本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
故障診斷
下列常見問答集可協助您進行 Amazon SageMaker 非同步推論端點問題疑難排解。
您可以使用下列方法,找到端點後面的執行個體計數:
您可以使用 SageMaker AI DescribeEndpoint API 來描述端點後方在任何指定時間點的執行個體數目。
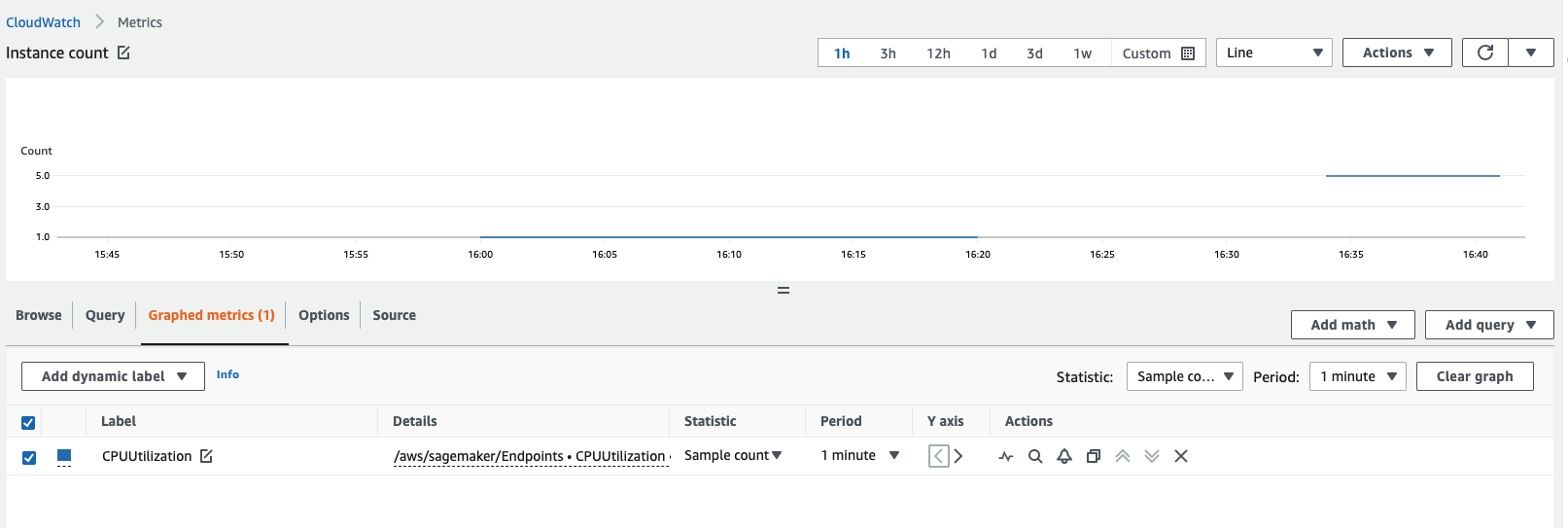
檢視 Amazon CloudWatch 指標即可找到執行個體計數。檢視端點執行個體的指標,例如
CPUUtilization或MemoryUtilization,並且查看 1 分鐘期間的樣本計數統計資料。計數應等於作用中執行個體的數量。下列螢幕擷取畫面顯示 CloudWatch 主控台繪製的CPUUtilization指標,其中統計資料設定為Sample count、期間設定為1 minute,得出的計數為 5。
下表依架構類型概述 SageMaker AI 容器的常見可調整環境變數。
TensorFlow
| 環境變數 | 描述 |
|---|---|
|
|
若為以 TensorFlow 為基礎的模型, |
|
|
此參數控管可用 GPU 記憶體的一部分,以初始化 CUDA/CUDNN 和其他 GPU 程式庫。 |
|
這樣一來便會與 |
|
這樣一來便會與 |
|
這個值控管要求 Gunicorn 為處理請求產生的工作者程序數量。此值可與其他參數搭配使用,衍生最大化推論輸送量的集合。除此之外, |
|
這個值控管要求 Gunicorn 為處理請求產生的工作者程序數量。此值可與其他參數搭配使用,衍生最大化推論輸送量的集合。除此之外, |
|
Python 內部使用 OpenMP 在程序中實作多執行緒。通常會產生相當於 CPU 核心數量的執行緒。然而,在 Intel 的 HypeThreading 這類 Simultaneous Multi Threading (SMT) 實作時,若干程序可能會產生實際 CPU 核心數兩倍數量的執行緒,超額訂閱特定核心。在某些情況下,Python 二進位最終可能產生的執行緒數,會是可用處理器核心的四倍。因此,如果您使用工作者執行緒超額訂閱可用核心,則此參數的理想設定為 |
|
|
在某些情況下,如果將 |
PyTorch
| 環境變數 | 描述 |
|---|---|
|
|
這是 TorchServe 等待接收的批次延遲時間上限。 |
|
|
如果計時器時間到之前,TorchServe 未收到 |
|
|
TorchServe 允許縮減的工作者數量下限。 |
|
|
TorchServe 允許擴展的工作者數量上限。 |
|
|
時間延遲,亦即推論未得到回應時,經過這段時間便會逾時。 |
|
|
TorchServe 的承載大小上限。 |
|
|
TorchServe 的回應大小上限。 |
多模型伺服器 (MMS)
| 環境變數 | 描述 |
|---|---|
|
|
針對推論請求承載類型龐大的情況,以及由於承載較大,因此 JVM 堆積記憶體使用量可能較高時,不妨調整這個參數。理想中,不妨降低 JVM 的堆積記憶體要求,並允許 Python 工作者為實際的模型服務分配更多記憶體。JVM 僅用於接收 HTTP 請求、將請求排入佇列,以及將請求分派給 Python 型工作者進行推論。如果增加 |
|
|
此參數用於後端模型服務,調整可能獲得不錯的效果,因為這個參數是整個模型服務的關鍵要素,也是 Python 為每個模型生成執行緒的基礎。如果此元素速度較慢 (或調整不當),則前端調整可能無效。 |
您可以讓非同步推論使用與即時推論或批次轉換相同的容器。請確認容器的逾時和承載大小限制,已設定為處理較大的承載和更長的逾時。
請參閱下列非同步推論限制:
承載大小限制:1 GB
逾時限制:請求最多可能需要 60 分鐘。
佇列訊息 TimeToLive (TTL):6 小時
可以放置在 Amazon SQS 內的訊息數量:無限制。不過,標準佇列的傳輸中訊息數量配額為 120,000,FIFO 佇列配額為 20,000。
非同步推論一般可根據調用或執行個體橫向擴展。若為調用指標,不妨查看 ApproximateBacklogSize 這個定義佇列中尚未處理之項目數量的指標。您可以利用此指標或 InvocationsPerInstance 指標,了解哪些 TPS 可能受節制。在執行個體層級,請檢查執行個體類型及其 CPU/GPU 使用率,定義何時橫向擴展。如果單一執行個體的容量超過 60-70% 通常是好事,代表硬體正在飽和。
不建議使用多個擴展政策,因為這些政策可能會發生衝突,導致硬體層級混淆,在橫向擴展時導致延遲。
請檢查您的容器是否能夠同時處理 ping 並調用請求。SageMaker AI 調用請求大約需要 3 分鐘,在此期間,由於逾時導致 SageMaker AI 將容器偵測為 ,因此通常多個 ping 請求最終會失敗Unhealthy。
是。MaxConcurrentInvocationsPerInstance 是非同步端點的功能。這個功能不需要自訂容器實作。MaxConcurrentInvocationsPerInstance 控制調用請求傳送至客戶容器的速率。如果此值設為 1,則無論客戶容器有多少工作者,一次都只會將 1 個請求傳送至容器。
這個錯誤意味著客戶容器傳回錯誤。SageMaker AI 無法控制客戶容器的行為。SageMaker AI 只會傳回來自 的回應ModelContainer,不會重試。如果需要,您可以將調用設定為失敗時重試。建議您開啟容器記錄,並檢查容器日誌,找出模型 500 錯誤的根本原因。此外,也請在失敗點檢查相應的 CPUUtilization 和 MemoryUtilization 指標。您也可以將 S3FailurePath 設定為 Amazon SNS 中的模型回應,做為非同步錯誤通知的一部分,調查失敗的原因。
您可以查看指標 InvocationsProcesssed;該指標應與您希望根據單一並行在一分鐘內處理的調用次數一致。
最佳實務是啟用 Amazon SNS 這個訊息導向的應用程式通知服務,讓多個訂閱者利用各種傳輸通訊協定 (包括 HTTP、Amazon SQS 和電子郵件) 請求和接收時間關鍵訊息的 “推送” 通知。使用 CreateEndpointConfig 並指定 Amazon SNS 主題建立端點時,非同步推論會發布通知。
要使用 Amazon SNS 檢查異步終端節點的預測結果,首先需要建立一個主題、訂閱主題、確認您對主題的訂閱,並記下該主題的 Amazon Resource Name (ARN)。有關如何建立、訂閱和尋找 Amazon SNS 主題 Amazon ARN 的詳細資訊,請參閱 Amazon SNS 開發人員指南的配置 Amazon SNS。如需如何搭配非同步推論使用 Amazon SNS 的更多資訊,請參閱查看預測結果。
是。非同步推論提供一種機制,可在沒有請求時將執行個體縮減為零。如果您的端點在這些期間縮減為零執行個體,則在佇列中的請求數量超過擴展政策指定的目標之前,端點將不會再次橫向擴展。這樣一來,佇列中請求的等待時間可能很長。在這種情況下,如果您想針對小於指定佇列目標的新請求,從零執行個體縱向擴展,可以使用稱為 HasBacklogWithoutCapacity 的其他擴展政策。如需如何定義此擴展政策的更多資訊,請參閱自動擴展非同步端點。
如需各區域非同步推論支援的執行個體詳盡清單,請參閱 SageMaker 定價
