本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
用於預測貨運需求的機器學習模型
下圖展示了訓練資料的範例。目標是您要預測的,相關的時間序列 1 和 2 是與預測目標相關的輸入特徵。歷史資料用於訓練和驗證,而您保留一段時間的歷史資料以進行模型驗證。
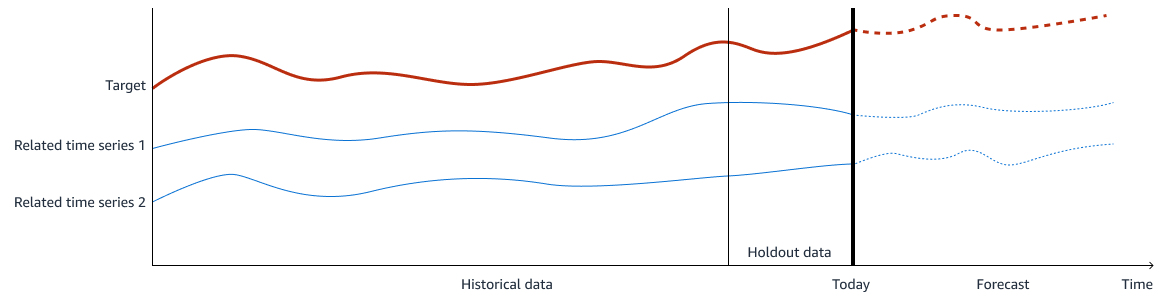
在需求預測中,輸出 (或目標) 是您要預測的需求量。輸入特徵是與輸出相關的時間序列資料。若要訓練 ML 模型以準確預測需求量,解決方案中需要兩種機器學習模型。第一個模型會針對輸入圖徵 (包括內部與外部資料) 進行時間序列預測。第二個模型會使用所有功能來進行最終需求預測。透過將這兩個模型結合在一起,您可以有效地擷取時間序列趨勢,以及目標與輸入之間的關係。
用於輸入特徵預測的 ML 模型
輸入功能包括內部和外部歷史時間序列資料。若要針對每個功能進行預測,您可以使用一維 (1D) 時間序列模型。有各種可用的算法。例如,最Prophet
目標變數預測的 ML 模型
輸出的 ML 模型或需求量是為了擷取所有特徵與輸出之間的關係而建置。您可以使用各種受監督的迴歸模型lasso,例如ridge regressionrandom forest、、和XGBoost。建立模型並尋找最佳參數和超參數時,您可以使用保留資料。Holdout 資料是從資料集中保留的歷史標籤資料的一部分,用於訓練機器學習模型。您可以使用保留資料來評估模型效能,方法是將預測與保留資料進行比較。
