本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
針對高要求的階段和落後任務進行除錯
您可以利用 AWS Glue 任務分析功能,在擷取、轉換和載入 (ETL) 任務中,找出高要求階段和落後任務。在 AWS Glue 任務的階段中,落後任務所花費的作業時間,遠多於其他的任務。因此,此等任務需要花較長的時間完成作業,也延遲了任務的總執行時間。
將小型的輸入檔案合併為較大的輸出檔案
當不同任務之間的作業量分配不均,或是資料傾斜造成某個任務需要處理更多的資料時,就可能會出現落後的任務。
您可以分析下列程式碼 (在 Apache Spark 中的通用模式),來將大量的小型檔案合併為較大的輸出檔案。在這個範例中,輸入資料集是 32 GB 的 JSON Gzip 壓縮檔案。輸出資料集約包含 190 GB 的未壓縮 JSON 檔案。
分析程式碼如下:
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
在 AWS Glue 主控台上視覺化已分析的指標
您可以分析任務,檢驗四組不同的指標:
-
ETL 資料移動
-
在執行器之間的資料隨機移動
-
任務執行
-
記憶體使用狀況
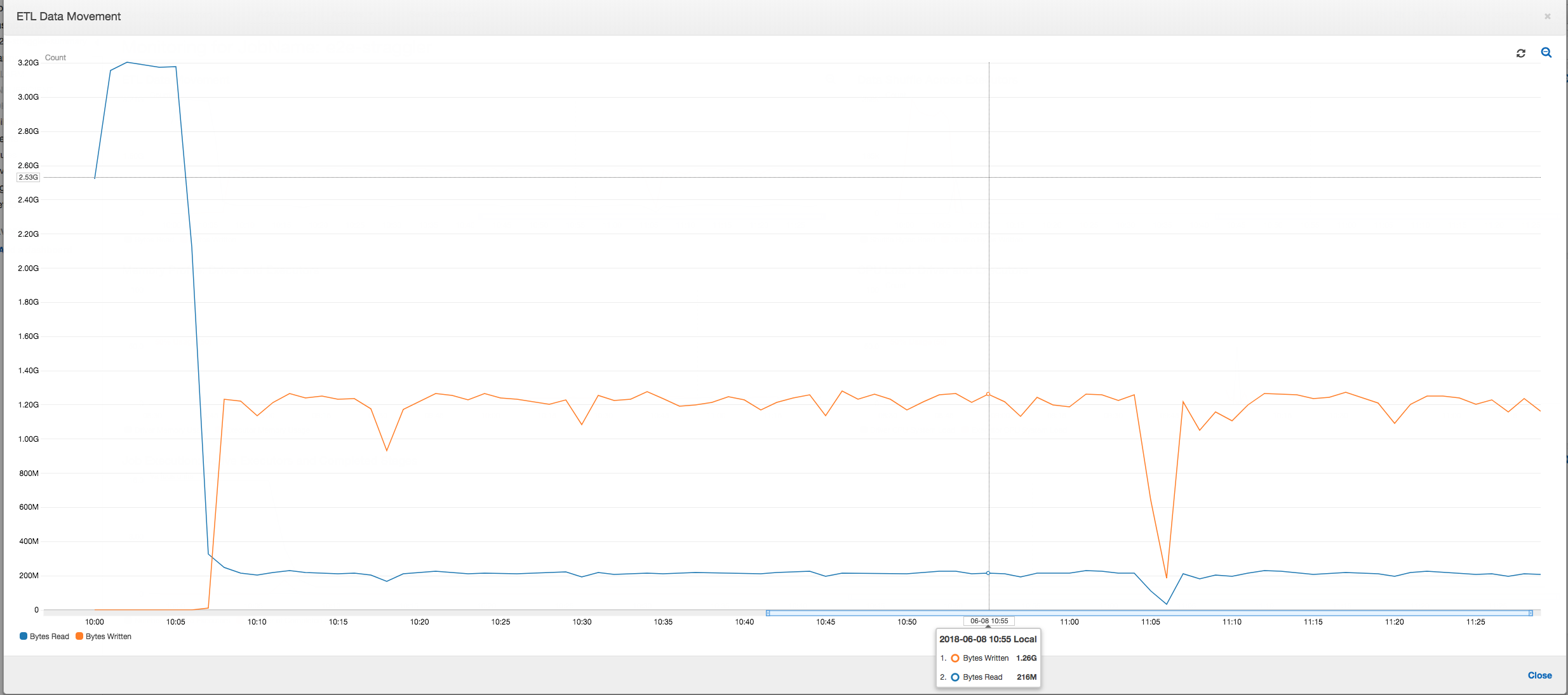
ETL 資料移動:在 ETL Data Movement (ETL 資料移動) 分析圖表中,所有執行器在前 6 分鐘內就完成的第一個階段中,相當快速地讀取資料 (單位:位元組)。不過,任務執行的總時間約為一個小時,大部分為資料寫入作業。
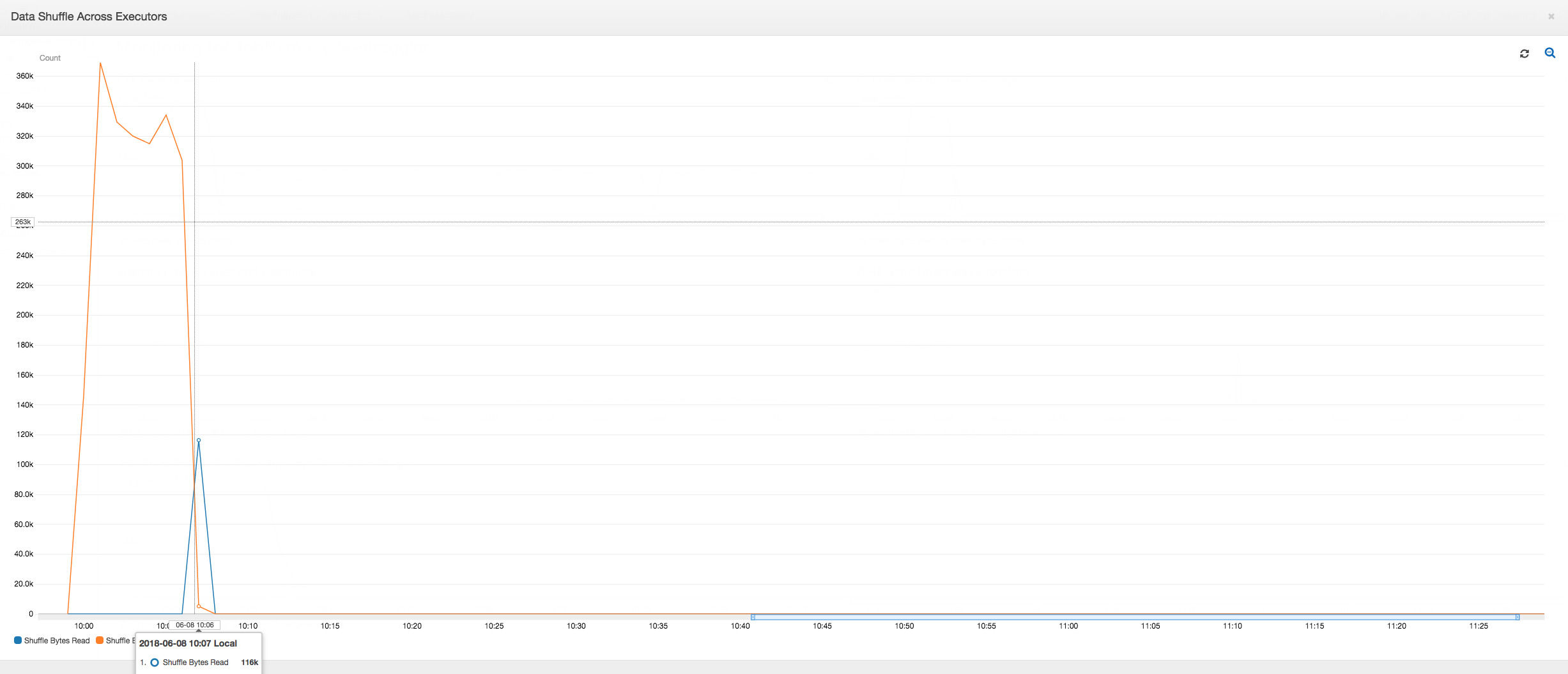
執行器之間的資料隨機移動:在第二階段結束之前,隨機移動資料期間讀取和寫入的位元組數量出現突增的峰值,如 Job Execution (任務執行) 和 Data Shuffle (資料隨機移動) 指標所示。在所有執行器隨機移動資料之後,就只從第 3 號執行器進行讀取和寫入。
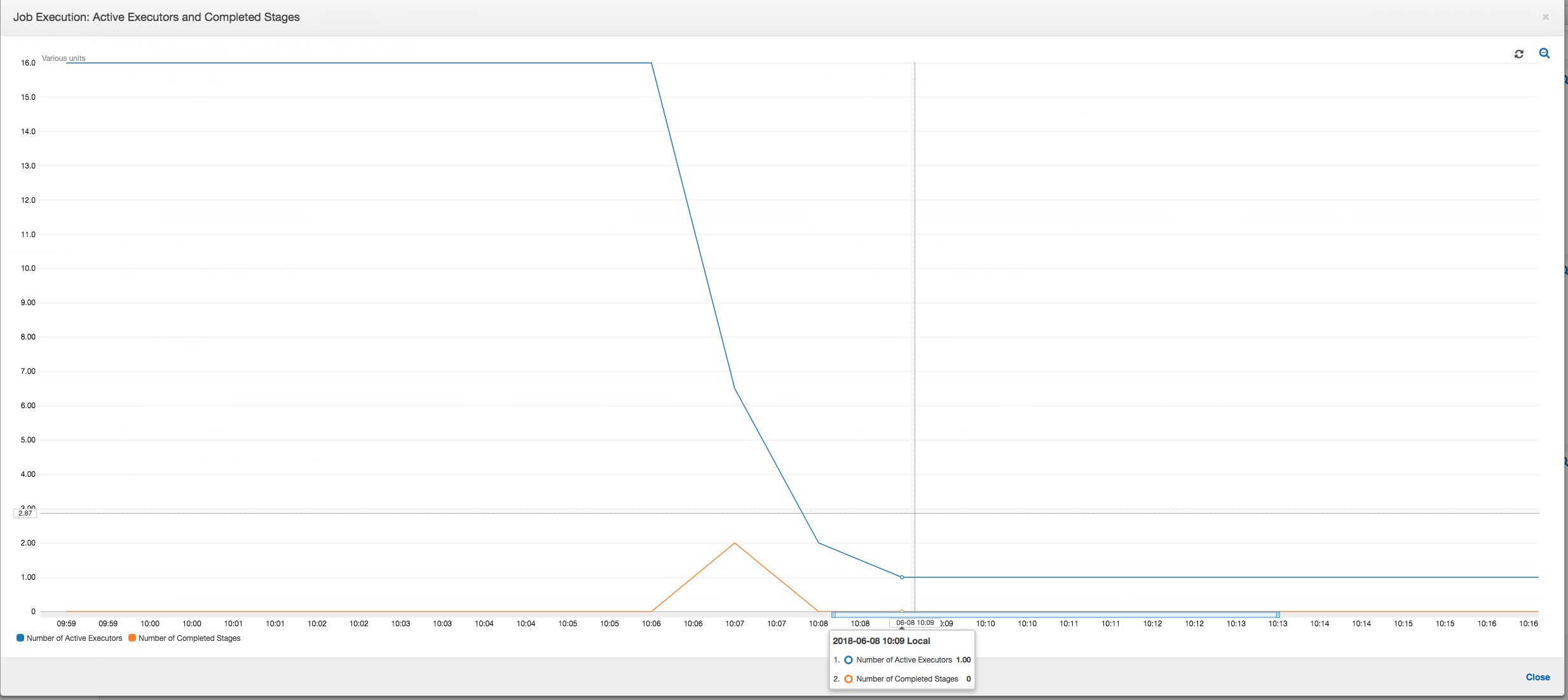
任務執行:如下列圖表所示,其他所有的執行器皆處於閒置狀態,最後在 10:09 之前終止。在這個時間點,執行器的總數減少到只剩下一個。這清楚地顯示出,第 3 號執行器包含落後任務,此任務所花費的執行時間最長,而且佔了大部分的任務執行時間。
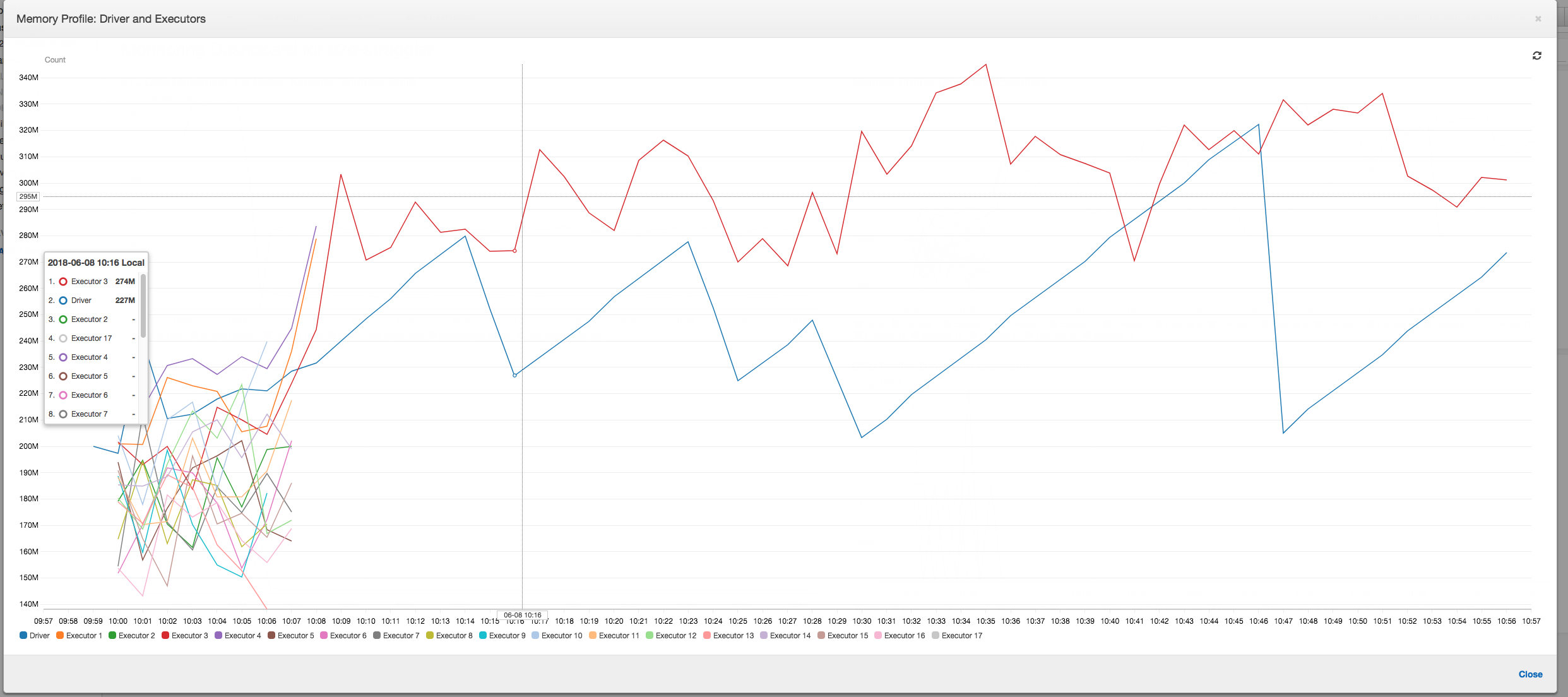
記憶體使用狀況:經過前兩階段後,只有第 3 號執行器正在使用記憶體來運作處理資料。剩下的執行器只是處於閒置狀態,或是在前兩個階段完成之後,就很快地遭到終止。
利用分組來解決落後執行器的問題
您可以利用 中的分組AWS Glue功能,來避免出現落後的執行器。利用分組功能,將資料平均地分配給所有執行器,並使用叢集上所有可用的執行器,將檔案合併為更大型的檔案。如需詳細資訊,請參閱 讀取在大型群組中的輸入檔案。
若要查看 AWS Glue 任務中的 ETL 資料移動狀況,請在啟用分組功能的情況下,分析下列程式碼:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
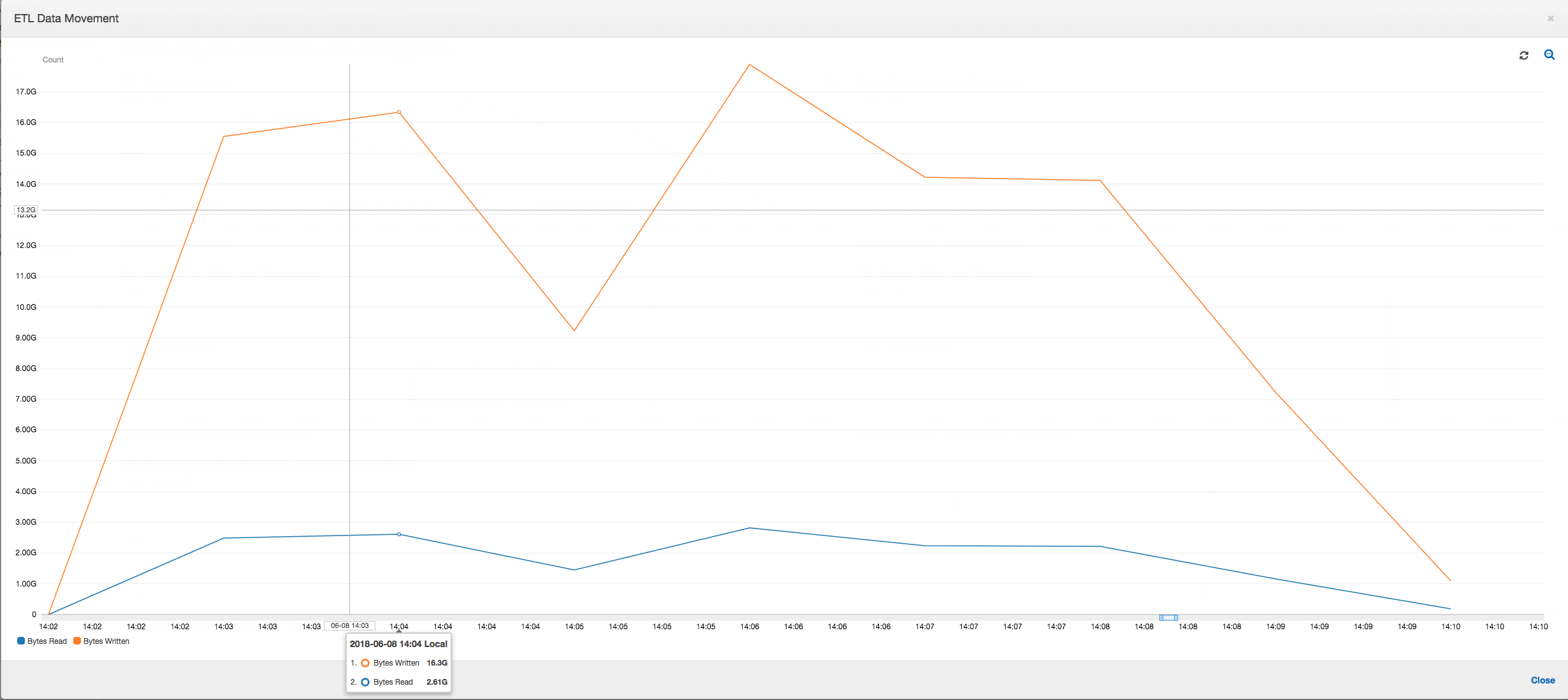
ETL 資料移動:在整個任務執行期間,資料寫入作業現在會與資料讀取作業並行串流。因此,任務會在 8 分鐘之內完成,速度比之前快上許多。
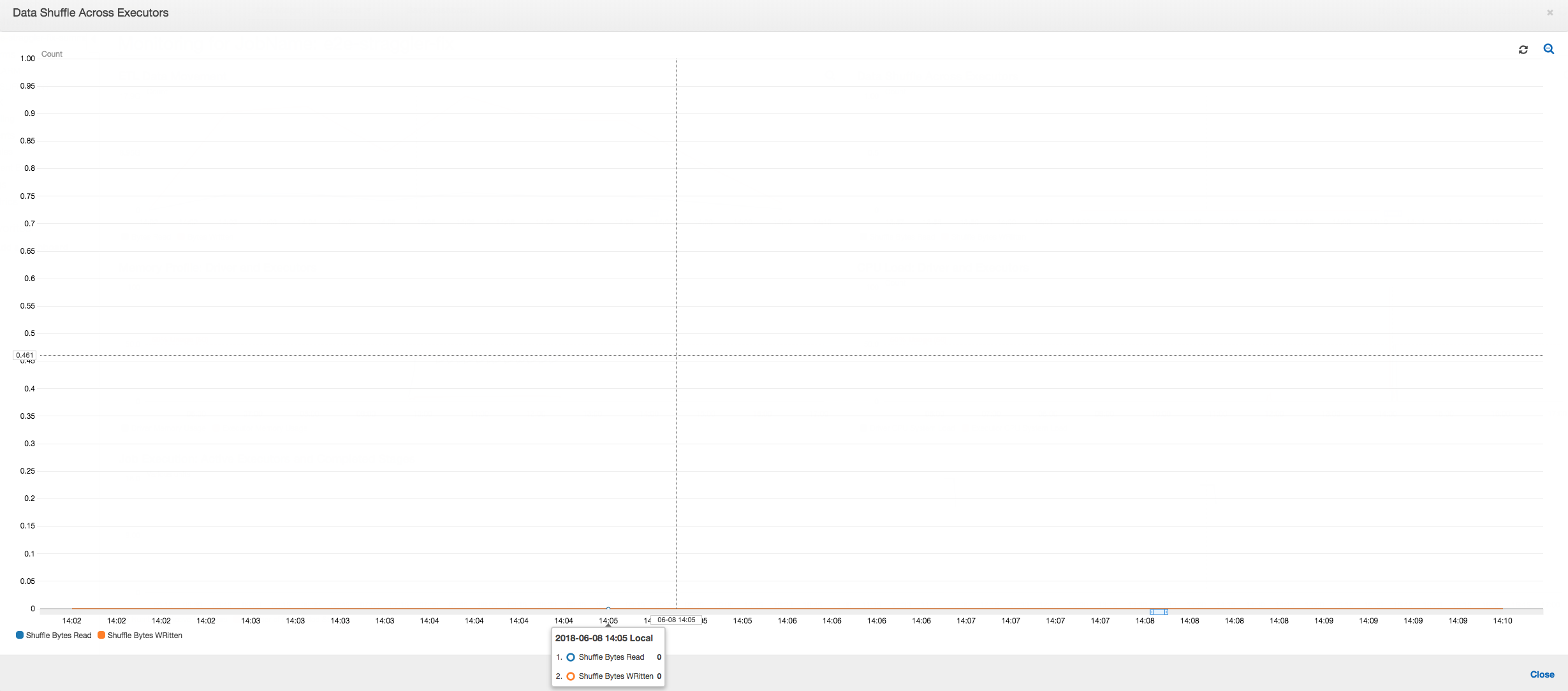
執行器之間的資料隨機移動:在進行讀取時,使用分組功能將輸入檔案合併之後,就不用在資料讀取之後,進行成本昂貴的資料隨機移動作業。
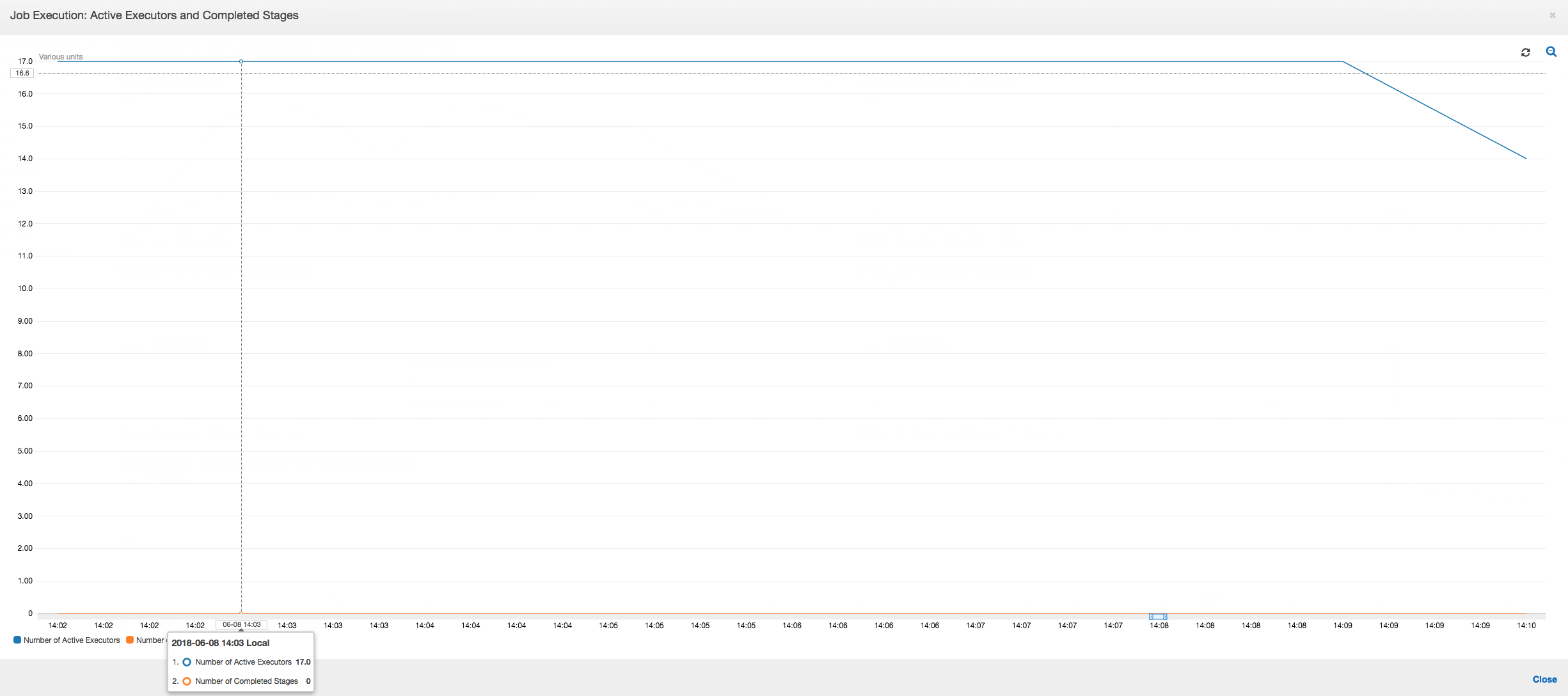
任務執行:任務執行指標會顯示運作中執行器的總數,以及處理的資料維持地相當穩定。在任務中沒有任何落後作業。所有的執行器皆處於運作狀態,在任務尚未完成之前,不會遭到終止。由於不需在執行器之間進行中間的資料隨即移動作業,因此任務中只有一個階段。
記憶體使用狀況:此指標顯示所有執行器的現用記憶體使用量—重新確認所有的執行器都在活動中。隨著資料同時串流傳入和輸出寫入,所有執行器使用的總記憶體大致平均,而且遠低於所有執行器的安全門檻值。

