本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 Apache Spark web UI 監控任務
您可以使用 Apache Spark Web UI 來監控和偵錯在 AWS Glue 任務系統上執行的 AWS Glue ETL 任務,以及在 AWS Glue 開發端點上執行的 Spark 應用程式。Spark UI 可讓您為每個任務檢查下列項目:
-
每個 Spark 階段的事件時間軸
-
任務的有向無環圖 (DAG)
-
SparkSQL 查詢的實體和邏輯計畫
-
每個任務的基礎 Spark 環境變數
如需有關使用 Spark Web UI 的詳細資訊,請參閱《Spark 文件》中的 Web UI
您可以在 AWS Glue 主控台中查看 Spark UI。當 AWS Glue 任務以標準 (而非舊版) 格式產生的日誌在 AWS Glue 3.0 或更新版本上執行時,即可使用此功能,這是較新任務的預設值。如果您的日誌檔案大於 0.5 GB,您可以為在 AWS Glue 4.0 或更新版本上執行的任務啟用滾動日誌支援,以簡化日誌封存、分析和故障診斷。
您可以使用 AWS Glue主控台或 AWS Command Line Interface () 啟用 Spark UI AWS CLI。當您啟用 Spark UI 時,AWS Glue 開發端點上的 AWS Glue ETL 任務和 Spark 應用程式可以將 Spark 事件日誌備份到您在 Amazon Simple Storage Service (Amazon S3) 中指定的位置。可搭配使用 Amazon S3 中已備份的事件日誌與 Spark UI,即可在工作運作時即時使用,也可在工作完成後使用。當日誌保留在 Amazon S3 中時, AWS Glue 主控台中的 Spark UI 可以檢視它們。
許可
若要在 AWS Glue 主控台中使用 Spark UI,您可以使用UseGlueStudio或新增所有個別服務 APIs。所有 APIs都需要完全使用 Spark UI,但使用者可以在 IAM 許可中新增其服務 APIs 來存取 SparkUI 功能,以進行精細存取。
RequestLogParsing 執行日誌剖析時最為重要。其餘 APIs 用於讀取個別剖析的資料。例如, GetStages可讓您存取 Spark 任務所有階段的資料。
映射至 的 Spark UI 服務 APIs清單UseGlueStudio如下範例政策。以下政策提供僅限使用 Spark UI 功能的存取權。若要新增更多許可,例如 Amazon S3 和 IAM,請參閱為 建立自訂 IAM 政策 AWS Glue Studio。
映射到 的 Spark UI 服務 APIs清單UseGlueStudio在範例政策中如下。使用 Spark UI 服務 API 時,請使用下列命名空間:glue:<ServiceAPI>。
限制
-
AWS Glue 主控台中的 Spark UI 不適用於 2023 年 11 月 20 日之前發生的任務執行,因為它們是舊版日誌格式。
-
AWS Glue 主控台中的 Spark UI 支援滾動日誌 for AWS Glue 4.0,例如串流任務中預設產生的日誌。所有產生的滾動日誌事件檔案的總和上限為 2 GB。對於沒有滾動日誌支援 AWS Glue 的任務,SparkUI 支援的日誌事件檔案大小上限為 0.5 GB。
-
Serverless Spark UI 不適用於存放在 Amazon S3 儲存貯體中的 Spark 事件日誌,只能由您的 VPC 存取。
範例:Apache Spark Web UI
此範例顯示如何使用 Spark UI 了解工作效能。螢幕擷取畫面顯示自我管理的 Spark 歷史記錄伺服器提供的 Spark Web UI。 AWS Glue 主控台中的 Spark UI 提供類似的檢視。如需有關使用 Spark Web UI 的詳細資訊,請參閱《Spark 文件》中的 Web UI
以下是 Spark 應用程式的範例,它會讀取兩個資料來源、執行聯結轉換,然後以 Parquet 格式將其寫入至 Amazon S3。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.functions import count, when, expr, col, sum, isnull from pyspark.sql.functions import countDistinct from awsglue.dynamicframe import DynamicFrame args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME']) df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json") df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json") df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter') df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/") job.commit()
下列 DAG 視覺化顯示此 Spark 任務中的不同階段。

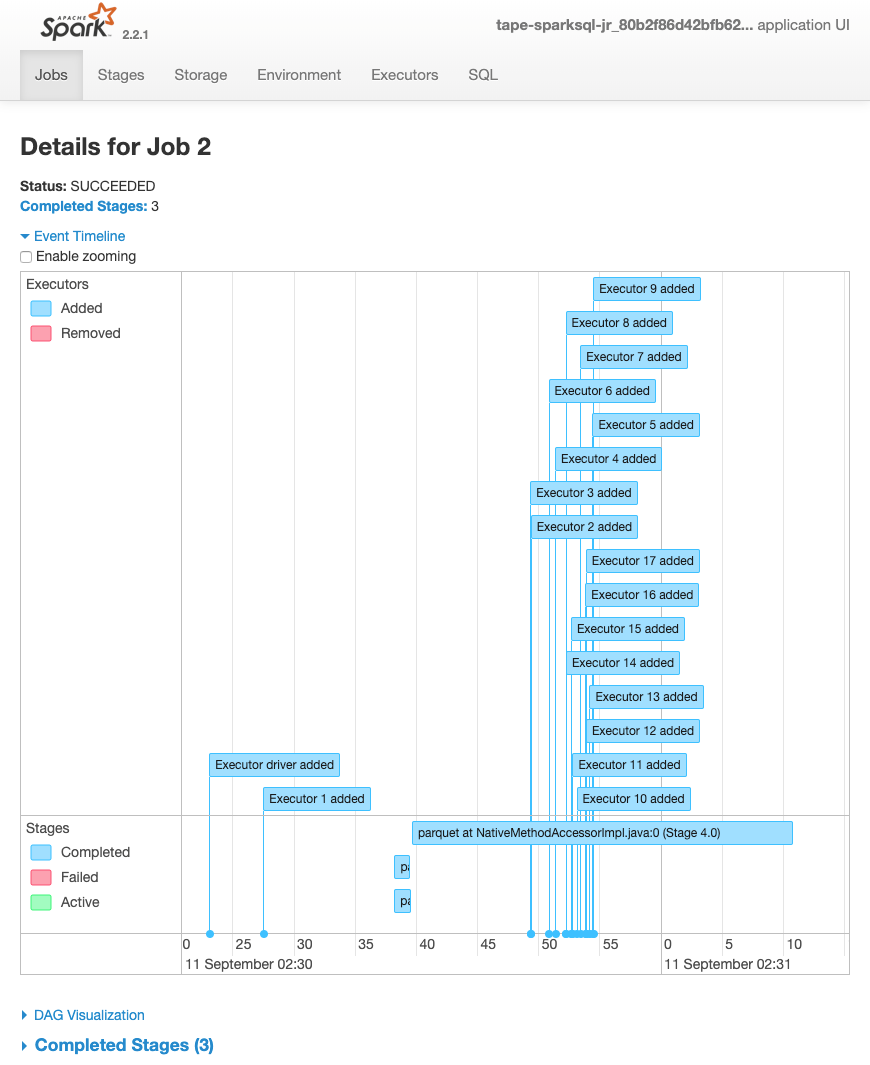
下列任務的事件時間軸顯示不同 Spark 執行器的啟動、執行和終止。
下列畫面顯示 SparkSQL 查詢計畫的詳細資訊:
-
已剖析的邏輯計畫
-
已分析的邏輯計畫
-
已最佳化的邏輯計畫
-
要執行的實體計畫

