本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
現代運作狀態資料策略的範例實作
AWS 提供參考架構,供醫療保健組織用來了解和建置支援敏捷資料方法的資料平台。下列參考架構說明醫療保健的資料網格架構
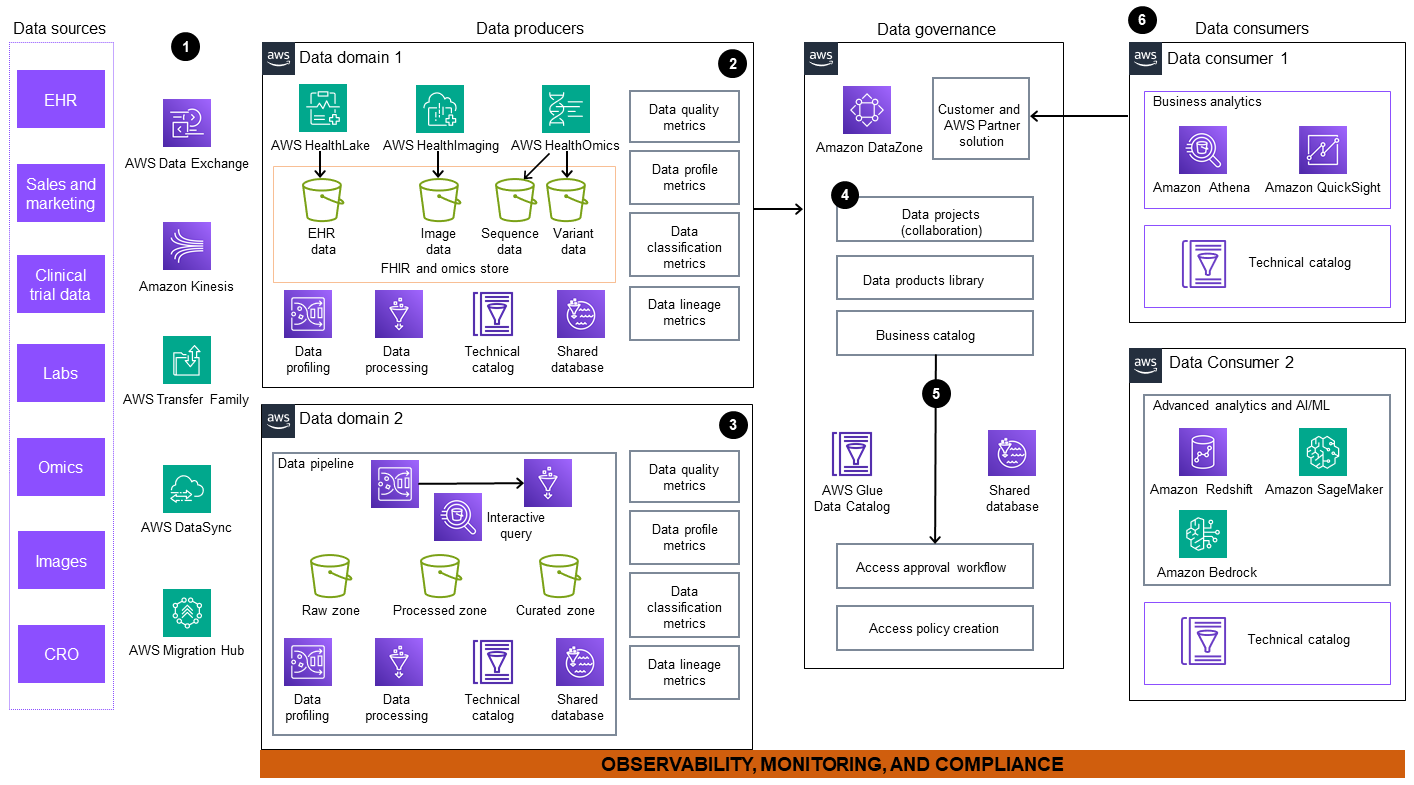
架構圖包含下列元件:
-
從外部和內部資料來源擷取資料。這些來源包括但不限於電子健康記錄 (EHR) 系統、實驗室、排序設施和影像中心。 AWS 提供一套服務,例如 AWS Data Exchange
、Amazon Kinesis 、AWS Transfer Family 、AWS Migration Hub 、 AWS DataSync AWS HealthLake 和 AWS Glue (ETL)。您可以使用這些服務來協助遷移內部資料集,以及同時訂閱內部和外部資料集。 -
資料網域 1 包含用於處理多模式患者導向資料的全方位工作流程,包括臨床資料、影像資料和影像資料。EHR 臨床資料會擷取並存放在 HealthLake 資料存放區中,這是專門為臨床資料建置的受管服務。 AWS HealthOmics
是專門為模擬資料建置的服務,可處理序列和變體存放區和工作流程。影像資料會擷取並存放在 中AWS HealthImaging 。然後,此資料會轉換為可立即使用的產品,並在企業資料市場中發佈,以供廣泛存取和使用。 -
在資料網域 2、Amazon Kinesis 和 AWS Data Exchange 中 AWS Glue,將原始資料擷取至資料管道。資料的來源可能包括公有登錄檔、遠端患者監控和企業資源規劃 (ERP) 程式。管道會將原始資料載入 Amazon Simple Storage Service (Amazon S3)
儲存貯體。此資料經過清理、整理、轉換和儲存,以做為資料產品發佈。Amazon Athena 提供互動式查詢引擎,資料生產者可以使用該引擎來轉換使用 SQL 的資料。 AWS Glue DataBrew 提供視覺化資料轉換、標準化和分析功能。 -
Amazon DataZone
會處理中繼資料、協作資料專案和資料產品程式庫發佈至中央商業目錄。 -
統一的資料分析入口網站透過聯合控管提供資料產品的檢視,以促進資料周圍的協作。Amazon DataZone 以 為 AWS Glue Data Catalog 後端啟用自助式工作流程 AWS Lake Formation,讓使用者可以共用、搜尋、探索資料和請求取用許可。
-
資料取用者可以存取資料、建立下游檢視,並使用 Amazon Athena、Amazon QuickSight
、Amazon Redshift 、Amazon SageMaker AI 和 Amazon Bedrock 等專門建置的工具來執行下列動作: -
操作分析
-
臨床資訊學
-
研究
-
患者和臨床參與
資料消費者也可以使用生成式 AI 開發創新應用程式,而且可以將資料產品發佈到商業目錄。
-
如需資料網格架構的詳細資訊,請參閱什麼是資料網格?
生成式 AI
醫療保健組織正在為各種應用程式使用生成式 AI,從自動化醫療影像解釋到根據影像和文字資料產生診斷建議和治療計劃。採用生成式 AI 可加速創新並提高整個護理連續性的效率。對生成式 AI 的新重點迫使醫療保健擴展其資料焦點,以包含更多形式的非結構化資料,擴展 AI 適用的使用案例數量和種類。一般而言,組織可以根據其使用案例選擇四種模式,以實作生成式 AI 解決方案:
-
提示詞工程 – 在提示詞工程中,使用者提供相關資料作為內容,引導生成式 AI 模型建立他們想要的內容。具有現代運作狀態資料策略的組織可以確保相關資料易於探索、共用和消耗。
-
擷取增強產生 (RAG) – RAG 模式建置在提示詞工程上。程式會攔截使用者的問題或輸入,而不是提供相關資料的使用者。程式會在資料儲存庫中搜尋,以擷取與問題或輸入相關的內容。程式會將找到的資料提供給生成式 AI 模型,以產生內容。現代醫療保健資料策略可實現企業資料的策劃和索引。然後,可以搜尋資料並用作提示或問題的內容,協助大型語言模型 (LLM) 產生回應。
您的組織可以使用下列兩種模式,將生成式 AI 模型輸出集中在產生適合其資料內容的內容上。
-
微調 - 使用此模式,您的組織可以透過自訂生成式 AI 模型進一步邁進。這包括根據組織特有的少量資料範例微調模型。由於樣本大小很小,因此此模式可提供成本和自訂的平衡。為了避免模型輸出中的偏差,請使用盡可能多樣化且代表組織資料模式的小型範例資料集。現代運作狀態資料策略支援有效存取各種資料,以準備範例資料集。
-
建置您自己的模型 – 如果您的組織需要跨高度專業化的大量資料產生內容,且先前的三種模式不夠,您可以建置自己的模型。
現代資料策略在生成式 AI 解決方案中扮演關鍵角色,協助確保資料具有下列特性:
-
支援準確度的高品質資料
-
即時或近乎即時的資料,以協助確保模型輸出相關
-
跨各種資料來源的多種資料模式,讓模型能夠存取豐富的資料集以產生內容
下圖顯示現代運作狀態資料策略的實作,該策略使用資料網格架構來支援生成式 AI 解決方案。
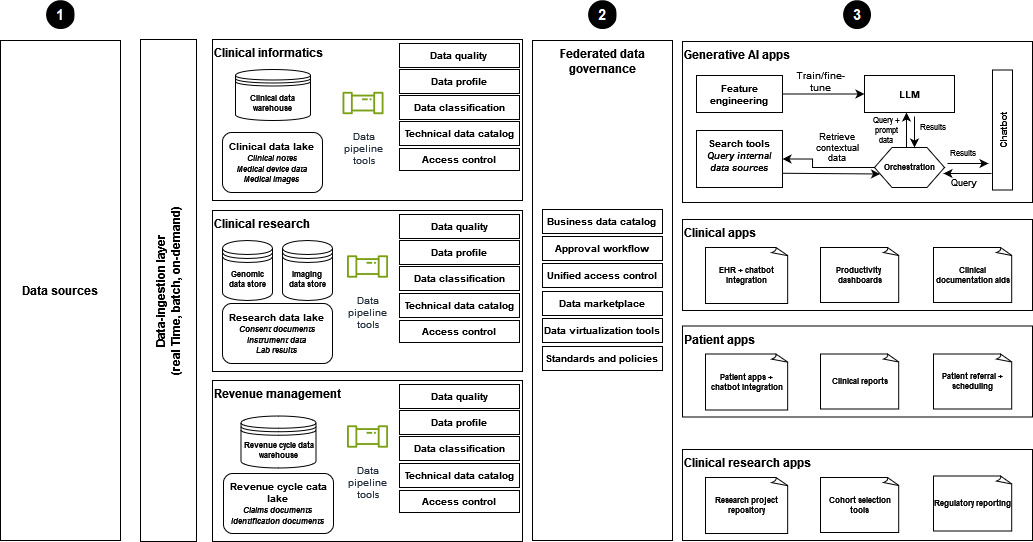
-
資料是從臨床資訊學、臨床研究和營收管理網域中的各種資料來源擷取,資料可供醫療保健組織使用。
-
聯合資料控管有助於確保資料共用和統一存取的嚴格存取控制。
-
資料取用者包括下列項目:
-
生成式 AI 應用程式,特別是使用資料來訓練和微調 LLMs的應用程式。這些應用程式使用企業資料進行 Q&A 聊天機器人,以提高營運效率,以及患者和提供者的體驗。
-
臨床應用程式配備 EHR 整合聊天機器人、生產力儀表板和文件輔助等工具。
-
以病患為中心的應用程式,可改善病患體驗。這些應用程式具有聊天機器人互動、臨床報告,以及高效的推薦和排程程序。
-
具有研究專案儲存庫和應用程式,專為群組分析和法規報告而設計的 臨床研究。
-
透過此架構,組織中的利益相關者可以專注於策劃和管理他們從其他來源收集的資料,同時讓組織的其他成員可以存取自己的資料。他們可以使用聯合資料控管層中可用的工具來定義中繼資料、管理存取核准工作流程,以及定義和強制執行政策。此外,聯合資料控管層提供集中式存取控制。這會建立環境來策劃各種資料來源,並以指定頻率重新整理高品質資料資產以維持相關性。 AWS 提供一組完整的功能,可滿足您的生成式 AI 需求。Amazon Bedrock
