從 2025 年 11 月 1 日起,Amazon Redshift 將不再支援建立新的 Python UDFs。如果您想要使用 Python UDFs,請在該日期之前建立 UDFs。現有的 Python UDFs將繼續如常運作。如需詳細資訊,請參閱部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
檢視叢集效能資料
使用 Amazon Redshift 中的叢集指標,您可執行以下常見的效能任務:
-
判斷叢集指標在特定時間範圍內是否不正常,以及若是不正常,則辨識影響效能的查詢。
-
確認歷史或目前查詢是否對叢集效能造成影響。如果您發現有問題的查詢,您可以檢視其相關詳細資訊,包含查詢執行期間的叢集效能。您可以使用此資訊來診斷查詢緩慢的原因以及可以執行的事項來改善其效能。
檢視效能資料
-
登入 AWS Management Console ,並在 https://console.aws.amazon.com/redshiftv2/
:// 開啟 Amazon Redshift 主控台。 -
在導覽功能表上,選擇叢集,然後從清單中選擇叢集名稱以開啟其詳細資訊。隨即顯示叢集的詳細資訊,包含叢集效能、查詢監控、資料庫、資料共用、排程、維護和屬性標籤。
-
選擇 Cluster performance (叢集效能) 標籤,取得包括下列項目的效能資訊:
-
CPU 使用率
-
使用的磁碟空間百分比
-
資料庫連線
-
運作狀態
-
查詢期間
-
查詢輸送量
-
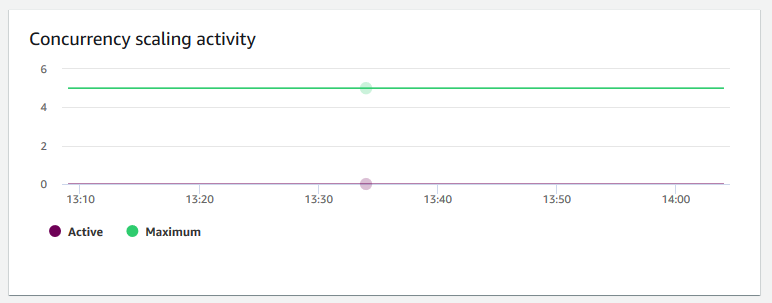
Concurrency scaling activity (並行擴展活動)
另有更多指標可用。若要查看可用的指標並選擇要顯示的指標,請選擇 Preferences (偏好設定) 圖示。
-
叢集效能圖表
下列範例顯示一些在全新 Amazon Redshift 主控台中顯示的圖表。
-
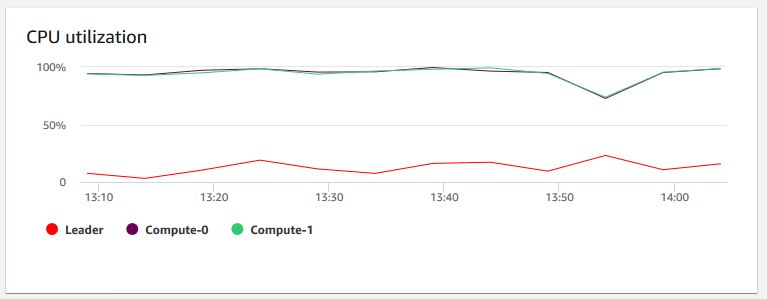
CPU 使用率 — 顯示所有節點的 CPU 使用率百分比 (領導和運算)。如要在排程叢集遷移或其他資源使用操作前尋找叢集用量最低的時間,請監控此圖表來查看個別或所有節點的 CPU 使用率。
-
維護模式 — 使用
On和Off指標,顯示叢集在指定時間是否處於維護模式。您可以查看叢集正在進行維護的時間。然後,您可以將此時間與叢集完成的操作產生關聯,以估計其未來在發生經常性事件時的停機時間。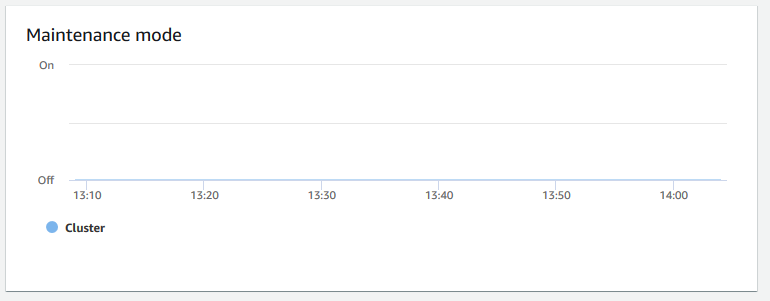
-
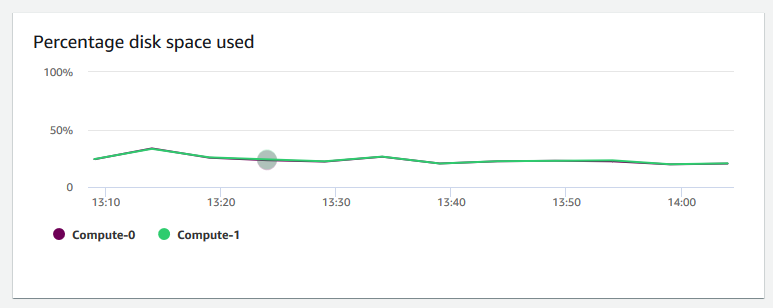
使用的磁碟空間百分比 — 顯示每個運算節點磁碟空間的用量百分比,而非叢集整體的用量。您可以探索此圖表來監控磁碟使用率。VACUUM 和 COPY 等維護操作會使用中繼暫時儲存空間來進行排序操作,因此預期會在磁碟用量中出現尖峰。
-
讀取輸送量 — 顯示每秒從磁碟讀取的平均 MB 數。您可以評估此圖表,監控叢集的對應實體方面。此輸送量不包含叢集中執行個體及其磁碟區之間的網路流量。
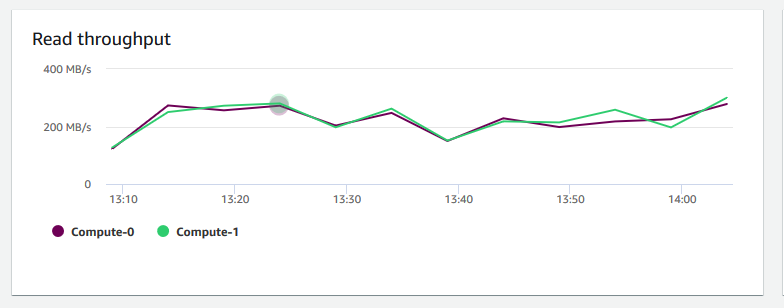
-
讀取延遲 — 顯示每毫秒磁碟讀取 I/O 操作所花費的平均時間長度。您可以檢視要傳回資料的回應時間。當延遲相當高時,這表示寄件者花費較多時間閒置 (而非傳送任何新的封包),降低輸送量成長的速度。
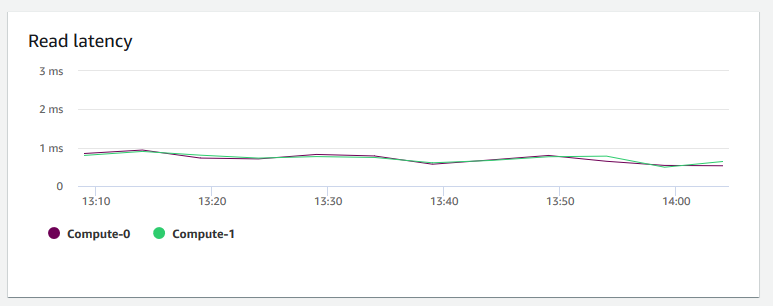
-
寫入輸送量 — 顯示每秒寫入磁碟的平均 MB 數。您可以評估此指標來監控叢集的對應實體方面。此輸送量不包含叢集中執行個體及其磁碟區之間的網路流量。
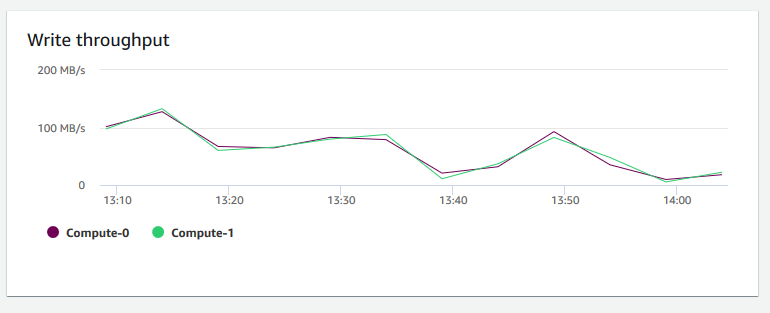
-
寫入延遲 — 顯示磁碟寫入 I/O 操作花費的平均時間長度 (毫秒)。您可以評估傳回寫入確認的時間。當延遲相當高時,這表示寄件者花費較多時間閒置 (而非傳送任何新的封包),降低輸送量成長的速度。
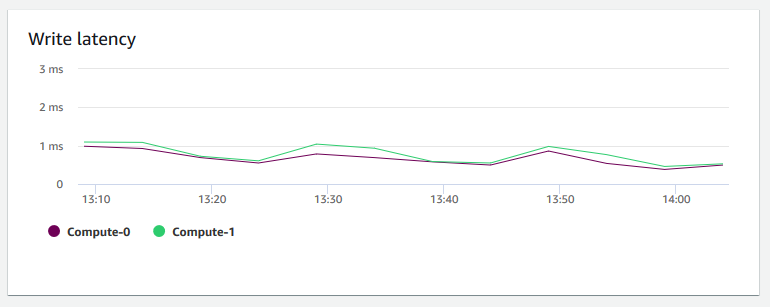
-
資料庫連線 — 顯示叢集的資料庫連線數。您可以使用此圖表來查看與資料庫建立的連線數,並尋找叢集用量最低的時間。
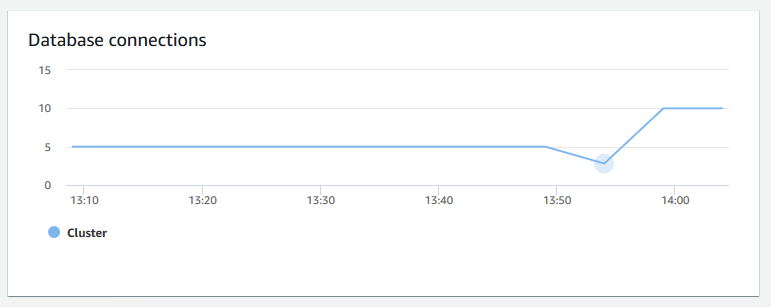
-
總資料表計數 — 顯示叢集內於特定時間點開啟的使用者資料表數。您可以監控開啟資料表計數較高時的叢集效能。
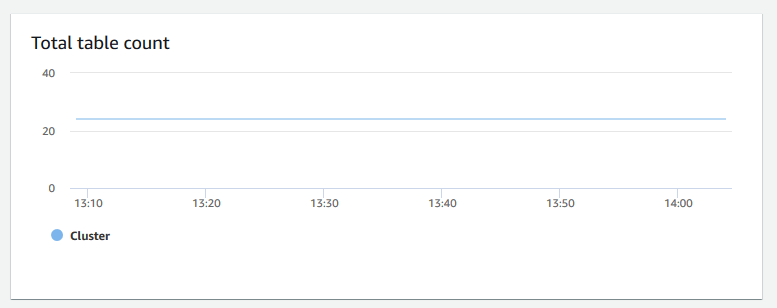
-
運作狀態 — 指出叢集的運作狀態為
Healthy或Unhealthy。如果叢集可以連線到其資料庫及成功執行簡易查詢,便會將叢集視為運作狀態良好。否則,表示該叢集運作不良。不良狀態可能會發生於資料庫處於極高負載,或叢集上的資料庫有組態的問題。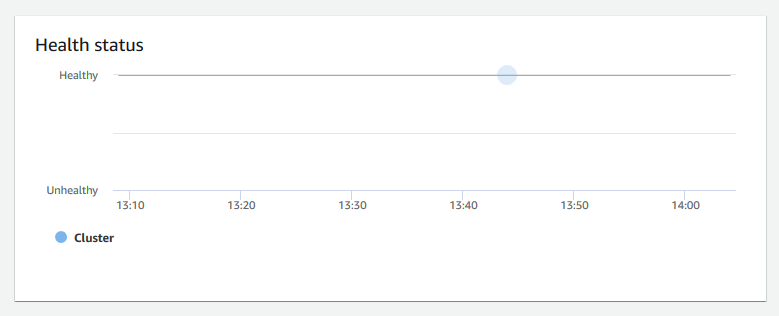
-
查詢持續時間 — 顯示完成查詢的平均時間長度 (微秒)。您可以針對此圖表上的資料進行基準測試,測量叢集內的 I/O 效能,並視需要調校最耗費時間的查詢。
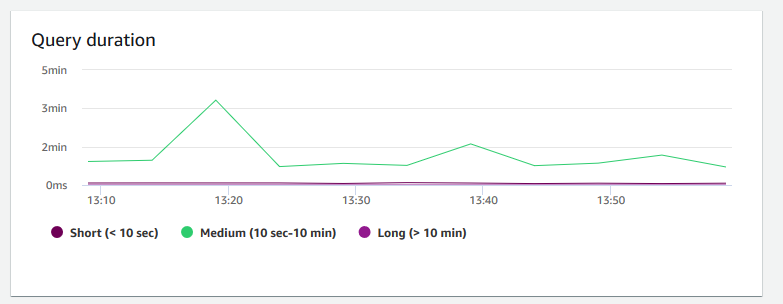
-
查詢輸送量 — 顯示每秒完成的平均查詢數。您可以分析此圖表上的資料,測量資料庫效能,並說明系統以平衡方式支援多使用者的能力。
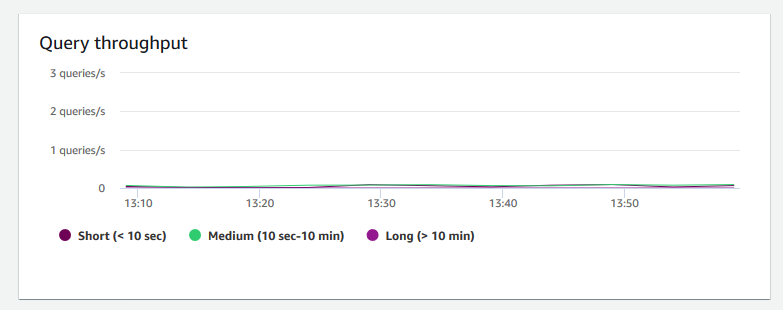
-
每個 WLM 佇列的查詢持續時間 — 顯示完成查詢的平均時間長度 (微秒)。您可以針對此圖表上的資料進行基準測試,測量每個 WLM 佇列的 I/O 效能,並視需要調校最耗費時間的查詢。
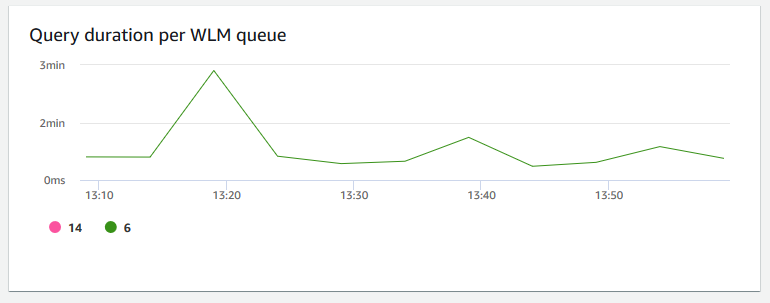
-
每個 WLM 佇列的查詢輸送量 — 顯示每秒完成的平均查詢數。您可以分析此圖表上的資料,測量每個 WLM 佇列的資料庫效能。
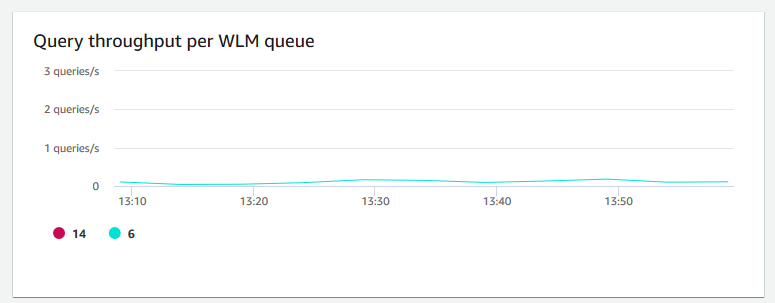
-
並行擴展活動 — 顯示作用中並行擴展叢集的數量。當並行擴展啟用時,當您需要更多叢集容量以執行增加的並行讀取查詢時,Amazon Redshift 將會自動新增額外的叢集容量。