquet 格式,將資料輸出寫入至 Amazon S3。您可以提供連線屬性,並使用預設的 Spark 組態來讀取資料表。
val connectionProperties = new Properties() connectionProperties.put("user", user) connectionProperties.put("password", password) connectionProperties.put("Driver", "com.mysql.jdbc.Driver") val sparkSession = glueContext.sparkSession val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties) dfSpark.write.format("parquet").save(output_path)
在 AWS Glue 主控台上視覺化已分析的指標
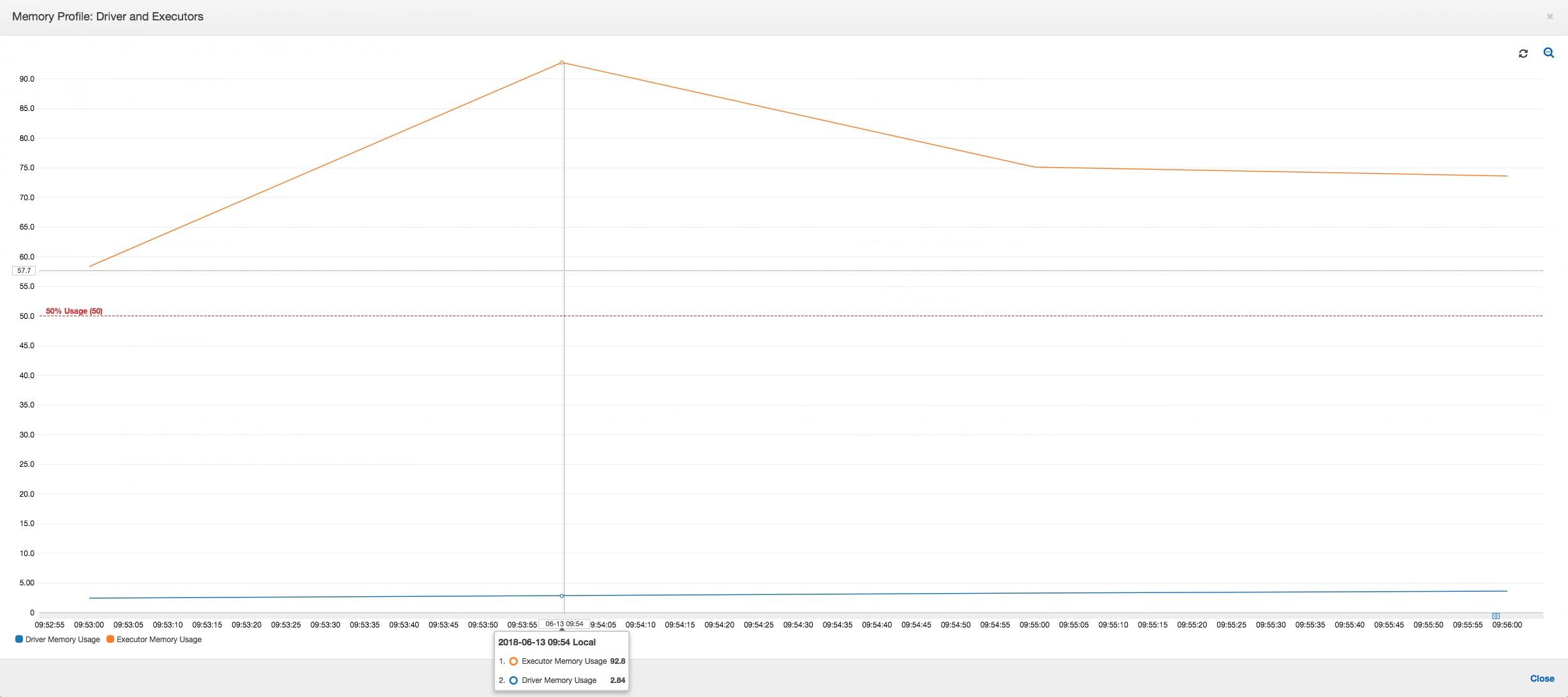
如果記憶體使用量圖表的斜率為正值且跨越 50%,則如果在發出下一個指標之前任務失敗,則記憶體耗盡很可能是造成失敗的原因。下列圖表顯示執行開始的一分鐘內,所有執行器的平均記憶體使用量快速暴增超過 50%。使用量達到 92%,而執行此執行器的容器被 Apache Hadoop YARN 停止。
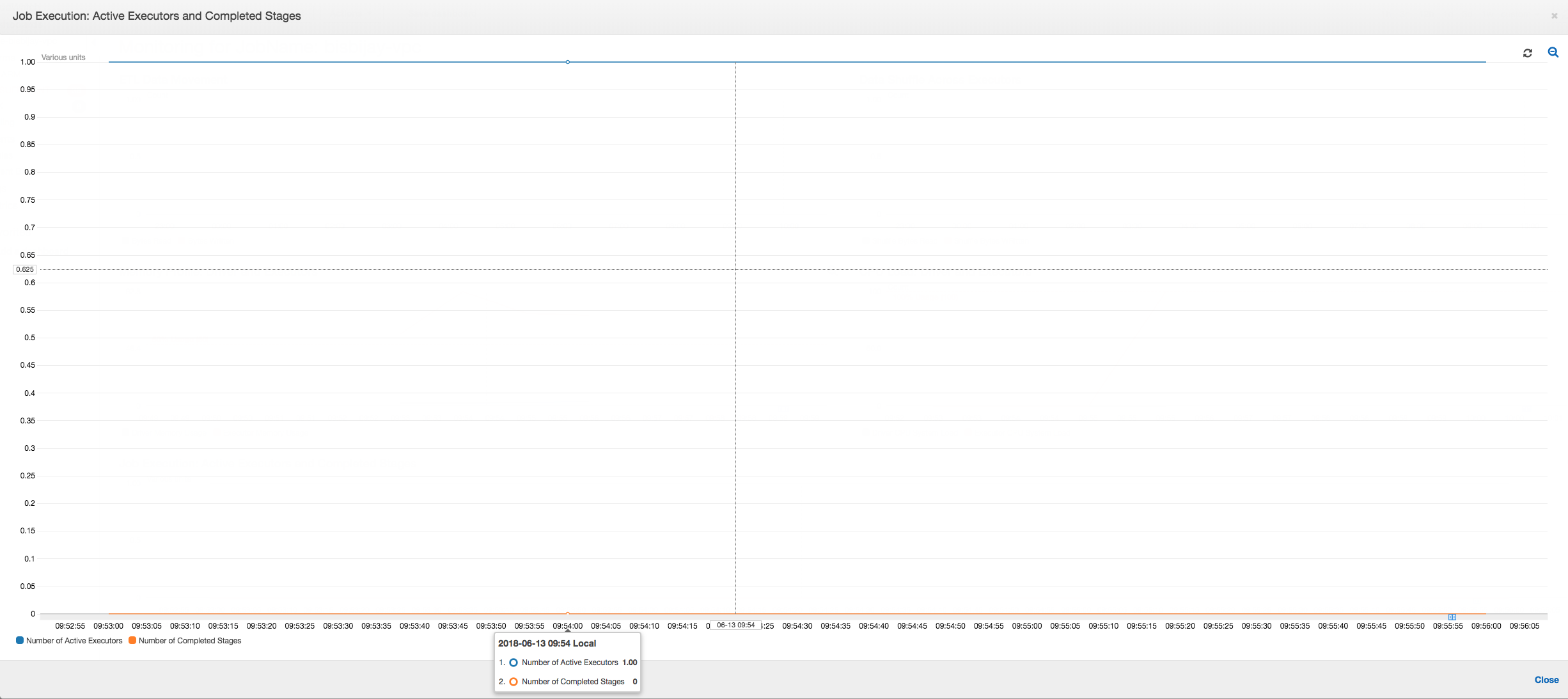
如下列圖表所示,到任務失敗之前,一直都有單一執行器在執行。這是由於啟動了新的執行器來取代已停止的執行器。JDBC 資料來源的讀取,預設並非平行進行,因為這會需要從欄分割資料表,並開啟多個連線。因此,只有一個執行器會以序列方式讀取完整的資料表。
如下列圖表所示,在任務失敗之前,Spark 嘗試啟動新的任務四次。您可以查看三個執行器的記憶體使用狀況。每個執行器很快地就用完自己所有的記憶體。當第四個執行器用完記憶體後,任務就失敗了。因此,並未立即呈報其指標。
您可以從 AWS Glue 主控台上的錯誤字串,確認任務是因為 OOM 例外而失敗,如下列圖像所示。

任務輸出日誌:為了進一步確認執行器 OOM 例外的情況,請檢視 CloudWatch Logs。搜尋 Error 時,您會發現四個執行器大約是在相同的期間內遭到停止,如指標儀表板上所示。因為超過了記憶體使用量的限制,這些執行器全都遭到 YARN 終止。
執行器 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
執行器 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
執行器 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
執行器 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
利用 AWS Glue 動態框架來修正擷取大小
由於預設的 Spark JDBC 擷取大小為 0,因此執行器在讀取 JDBC 資料表時用盡了記憶體。這代表 Spark 執行器上的 JDBC 驅動程式,試著一次從資料庫擷取 3,400 萬行的資料,並建立這些資料的快取 (即使 Spark 是一次一行的進行串流作業)。使用 Spark 時,您可以將擷取大小的參數,設定為非 0 的預設值,來避免這種狀況發生。
您也可以改用 AWS Glue 動態框架,來修正這個問題。在預設情況下,動態框架會使用 1,000 個資料列的擷取大小,通常這個設定值已經夠用。因此,執行器不會使用超過總記憶體 7% 的記憶體量。AWS Glue 任務只會使用單一執行器,在不到兩分鐘內完成。雖然我們建議使用 AWS Glue 動態框架,但是您也可以使用 Apache Spark fetchsize 屬性來設定擷取大小。請參閱 Spark SQL、DataFrames 和資料集指南
val (url, database, tableName) = { ("jdbc_url", "db_name", "table_name") } val source = glueContext.getSource(format, sourceJson) val df = source.getDynamicFrame glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
正常分析指標:使用 動態框架的執行器記憶體AWS Glue絕對不會超過安全門檻,如下列圖像所示:此等記憶體會從資料庫串流資料行,而且任何時點只會針對 JDBC 驅動程式中的 1,000 行建立快取。不會發生記憶體不足的例外狀況。

