本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
建立預測結果與輸入記錄的關聯性
建立大型資料集的預測時,您可以排除預測不需要的屬性。完成預測後,您可以建立一些已排除屬性與這些預測,或與報告中其他輸入資料的關聯性。使用批次轉換來執行這些資料處理步驟,您通常不需要額外的預先處理或後續處理。您只能使用 JSON 和 CSV 格式的輸入檔案。
建立推論與輸入記錄關聯的工作流程
下圖顯示建立推論與輸入記錄關聯性的工作流程。
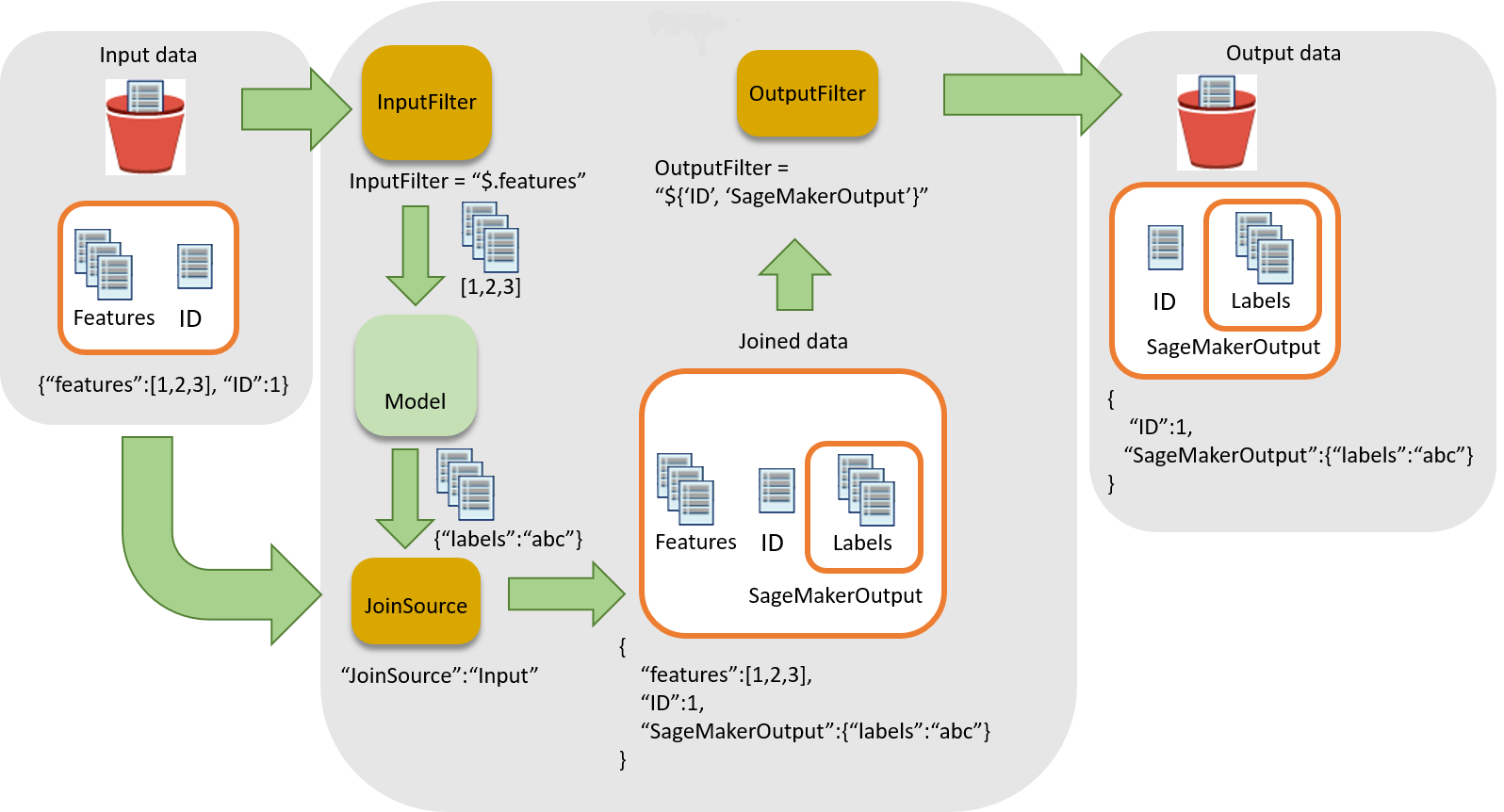
若要建立推論與輸入資料的關聯性,有三個主要步驟:
-
先篩選掉推論不需要的輸入資料,再將輸入資料傳送至批次轉換任務。使用
InputFilter參數判斷做為模型輸入使用的屬性。 -
建立輸入資料與推論結果的關聯性。使用
JoinSource參數,結合輸入資料與推論。 -
篩選掉已加入的資料,保留所需輸入,在報告中提供解譯預測的內容。使用
OutputFilter將已聯結資料集的指定部分儲存在輸出檔案。
在批次轉換任務中使用資料處理
使用 CreateTransformJob 建立批次轉換工作處理資料時:
-
在
DataProcessing資料結構中使用InputFilter參數,指定要傳遞到模型的輸入部分。 -
使用轉換的資料和
JoinSource參數加入原始輸入資料。 -
使用
OutputFilter參數指定在輸出檔中要包含加入輸入和批次換任務轉換資料的哪些部分。 -
選擇輸入使用 JSON 或 CSV 格式的檔案:
-
針對 JSON 或 JSON 行格式的輸入檔案,SageMaker AI 會將
SageMakerOutput屬性新增至輸入檔案,或使用SageMakerInput和SageMakerOutput屬性建立新的 JSON 輸出檔案。如需詳細資訊,請參閱DataProcessing。 -
針對 CSV 格式的輸入檔,加入的輸入資料後面會跟著轉換資料,而輸出為 CSV 檔案。
-
如果您使用演算法和 DataProcessing 結構,它必須同時支援您選擇的輸入檔和輸出檔格式。例如,CreateTransformJob API 的 TransformOutput 欄位,ContentType 和 Accept 參數皆必須設為下列其中一個值:text/csv、application/json 或 application/jsonlines。在 CSV 檔案中指定資料欄的語法和在 JSON 檔案中指定屬性的語法不相同。使用錯誤的語法會造成錯誤。如需詳細資訊,請參閱批次轉換範例。如需內建演算法之輸入和輸出檔格式的詳細資訊,請參閱Amazon SageMaker 中的內建演算法和預先訓練模型。
輸入和輸出的記錄分隔符號也必須與您選擇的檔案輸入一致。SplitType 參數指出如何分割輸入資料集中的記錄。AssembleWith 參數指出如何重新組合輸出記錄。如果您將輸入和輸出格式設為 text/csv,您還必須將 SplitType 和 AssembleWith 參數設為 line。如果將輸入和輸出格式設為 application/jsonlines,您就可以同時將 SplitType 和 AssembleWith 設為 line。
CSV 檔案無法使用內嵌新行字元。若為 JSON 檔案,屬性名稱 SageMakerOutput 預留給輸出。JSON 輸入檔不能有此名稱的屬性。如有,則可能覆寫輸入檔中的資料。
支援的 JSONPath 運算子
若要篩選及加入輸入資料和推論,請使用 JSONPath 子表達式。SageMaker AI 僅支援已定義 JSONPath 運算子的子集。下表列出支援的 JSONPath 運算子。對於 CSV 資料,系統會以 JSON 陣列的形式來擷取每個資料列,因此只能套用索引型的 JSONPaths,例如 $[0]、$[1:]。CSV 資料也應該遵循 RFC 格式
| JSONPath 運算子 | 說明 | 範例 |
|---|---|---|
$ |
查詢的根元素。所有路徑表達式的開頭都必須有此運算子。 |
$ |
. |
以點標記的子元素。 |
|
* |
萬用字元。用以代替屬性名稱或數值。 |
|
[' |
以括號標記的元素或多個子元素。 |
|
[ |
索引或索引陣列。也支援負索引值。 |
|
[ |
陣列分割運算子。array slice() 方法會擷取陣列的一部分,並傳回新的陣列。如果省略 |
|
當使用括號表示法來指定特定欄位的多個子元素時,不支援括號內子項的額外巢狀。例如,支援 $.field1.['child1','child2'],但不支援 $.field1.['child1','child2.grandchild']。
如需 JSONPath 運算子的詳細資訊,請參閱 GitHub 上的 JsonPath
批次轉換範例
以下範例會示範一些結合輸入資料和預測結果的常見方式。
範例:僅輸出推論
根據預設,DataProcessing 參數不會將推論結果與輸入聯結。它只會輸出推論結果。
如果您想明確指定不將結果與輸入聯結,請使用 Amazon SageMaker Python SDK
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
若要使用適用於 Python 的 AWS SDK 輸出推論,請將下列程式碼新增至 CreateTransformJob 請求。以下程式碼模擬預設的行為。
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
範例:輸出推論聯結輸入資料
如果您使用 Amazon SageMaker Python SDKassemble_with 和 accept 參數。使用轉換呼叫時,join_source 參數請指定為 Input,並指定 split_type 和 content_type 參數。split_type 參數的值必須與 assemble_with 相同,且 content_type 參數的值必須與 accept 相同。如需參數及其接受值的更多資訊,請參閱 Amazon SageMaker AI Python SDK 中的轉換器
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
如果您使用的是適用於 Python 的 AWS SDK (Boto 3),請將下列程式碼新增至您的CreateTransformJob請求,以使用推論加入所有輸入資料。Accept 和 ContentType 的值必須相符,且 AssembleWith 和 SplitType 的值也必須相符。
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
針對 JSON 或 JSON 行輸入檔,結果位在輸入 JSON 檔案的 SageMakerOutput 金鑰中。例如,如果輸入是包含鍵/值對 {"key":1} 的 JSON 檔案,則資料轉換結果可能會是 {"label":1}。
SageMaker AI 會將兩者儲存於 SageMakerInput 金鑰的輸入檔案中。
{ "key":1, "SageMakerOutput":{"label":1} }
注意
JSON 的已加入結果必須是鍵/值對物件。如果輸入不是金鑰值對物件,SageMaker AI 就會建立新的 JSON 檔案。在新的 JSON 檔案中,輸入資料會存放在 SageMakerInput 索引鍵中,而結果則存放為 SageMakerOutput 值。
針對 CSV 檔案,例如,如果記錄是 [1,2,3],且標籤結果是 [1],則輸出檔會包含 [1,2,3,1]。
範例:輸出推論與輸入資料聯結,並從輸入排除 ID 欄 (CSV)
如果您使用 Amazon SageMaker Python SDKinput_filter 的 JsonPath 子運算式。例如,如果輸入資料包含五個欄,而第一欄是 ID 欄,請使用下列轉換器請求,選取 ID 欄以外的所有資料欄作為功能。轉換器仍會輸出與推論聯結的所有輸入欄。如需參數及其接受值的更多資訊,請參閱 Amazon SageMaker AI Python SDK 中的轉換器
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
如果您使用的是適用於 Python 的 AWS SDK (Boto 3),請將下列程式碼新增至您的 CreateTransformJob請求。
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
若要在 SageMaker AI 中指定欄,請使用陣列元素的索引。第一欄是索引 0,第二欄是索引 1,第六欄是索引 5。
若要排除輸入的首欄,請將 InputFilter 設為 "$[1:]"。冒號 (:) 指示 SageMaker AI 包括兩個值 (含) 之間的所有元素。例如,$[1:4] 指定第二欄到第五欄。
如果您省略冒號後面的數字,例如 [5:],則子集會包含從第六欄到最後一欄的所有欄。如果您省略冒號前面的數字,例如 [:5],則子集會包含從第一欄 (索引 0) 到第六欄的所有欄。
範例:輸出聯結 ID 欄的推論,並排除輸入的 ID 欄 (CSV)
如果您使用的是 Amazon SageMaker Python SDKoutput_filter。output_filter 使用 JSONPath 子運算式指定,輸入資料與推論結果聯結之後,要傳回哪些資料欄做為輸出。以下請求顯示,如何在排除 ID 欄的同時進行預測,然後將 ID 欄與推論聯結。請注意,在以下範例,輸出的尾欄 (-1) 包含推論。如果您使用的是 JSON 檔案,SageMaker AI 會將推論結果儲存於屬性 SageMakerOutput。如需參數及其接受值的更多資訊,請參閱 Amazon SageMaker AI Python SDK 中的轉換器
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
如果您使用的是適用於 Python 的 AWS SDK (Boto 3),請將下列程式碼新增至您的CreateTransformJob請求,只加入 ID 資料欄與推論。
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
警告
如果您使用的是 JSON 格式的輸入檔,檔案不能包含屬性名稱 SageMakerOutput。此屬性名稱預留給輸出檔案中的推論。如果 JSON 格式的輸入檔包含具有此名稱的屬性,則可能會使用推論覆寫輸入檔中的值。
