本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
參考架構
下圖顯示將本指南的自動化解決方案套用至每日操作報告後的工作流程。當新檔案擷取到 Amazon Simple Storage Service (Amazon S3) 時,可以在處理後立即在 QuickSight 儀表板中視覺化。
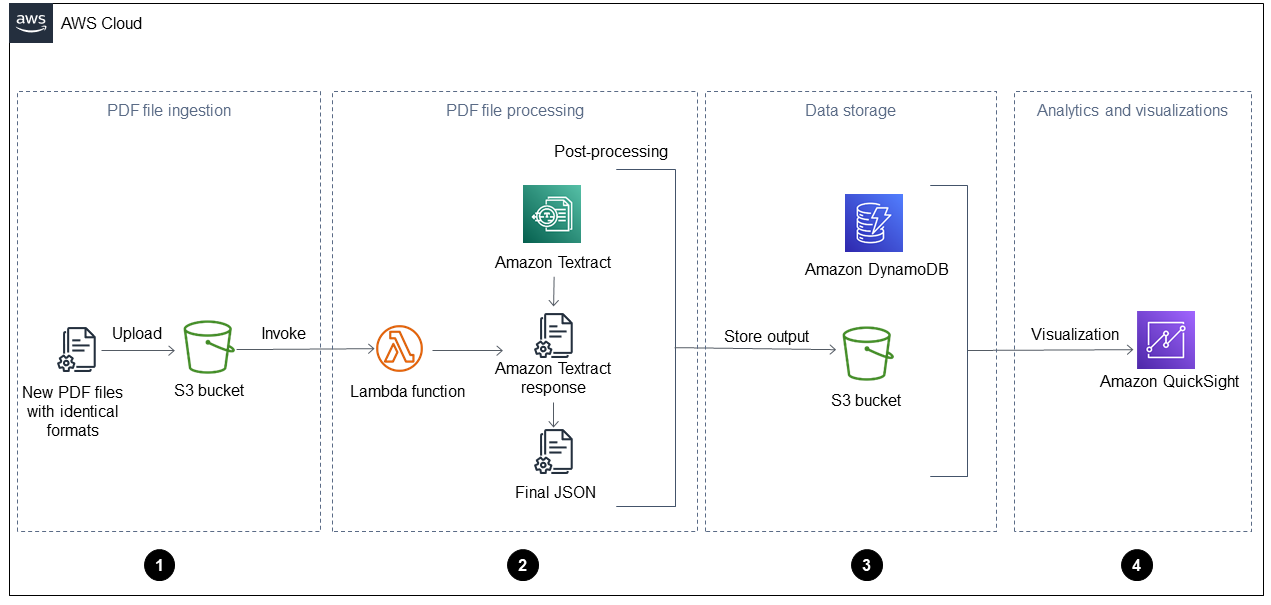
圖表顯示下列四個階段:
-
PDF 檔案擷取 – 您的應用程式會自動將格式相同的新 PDF 檔案 (例如,每日操作報告) 擷取至 Amazon Simple Storage Service (Amazon S3) 儲存貯體。Amazon S3 會在新的 PDF 檔案新增至儲存貯體並叫用 AWS Lambda 函數時啟動
ObjectCreated事件。如需詳細資訊,請參閱《Amazon S3 文件》中的使用 Amazon S3 觸發叫用 Lambda 函數。 Amazon S3 -
PDF 檔案處理 – Lambda 函數會將一個 PDF 檔案傳送至 Amazon Textract,以擷取內容。後置處理指令碼會執行和剖析 Amazon Textract 回應,並針對此類型的 PDF 檔案使用預先定義的範本。此範本包含正確的屬性,並有助於正確擷取所有鍵值對、資料表和其他原始文字。如需詳細資訊,請參閱 AWS 規範指引網站上的使用 Amazon Textract 從 PDF 檔案自動擷取內容的模式。
-
資料儲存 – 除了每個 PDF 檔案的 JSON 檔案之外,擷取和更正的資料也會儲存在 Amazon DynamoDB 資料表中。JSON 檔案存放在 S3 儲存貯體中,可供下游處理和分析服務使用,例如 Amazon Athena、QuickSight 或 Amazon SageMaker AI。
-
分析和視覺化 – QuickSight 會分析資料並建立視覺化,以協助產生所有已處理 PDF 檔案的洞見。在 QuickSight 中建立儀表板後,您可以與最終使用者和業務團隊共用。
考量事項
本指南的解決方案適用於處理格式相同且表單和資料表配置一致的 PDF 檔案。不過,您必須預先定義範本並進行編輯,才能完全自動化程序,並讓擷取的資料可用於分析。然後,在處理 Lambda 函數時使用此範本。
雖然此解決方案可同時套用至不同的 PDF 檔案類型,但您必須為每個 PDF 檔案類型建立和定義個別範本,並將其存放在可存取的位置 (例如 Amazon S3)。我們建議您為每個 PDF 檔案類型使用唯一的識別符,例如 PDF 檔案名稱或 S3 儲存貯體中的不同資料夾。然後,Lambda 函數可以在處理 PDF 檔案類型時呼叫適當的範本。
