我們不再更新 Amazon Machine Learning 服務或接受新使用者。本文件可供現有使用者使用,但我們不再更新。如需詳細資訊,請參閱什麼是 Amazon Machine Learning。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
多類別模型深入分析
解譯預測
多類別分類演算法的實際輸出是一組預測「分數」。分數指出模型對於特定觀察屬於每個類別的確定程度。與二元分類問題不同的是,您不需要選擇分數截止值來進行預測。預測答案是具有最高預測分數的類別 (例如,標籤)。
衡量 ML 模型準確性
多類別中使用的典型指標在平均所有類別後所使用的指標和二元分類案例中使用的指標相同。在 Amazon ML 中,巨集平均 F1 分數用於評估多類別指標的預測準確性。
巨集平均 F1 分數
F1 分數是一個二元分類指標,同時參考二元指標精確度和取回。這是精確度和取回之間的調和平均數。範圍介於 0 至 1 之間。值越大,表示預測準確性越高:
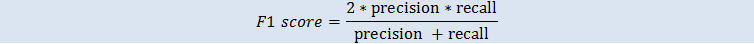
巨集平均 F1 分數是多類別案例中所有類別的 F1 分數未加權平均。它不將類別在評估資料集中的出現頻率列入考慮。值越大,表示預測準確性越高。以下範例顯示評估資料來源中的 K 類別:
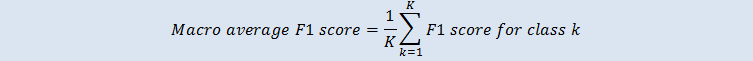
基準巨集平均 F1 分數
Amazon ML 為多類別模型提供基準指標。這是假設多類別模型的巨集平均 F1 分數,一律預測最頻繁的類別做為答案。例如,如果您要預測電影類型而您的訓練資料中最常見的類型是愛情片,則基準模型會一律將類型預測為愛情片。您應根據此基準來比較您的 ML 模型,以驗證您的 ML 模型是否比預測此固定答案的 ML 模型更佳。
使用效能視覺化
Amazon ML 提供混淆矩陣,做為視覺化多類別分類預測模型準確性的方法。混淆矩陣透過比較觀察的預估類別及其真正類別,以表格說明每個類別的正確和錯誤預測的數量或百分比。
例如,如果您嘗試將一部電影分類為類型,預測模型可能會將其類型 (類別) 預測為愛情片。不過,其真正類型實際上可能是驚悚片。當您評估多類別分類 ML 模型的準確性時,Amazon ML 會識別這些錯誤分類,並在混淆矩陣中顯示結果,如下圖所示。
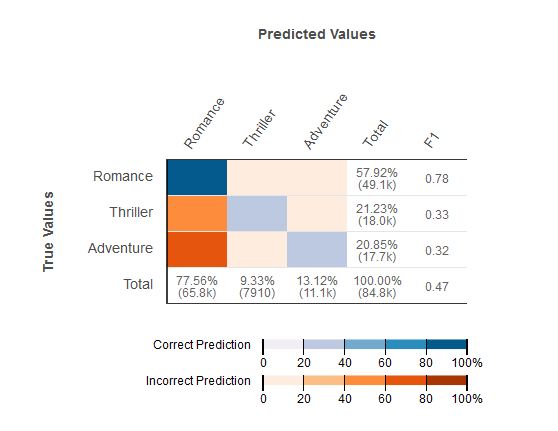
以下資訊會顯示在混淆矩陣中:
-
每個類別的正確和錯誤預測數:混淆矩陣中的每一列都對應至其中一個真正類別的指標。例如,第一列顯示實際是愛情片類型的電影,多類別 ML 模型取得超過 80% 的正確預測。它將類型錯誤預測為驚悚片不到 20%,冒險片也是少於 20%。
-
智慧類別 F1 分數:最後一欄顯示每個類別的 F1 分數。
-
評估資料中的真正類別頻率:倒數第二欄顯示在評估資料集內,評估資料中 57.92% 的觀察是愛情片、21.23% 是驚悚片、20.85% 是冒險片。
-
評估資料的預測類別頻率:最後一列顯示預測中每個類別的頻率。 77.56% 的觀察結果預測為浪漫,9.33% 預測為 Thriller,13.12% 預測為冒險。
Amazon ML 主控台提供視覺化顯示,最多可容納混淆矩陣中的 10 個類別,以評估資料中最常到最不頻繁類別的順序列出。如果您的評估資料有 10 個以上的類別,您會在混淆矩陣中看到前 9 個最常發生的類別,所有其他類別則會摺疊成名為「其他」的類別。Amazon ML 也提供透過多類別視覺化頁面上的連結下載完整混淆矩陣的功能。
