本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
上可擴展 Web 爬蟲系統的架構 AWS
下列架構圖顯示 Web 爬蟲程式系統,其設計旨在以符合道德的方式從網站擷取環境、社交和管理 (ESG) 資料。您可以使用針對 AWS 基礎設施最佳化的 Python型爬蟲程式。您可以使用 AWS Batch 來協調大規模爬蟲任務,並使用 Amazon Simple Storage Service (Amazon S3) 進行儲存。下游應用程式可以從 Amazon S3 儲存貯體擷取和存放資料。
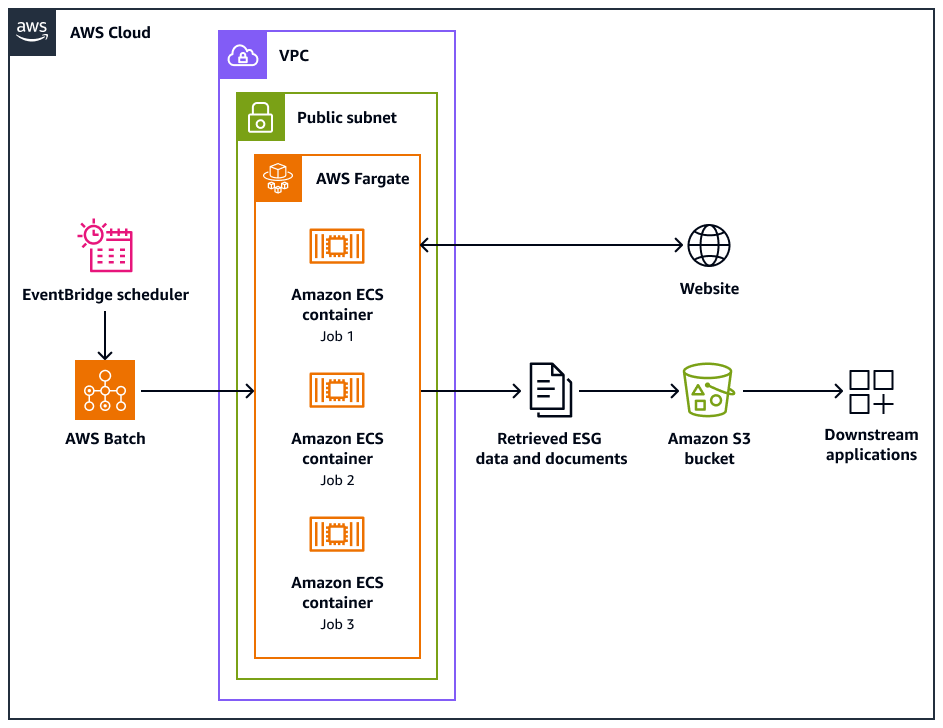
該圖顯示以下工作流程:
-
Amazon EventBridge 排程器會以您排程的間隔啟動爬取程序。
-
AWS Batch 管理 Web 爬蟲程式任務的執行。 AWS Batch 任務佇列會保留和協調待定的爬蟲任務。
-
Web 爬取任務會在 Amazon Elastic Container Service (Amazon ECS) 容器中執行 AWS Fargate。任務會在虛擬私有雲端 (VPC) 的公有子網路中執行。
-
Web 爬蟲程式會爬取目標網站,並擷取 ESG 資料和文件,例如 PDF、CSV 或其他文件檔案。
-
Web 爬蟲程式會將擷取的資料和原始檔案存放在 Amazon S3 儲存貯體中。
-
其他系統或應用程式會擷取或處理 Amazon S3 儲存貯體中儲存的資料和檔案。
Web 爬蟲程式設計和操作
有些網站專為在桌上型電腦或行動裝置上執行而設計。Web 爬蟲程式旨在支援使用桌面使用者代理程式或行動使用者代理程式。這些客服人員可協助您成功向目標網站提出請求。
初始化 Web 爬蟲程式之後,它會執行下列操作:
-
Web 爬蟲程式會呼叫
setup()方法。此方法會擷取和剖析 robots.txt 檔案。注意
您也可以設定 Web 爬蟲程式來擷取和剖析網站地圖。
-
Web 爬蟲程式會處理 robots.txt 檔案。如果在 robots.txt 檔案中指定爬蟲延遲,Web 爬蟲程式會擷取桌面使用者代理程式的爬蟲延遲。如果未於 robots.txt 檔案中指定爬蟲程式延遲,則 Web 爬蟲程式會使用隨機延遲。
-
Web 爬蟲程式會呼叫
crawl()方法,以啟動爬蟲程序。如果佇列中沒有 URLs,則會新增開始 URL。注意
爬蟲程式會持續進行,直到達到最大頁數或耗盡要爬蟲URLs。
-
爬蟲程式會處理 URLs。對於佇列中的每個 URL,爬蟲程式會檢查 URL 是否已爬取。
-
如果尚未抓取 URL,爬蟲程式會呼叫
crawl_url()方法,如下所示:-
爬蟲程式會檢查 robots.txt 檔案,以判斷是否可以使用桌面使用者代理程式來爬取 URL。
-
如果允許,爬蟲程式會嘗試使用桌面使用者代理程式來抓取 URL。
-
如果不允許或桌面使用者代理程式無法爬取,則爬蟲程式會檢查 robots.txt 檔案,以判斷是否可以使用行動使用者代理程式來爬取 URL。
-
如果允許,爬蟲程式會嘗試使用行動使用者代理程式來抓取 URL。
-
-
爬蟲程式會呼叫
attempt_crawl()方法,以擷取和處理內容。爬蟲程式會將 GET 請求傳送至具有適當標頭的 URL。如果請求失敗,爬蟲程式會使用重試邏輯。 -
如果檔案是 HTML 格式,爬蟲程式會呼叫
extract_esg_data()方法。它使用 Beautiful Soup來剖析 HTML 內容。它使用關鍵字比對來擷取環境、社交和管理 (ESG) 資料。 如果檔案是 PDF,爬蟲程式會呼叫
save_pdf()方法。爬蟲程式會下載 PDF 檔案並將其儲存至 Amazon S3 儲存貯體。 -
爬蟲程式會呼叫
extract_news_links()方法。這會尋找並儲存新聞文章、新聞發佈和部落格文章的連結。 -
爬蟲程式會呼叫
extract_pdf_links()方法。這會識別並存放 PDF 文件的連結。 -
爬蟲程式會呼叫
is_relevant_to_sustainable_finance()方法。這會使用預先定義的關鍵字,檢查新聞或文章是否與永續金融相關。 -
每次爬蟲嘗試後,爬蟲程式會使用
delay()方法實作延遲。如果在 robots.txt 檔案中指定了延遲,則會使用該值。否則,它會使用介於 1 到 3 秒之間的隨機延遲。 -
爬蟲程式會呼叫
save_esg_data()方法,將 ESG 資料儲存至 CSV 檔案。CSV 檔案會儲存在 Amazon S3 儲存貯體中。 -
爬蟲程式會呼叫
save_news_links()方法,將新聞連結儲存到 CSV 檔案,包括相關性資訊。CSV 檔案會儲存在 Amazon S3 儲存貯體中。 -
爬蟲程式會呼叫
save_pdf_links()方法,將 PDF 連結儲存至 CSV 檔案。CSV 檔案會儲存在 Amazon S3 儲存貯體中。
批次處理和資料處理
爬蟲程序是以結構化的方式組織和執行。 AWS Batch 會為每個公司指派任務,以便它們以批次方式平行執行。每個批次都著重於單一公司的網域和子網域,因為您已在資料集中識別它們。不過,相同批次中的任務會依序執行,因此不會讓網站產生太多請求。這有助於應用程式更有效率地管理爬取工作負載,並確保為每個公司擷取所有相關資料。
透過將 Web 爬取組織成公司特定的批次,此容器會將收集的資料化。這有助於防止某家公司的資料與其他公司的資料混合。
批次處理可協助應用程式有效地從 Web 收集資料,同時根據目標公司及其各自的 Web 網域,維持清晰的結構和資訊分隔。這種方法有助於確保所收集資料的完整性和可用性,因為它整齊地組織並與適當的公司和網域相關聯。
