在仔細考慮之後,我們決定停止 Amazon Kinesis Data Analytics for SQL 應用程式:
1. 從 2025 年 9 月 1 日起,我們不會為 Amazon Kinesis Data Analytics for SQL 應用程式提供任何錯誤修正,因為考慮到即將終止,我們將對其提供有限的支援。
2. 從 2025 年 10 月 15 日起,您將無法建立新的 Kinesis Data Analytics for SQL 應用程式。
3. 我們將自 2026 年 1 月 27 日起刪除您的應用程式。您將無法啟動或操作 Amazon Kinesis Data Analytics for SQL 應用程式。從那時起,Amazon Kinesis Data Analytics for SQL 將不再提供支援。如需詳細資訊,請參閱Amazon Kinesis Data Analytics for SQL 應用程式終止。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
交錯窗口
使用交錯窗口是一種窗口化方法,適用於分析不一致時間到達的資料群組。此方式非常適合任何時間序列分析使用案例,例如一組相關的銷售或日誌記錄。
例如,VPC 流程日誌的擷取窗口約為 10 分鐘。但如果你在客戶端上彙總資料,則可以有一個長達 15 分鐘的擷取窗口,。交錯視窗是彙總這些日誌以進行分析的理想選擇。
交錯窗口可解決相關記錄未落入相同時間限制窗口的問題,例如使用輪轉窗口時。
有輪轉窗口的部分結果
彙總遲到或順序錯誤的資料時,使用 輪轉窗口 有某些限制。
如果使用輪轉窗口來分析與時間相關的資料群組,則個別記錄可能會落入不同的窗口中。因此,每個窗口的部分結果必須在稍後合併,以產生每組記錄的完整結果。
在下面的輪轉窗口查詢中,記錄按列時間,事件時間和股票代號分組到窗口中:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( TICKER_SYMBOL VARCHAR(4), EVENT_TIME timestamp, TICKER_COUNT DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER_SYMBOL, FLOOR(EVENT_TIME TO MINUTE), COUNT(TICKER_SYMBOL) AS TICKER_COUNT FROM "SOURCE_SQL_STREAM_001" GROUP BY ticker_symbol, FLOOR(EVENT_TIME TO MINUTE), STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '1' MINUTE);
在下圖中,應用程式根據交易發生的時間(事件時間),以一分鐘的精細程度計算接收的交易數量。該應用程式可以使用輪轉窗口,根據列時間和事件時間幫資料分組。該應用程式收到四條記錄,這些記錄彼此都在一分鐘內到達。它按列時間,事件時間和股票符號幫記錄分組。因為有些記錄會在第一個輪轉窗口結束後到達,所以記錄不會全部落在相同的一分鐘輪轉窗口內。
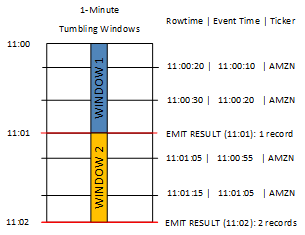
前面的圖表具有以下事件。
| ROWTIME | EVENT_TIME | TICKER_SYMBOL |
|---|---|---|
| 11:00:20 | 11:00:10 | AMZN |
| 11:00:30 | 11:00:20 | AMZN |
| 11:01:05 | 11:00:55 | AMZN |
| 11:01:15 | 11:01:05 | AMZN |
來自輪轉窗口應用程式的結果集類似如下。
| ROWTIME | EVENT_TIME | TICKER_SYMBOL | COUNT |
|---|---|---|---|
| 11:01:00 | 11:00:00 | AMZN | 2 |
| 11:02:00 | 11:00:00 | AMZN | 1 |
| 11:02:00 | 11:01:00 | AMZN | 1 |
在之前的結果集中,傳回了三個結果:
記錄的
ROWTIME為 11:01:00,彙總了前兩個記錄。11:02:00 的記錄僅彙總了第三條記錄。此記錄在第二個窗口中有一個
ROWTIME,但在第一個窗口中有一個EVENT_TIME。11:02:00 的記錄僅彙總了第四條記錄。
若要分析完整的結果集,必須在持續性存放區彙總記錄。這會增加應用程式的複雜性和處理需求。
交錯窗口的完整結果
為了提高分析時間相關資料記錄的準確性,Kinesis Data Analytics 提供了一種稱為交錯窗口的新窗口類型。在此窗口類型中,窗口會在第一個與分割區索引鍵相符的事件到達時打開,而不是在固定的時間間隔。窗口會依指定的存留期關閉,測量由窗口開啟時起算。
在窗口子句中,交錯窗口是每個索引鍵群組的個別時間限制窗口。應用程式會在自己的時間窗口內彙總窗口子句的每個結果,而不是針對所有結果使用單一窗口。
在下面的交錯窗口查詢中,記錄按事件時間和股票代號分組到窗口中:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( ticker_symbol VARCHAR(4), event_time TIMESTAMP, ticker_count DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER_SYMBOL, FLOOR(EVENT_TIME TO MINUTE), COUNT(TICKER_SYMBOL) AS ticker_count FROM "SOURCE_SQL_STREAM_001" WINDOWED BY STAGGER ( PARTITION BY FLOOR(EVENT_TIME TO MINUTE), TICKER_SYMBOL RANGE INTERVAL '1' MINUTE);
在下圖中,事件按事件時間和股票代號彙總到交錯窗口中。
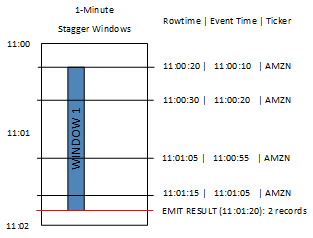
上圖有下列事件,這些事件輪轉窗口應用程式分析的相同:
| ROWTIME | EVENT_TIME | TICKER_SYMBOL |
|---|---|---|
| 11:00:20 | 11:00:10 | AMZN |
| 11:00:30 | 11:00:20 | AMZN |
| 11:01:05 | 11:00:55 | AMZN |
| 11:01:15 | 11:01:05 | AMZN |
來自交錯窗口應用程式的結果集類似如下。
| ROWTIME | EVENT_TIME | TICKER_SYMBOL | 計數 |
|---|---|---|---|
| 11:01:20 | 11:00:00 | AMZN | 3 |
| 11:02:15 | 11:01:00 | AMZN | 1 |
傳回的記錄聚合前三個輸入記錄。記錄會依一分鐘的交錯窗口來分組。當應用程式收到第一筆 AMZN 記錄 (其中 ROWTIME 為 11:00:20) 時,就會啟動交錯窗口。當 1 分鐘交錯窗口到期時 (11:01:20),會將包含落在交錯窗口內 (以 ROWTIME 和 EVENT_TIME 為基礎) 的結果的記錄寫入輸出串流。如使用交錯窗口,所有在一分鐘視窗內有 ROWTIME 和 EVENT_TIME 的記錄都會在單一結果中發出。
最後一筆記錄 (在一分鐘彙總外有 EVENT_TIME) 會分別彙總。這是因為 EVENT_TIME 是用來將記錄分隔成結果集的分割區索引鍵之一,而第一個視窗的 EVENT_TIME 分割區索引鍵是 11:00。
交錯窗口的語法是在特殊子句 WINDOWED BY 中定義的。使用此子句,而不是用於串流聚合的 GROUP BY 子句。子句會緊接顯示在選用 WHERE 子句之後,在 HAVING 子句之前。
交錯窗口在 WINDOWED BY 子句中定義,並採用兩個參數:分割區索引鍵和窗口長度。分割區索引鍵會分割傳入的資料串流,並定義窗口開啟的時間。當串流上出現具有唯一分割區索引鍵的第一個事件時,會開啟交錯窗口。交錯窗口會在窗口長度所定義的固定期間之後關閉。語法如下列程式碼範例所示:
... FROM <stream-name> WHERE <... optional statements...> WINDOWED BY STAGGER( PARTITION BY <partition key(s)> RANGE INTERVAL <window length, interval> );
