本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 中使用聯結提示 Spark SQL
使用 Spark3.0,您可以指定Spark要在執行時間使用的聯結演算法類型。聯結策略提示 、SHUFFLE_HASH、 BROADCAST MERGE和 SHUFFLE_REPLICATE_NL會指示 在與其他關係聯結時Spark,在每個指定的關係上使用提示策略。本節詳細討論聯結策略提示。
BROADCAST
在廣播雜湊聯結中,其中一個資料集明顯小於另一個資料集。由於較小的資料集可以容納在記憶體中,因此會廣播到叢集中的所有執行器。廣播資料後,會執行標準雜湊聯結。廣播雜湊聯結分為兩個步驟:
-
廣播 – 較小的資料集會廣播到叢集中的所有執行器。
-
雜湊聯結 – 較小的資料集會在所有執行器間雜湊,然後使用較大的資料集聯結。
沒有 sort或 merge操作。將具有較小維度資料表的大型事實資料表聯結以執行星狀結構描述聯結時,廣播雜湊是最快的聯結演算法。下列範例示範廣播雜湊聯結的運作方式。無論 spark.sql.autoBroadcastJoinThreshold 屬性中指定的大小限制為何,都會廣播具有提示的聯結端。如果聯結的兩端都有廣播提示,則會廣播具有較小大小 (根據統計資料) 的提示。spark.sql.autoBroadcastJoinThreshold 屬性的預設值為 10 MB。這會為在執行聯結時廣播至所有工作者節點的資料表設定大小上限,以位元組為單位。
下列範例提供查詢、實體EXPLAIN計畫,以及查詢執行所需的時間。如果您使用BROADCASTJOIN提示來強制廣播聯結,查詢需要較少的處理時間,如第二個範例EXPLAIN計劃所示。
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
當兩個資料集都很大且無法放入記憶體時,偏好使用隨機排序合併聯結。如名稱所示,此聯結包含下列三個階段:
-
隨機播放階段 – 聯結查詢中的兩個資料集都會隨機播放。
-
排序階段 – 記錄會依兩側的聯結索引鍵排序。
-
合併階段 – 根據聯結金鑰,反覆運算聯結條件的兩側。
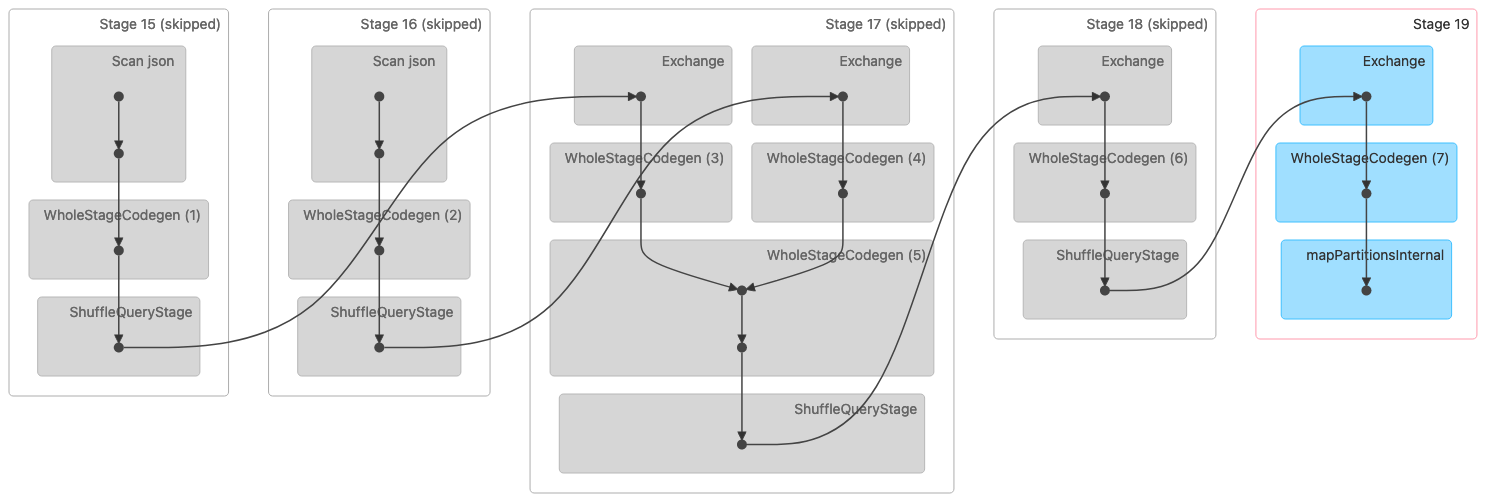
下圖顯示隨機排序合併聯結的定向無環圖 (DAG) 視覺化。這兩個資料表會在前兩個階段讀取。在下一個階段 (第 17 階段) 中,它們會隨機播放、排序,然後在最後合併在一起。
注意:此影像中的某些階段顯示為略過,因為這些步驟已在先前的階段完成。該資料已快取或保留以供這些階段使用。 |
以下是指出排序合併聯結的實體計劃。
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
如名稱所示,隨機播放雜湊聯結的運作方式是隨機播放這兩個資料集。來自兩側的相同金鑰最終會位於相同的分割區或任務中。資料隨機播放後,兩個資料集中最小的資料集會雜湊到儲存貯體中,然後在分割區中執行雜湊聯結。隨機雜湊聯結與廣播雜湊聯結不同,因為整個資料集不會廣播。隨機雜湊聯結分為兩個階段:
-
隨機播放階段 – 兩個資料集都會隨機播放。
-
雜湊聯結階段 – 資料較小的一端會經過雜湊處理、儲存,然後在所有分割區中加入較大一端的雜湊。
在分割區內加入隨機雜湊時,不需要排序。下圖顯示隨機雜湊聯結的階段。資料一開始會讀取,然後隨機播放,然後建立雜湊並用於聯結。
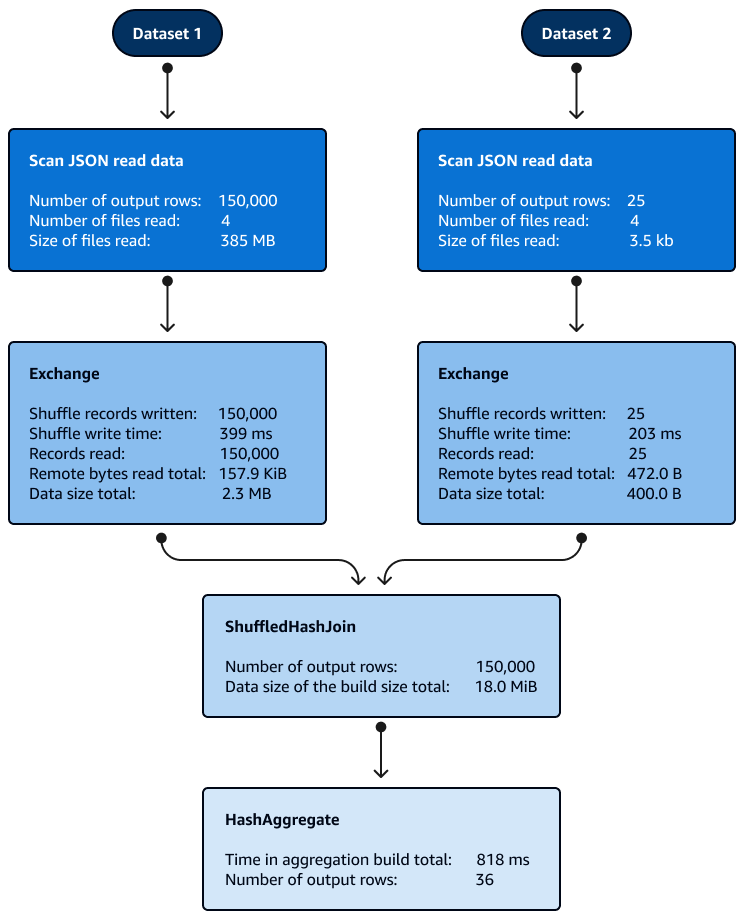
根據預設,當無法使用廣播雜湊聯結時,最佳化工具會選擇隨機雜湊聯結。根據廣播雜湊聯結閾值大小 (spark.sql.autoBroadcastJoinThreshold) 和所選隨機播放分割區的數量 (spark.sql.shuffle.partitions),當邏輯 SQL 的單一分割區夠小而無法建置本機雜湊資料表時,它會使用隨機播放雜湊聯結。
SHUFFLE_REPLICATE_NL
Shuffle-and-Replicate巢狀迴圈聯結也稱為笛卡爾產品聯結,運作方式非常類似廣播雜湊聯結,但資料集未廣播。
在此聯結演算法中,隨機播放不會參考真正的隨機播放,因為具有相同金鑰的記錄不會傳送至相同的分割區。反之,兩個資料集的整個分割區都會透過網路複製。當資料集中的分割區可用時,會執行巢狀迴圈聯結。如果第一個資料集中有記錄X數,且每個分割區中的第二個資料集中有記錄Y數,則第二個資料集中的每個記錄都會與第一個資料集中的每個記錄聯結。這會在每個分割區的循環X × Y時間繼續。
