本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
資料準備和清理
資料準備和清理是資料生命週期中最重要且耗時的階段之一。下圖顯示資料準備和清理階段如何符合資料工程自動化和存取控制生命週期。
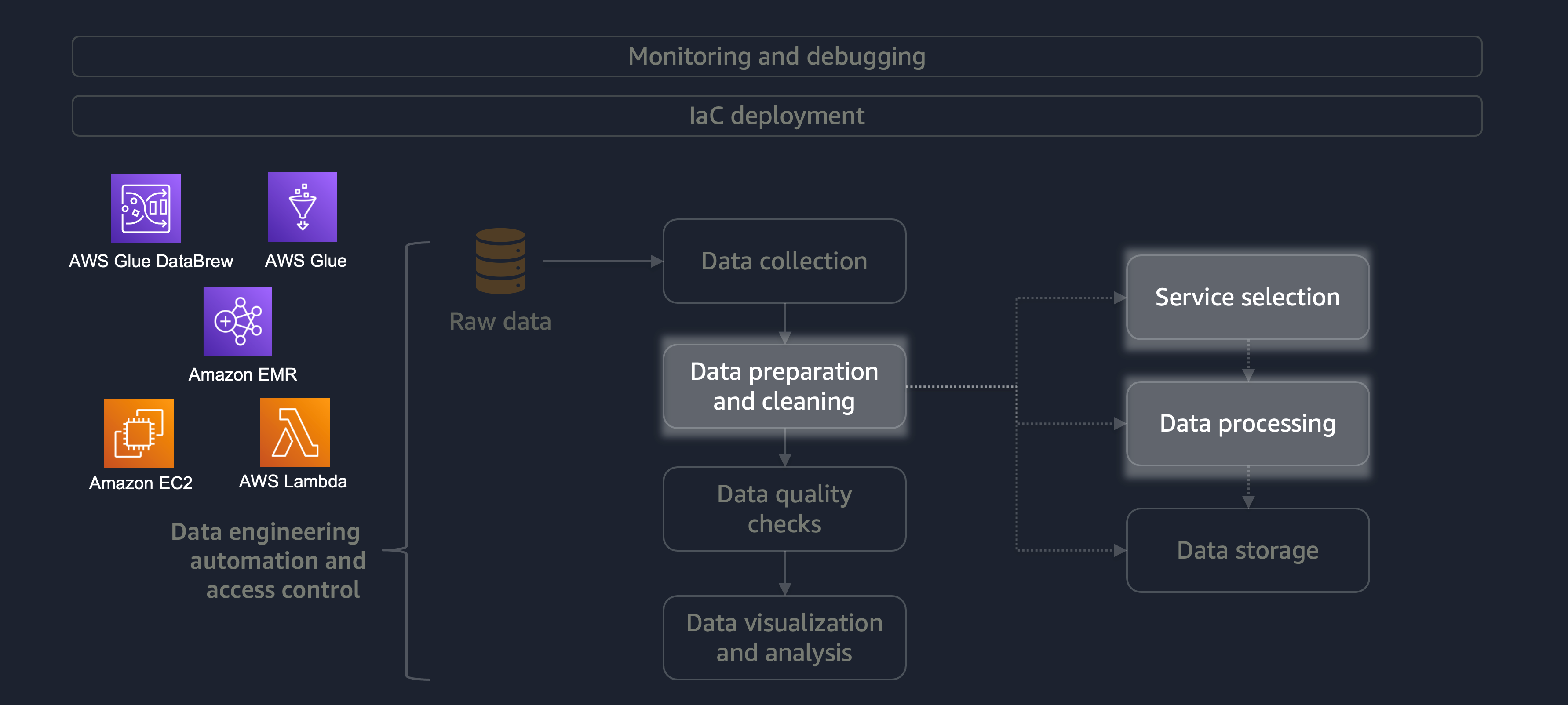
以下是一些資料準備或清理的範例:
-
將文字資料欄映射至程式碼
-
忽略空白資料欄
-
使用
0、None或 填入空白資料欄位'' -
匿名化或遮罩個人身分識別資訊 (PII)
如果您有具有各種資料的大型工作負載,建議您使用 Amazon EMRDataFrame或 DynamicFrame 來使用水平處理。此外,您可以使用 AWS Glue DataBrew
對於不需要分散式處理且可在 15 分鐘內完成的小型工作負載,我們建議您使用 AWS Lambda
務必選擇正確的 AWS 服務進行資料準備和清理,並了解您選擇的相關權衡。例如,假設您是從 AWS Glue、DataBrew 和 Amazon EMR 中選擇的案例。如果 ETL 任務不常發生,則 AWS Glue 是理想的選擇。不常發生的任務會每天執行一次、每週執行一次,或每月執行一次。您可以進一步假設您的資料工程師熟練撰寫 Spark 程式碼 (適用於大數據使用案例) 或一般編寫指令碼。如果任務更頻繁,持續執行 AWS Glue 可能會變得昂貴。在此情況下,Amazon EMR 提供分散式處理功能,並提供無伺服器和伺服器型版本。如果您的資料工程師沒有適當的技能或您必須快速交付結果,則 DataBrew 是不錯的選擇。DataBrew 可以減少開發程式碼的工作量,並加速資料準備和清理程序。
處理完成後,ETL 程序的資料會存放在 AWS 上。儲存體的選擇取決於您正在處理的資料類型。例如,您可以處理非關聯式資料,例如圖形資料、鍵值對資料、影像、文字檔案或關聯式結構化資料。
如下圖所示,您可以使用下列 AWS 服務進行資料儲存:
-
Amazon S3
存放非結構化資料或半結構化資料 (例如 Apache Parquet 檔案、映像和影片)。 -
Amazon Neptune
存放圖形資料集,您可以使用 SPARQL 或 GREMLIN 查詢。 -
Amazon Keyspaces (適用於 Apache Cassandra)
存放與 Apache Cassandra 相容的資料集。 -
Amazon Aurora
會存放關聯式資料集。 -
Amazon DynamoDB
會將索引鍵值或文件資料存放在 NoSQL 資料庫中。 -
Amazon Redshift
會將結構化資料的工作負載存放在資料倉儲中。
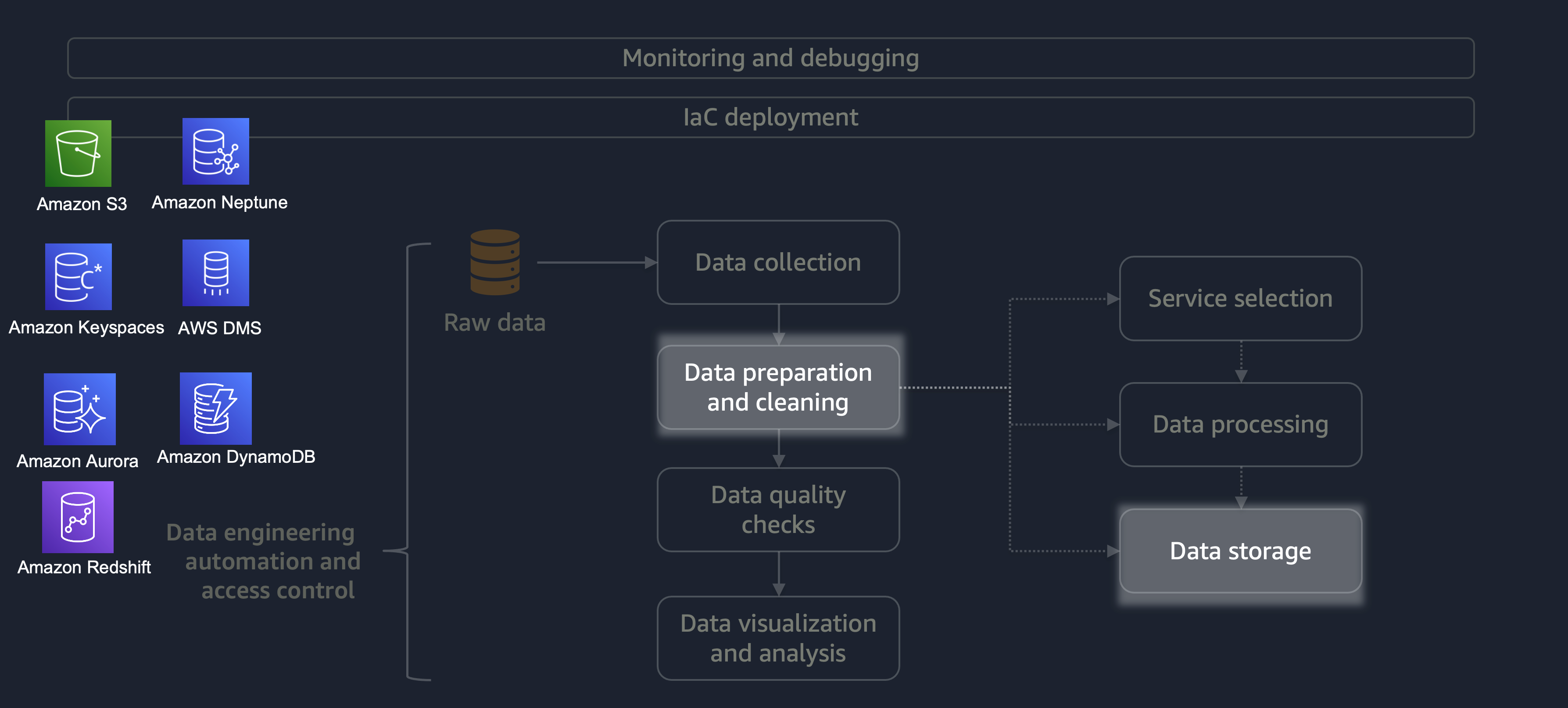
透過使用正確的服務搭配正確的組態,您可以以最有效率且最有效的方式存放資料。這可將資料擷取所涉及的工作量降至最低。
