Amazon Redshift 自 2025 年 11 月 1 日起不再支援建立新的 Python UDF。如果您想要使用 Python UDF,請在該日期之前建立 UDF。現有 Python UDF 將繼續正常運作。如需詳細資訊,請參閱部落格文章
使用 SVL_QUERY_REPORT 檢視
若要使用 SVL_QUERY_REPORT 依切片分析摘要資訊,請執行下列操作:
-
執行下列動作來判斷您的查詢 ID:
select query, elapsed, substring from svl_qlog order by query desc limit 5;在
substring欄位中檢查截斷的查詢文字,判斷代表您的查詢的query值。如果您已執行查詢超過一次,請使用來自具有較低query值資料列的elapsed值。那是編譯版本的資料列。如果您已執行許多查詢,您可以提升 LIMIT 子句使用的值,以確定您的查詢已包含在其中。 -
從 SVL_QUERY_REPORT 中,為您的查詢選取資料列。依區段、步驟、經過時間和資料列排列結果:
select * from svl_query_report where query = MyQueryID order by segment, step, elapsed_time, rows; -
針對每個步驟,查看所有配量是否正處理大約相同數量的資料列:
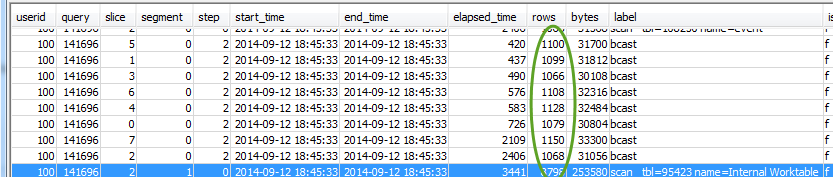
也查看所有配量是否正耗費大約相同的時間量:
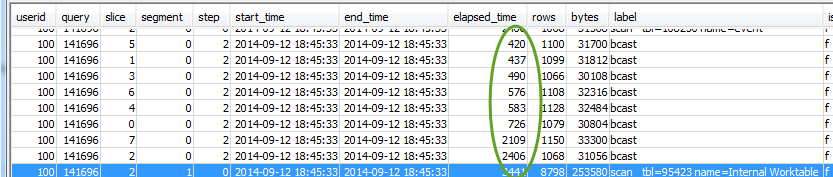
這些值的差異大可能表示由於此特定查詢的次佳配送樣式造成的資料配送偏度。如需建議的解決方案,請參閱次佳資料分佈。
