本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
效能效率支柱
AWS Well-Architected Framework 的效能效率支柱著重於如何在擷取或查詢資料時最佳化效能。效能最佳化是下列的增量和持續程序:
-
確認業務需求
-
測量工作負載效能
-
識別效能不佳的元件
-
調校元件以符合您的業務需求
效能效率支柱提供使用案例特定的指導方針,可協助您識別要使用的正確圖形資料模型和查詢語言。它還包含從 Neptune Analytics 擷取資料和取用資料的最佳實務。
效能效率支柱著重於下列關鍵領域:
-
圖形建模
-
查詢最佳化
-
圖形大小正確
-
寫入最佳化
了解用於分析的圖形建模
本指南套用適用於 Amazon Neptune 的 AWS Well-Architected Framework 討論圖形建模以提高效能效率。影響效能的建模決策包括選擇需要哪些節點和邊緣、其 IDs、其標籤和屬性、邊緣方向、標籤是否應該是一般或特定,以及查詢引擎可以導覽圖形來處理常見查詢的效率。
這些考量也適用於 Neptune Analytics;不過,請務必區分交易和分析用量模式。對 Neptune 資料庫等交易資料庫中的查詢有效率的圖形模型可能需要重新塑造以進行分析。
例如,請考慮 Neptune 資料庫中的詐騙圖表,其目的是檢查信用卡付款中的詐騙模式。此圖表可能有節點代表帳戶和付款的帳戶、付款和功能 (例如電子郵件地址、IP 地址、電話號碼)。此連線圖形支援查詢,例如周遊從指定付款開始的可變長度路徑,並需要數次跳轉來尋找相關功能和帳戶。下圖顯示這類圖形。
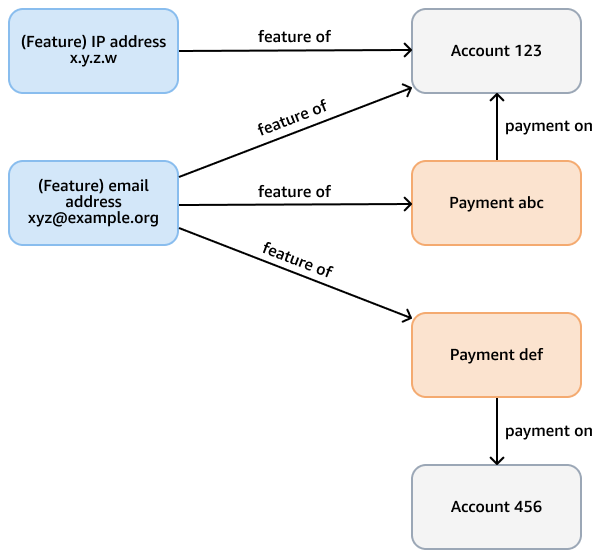
分析需求可能更具體,例如尋找由功能連結的帳戶社群。您可以為此目的使用連線較弱的元件 (WCC) 演算法。若要針對上一個範例中的模型執行,效率很低,因為它需要周遊多種不同類型的節點和邊緣。下圖中的模型更有效率。如果帳戶本身或從帳戶付款共用功能,它會將account節點與shares feature邊緣連結。例如, Account 123具有電子郵件功能 xyz@example.org,Account 456並使用相同的電子郵件進行付款 (Payment def)。

WCC 的運算複雜性為 O(|E|logD),其中 |E|是圖形中的邊緣數量,而 D是連接節點的直徑 (最長路徑的長度)。由於交易模型會省略正位節點和邊緣,因此會同時最佳化邊緣和直徑,並減少 WCC 演算法的複雜性。
當您使用 Neptune Analytics 時,請復原所需的演算法和分析查詢。如有必要,請重塑模型以最佳化這些查詢。您可以在將資料載入圖形之前重塑模型,或寫入修改圖形中現有資料的查詢。
最佳化查詢
請遵循這些建議來最佳化 Neptune Analytics 查詢:
-
使用參數化查詢和預設啟用的查詢計畫快取。當您使用計劃快取時,引擎會準備查詢以供日後使用,前提是查詢會在 100 毫秒或更短時間內完成,以節省後續調用的時間。
-
對於慢查詢,請執行解釋計劃來發現瓶頸並相應地進行改進。
-
如果您使用向量相似性搜尋,請決定較小的內嵌是否產生準確的相似性結果。您可以更有效率地建立、存放和搜尋較小的內嵌。
-
遵循 Neptune Analytics 中使用 openCypher 的記錄最佳實務。例如,在 UNWIND 子句中使用平面貼圖,並盡可能指定邊緣標籤。
-
當您使用圖形演算法時,請了解演算法的輸入和輸出、其運算複雜性,以及其運作方式。
-
呼叫圖形演算法之前,請使用
MATCH子句將輸入節點集降至最低。例如,若要限制節點從中執行廣度優先搜尋 (BFS),請遵循 Neptune Analytics 文件中提供的範例。 -
盡可能篩選節點和邊緣標籤。例如,BFS 具有輸入參數來篩選特定節點標籤 (
vertexLabel) 或特定邊緣標籤 () 的周遊edgeLabels。 -
使用 等週框參數
maxDepth來限制結果。 -
使用
concurrency參數進行實驗。嘗試使用值 0,這會使用所有可用的演算法執行緒來平行處理。透過將 參數設定為 1,將 與單執行緒執行進行比較。演算法可以在單一執行緒中更快速地完成,尤其是在較小型的輸入上,例如淺廣度優先搜尋,其中平行處理不會提供可測量的執行時間減少,而且可能會帶來額外負荷。 -
在類似的演算法類型之間進行選擇。例如,Bellman-Ford 和 delta-stepping 都是單一來源最短路徑演算法。使用您自己的資料集進行測試時,請嘗試兩種演算法並比較結果。Delta 步進通常比 Bellman-Ford 更快,因為運算複雜性較低。不過,效能取決於資料集和輸入參數,特別是
delta參數。
-
最佳化寫入
請遵循下列實務,在 Neptune Analytics 中最佳化寫入操作:
-
尋求將資料載入圖形的最有效方式。當您從 Amazon S3 中的資料載入時,如果資料大小大於 50 GB,請使用大量匯入。對於較小的資料,請使用批次載入。如果您在執行批次載入時遇到out-of-memory錯誤,請考慮增加 m-NCU 值或將載入分割為多個請求。其中一種方法是將檔案分割到 S3 儲存貯體中的多個字首。在這種情況下,請針對每個字首分別呼叫批次載入。
-
使用大量匯入或批次載入器來填入初始一組圖形資料。僅針對小型變更使用交易型 openCypher 建立、更新和刪除操作。
-
使用大量匯入或並行 1 (單一執行緒) 的批次載入器,將內嵌擷取至圖形。嘗試使用其中一種方法來預先載入內嵌。
-
評估向量相似性搜尋演算法中精確相似性搜尋所需的向量內嵌維度。如果可能,請使用較小的維度。這會導致內嵌的載入速度更快。
-
如有需要,請使用變動演算法來記住演算法結果。例如,程度變動中心演算法會尋找每個輸入節點的程度,並將該值寫入為節點的屬性。如果這些節點周圍的連線之後未變更, 屬性會保留正確的結果。您不需要再次執行演算法。
-
如果您需要重新開始,請使用圖形重設管理動作來清除所有節點、邊緣和內嵌。如果您的圖形很大,則無法使用 openCypher 查詢捨棄所有節點、邊緣和內嵌。大型資料集上的單一捨棄查詢可能會逾時。隨著大小的增加,資料集需要更長的時間才能移除,交易大小也會增加。相反地,完成圖形重設的時間大約是固定的,而 動作會提供在執行快照之前建立快照的選項。
適當大小的圖形
整體效能取決於 Neptune Analytics 圖形的佈建容量。容量的測量單位稱為記憶體最佳化 Neptune 容量單位 (m-NCUs)。請確定您的圖形大小足以支援您的圖形大小和查詢。請注意,增加的容量不一定能改善個別查詢的效能。
如果可能,從 Amazon S3 或現有的 Neptune 叢集或快照等現有來源匯入資料,以建立圖形。您可以將邊界放在最小和最大容量上。您也可以變更現有圖形上的佈建容量。
監控 CloudWatch 指標,例如 NumQueuedRequestsPerSec、GraphSizeBytes、、 NumOpenCypherRequestsPerSec GraphStorageUsagePercent和 CPUUtilization,以評估圖形的大小是否正確。判斷是否需要更多容量來支援您的圖形大小和負載。如需如何解譯其中一些指標的詳細資訊,請參閱卓越營運支柱一節。
