本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
分析結果
SageMaker Clarify 處理任務完成後,您可以下載輸出檔案來檢查它們,也可以在 SageMaker Studio Classic 中視覺化結果。下列主題說明 SageMaker Clarify 產生的分析結果,例如偏差分析、SHAP 分析、電腦視覺可解釋性分析和部分相依性圖 (PDPs) 分析所產生的結構描述和報告。如果組態分析包含用於運算多個分析的參數,則結果會彙總為一個分析和一個報告檔案。
SageMaker Clarify 處理任務輸出目錄包含下列檔案:
-
analysis.json— 包含 JSON 格式的偏差指標和功能重要性的檔案。 -
report.ipynb— 包含程式碼的靜態筆記本,可協助您視覺化偏差指標和功能重要性。 -
explanations_shap/out.csv— 建立並包含根據您的特定分析組態自動產生檔案的目錄。例如,如果您啟用save_local_shap_values參數,則每個執行個體的本地 SHAAP 值會儲存到explanations_shap目錄。另一個範例是,如果您的analysis configuration不包含 SHAP 基準參數的值,SageMaker Clarify 可解釋性工作會透過叢集輸入資料集來運算基準。然後,它會將產生的基準儲存到目錄中。
如需詳細資訊,請參閱下列各節。
偏差分析
Amazon SageMaker Clarify 使用記錄在 Amazon SageMaker Clarify 偏差和公平性條款 中的術語來討論偏差和公平性。
分析檔案的結構描述
分析檔案採用 JSON 格式,分為兩個區段:訓練前偏差指標和訓練後偏差指標。訓練前和訓練後偏差指標的參數如下。
-
pre_training_bias_metrics – 訓練前偏差指標的參數。如需更多資訊,請參閱訓練前偏差指標及分析組態檔案。
-
label – 由分析組態的
label參數定義的 Ground Truth 標籤名稱。 -
label_value_or_threshold – 包含由分析組態參數定義的標籤值或間隔的字串。
label_values_or_threshold例如,如果值1是為二進位分類問題提供的,那麼字串將為1。如果為多類問題提供了多值[1,2],那麼該字串將是1,2。如果提供了一個閾值40用於回歸問題,那麼該字串將是像(40, 68]的內部,其中68是在輸入資料集中標籤的最大值。 -
構面 – 區段包含數個鍵值對,其中鍵對應到構面組態參數
name_or_index所定義的構面名稱,而該值為構面物件的陣列。每個構面物件具有下列項目:-
value_or_threshold – 包含構面組態
value_or_threshold參數所定義的構面值或間隔字串。 -
metrics – 區段包含一系列偏差指標元素,每個偏差指標元素都具有以下屬性:
-
name – 偏差測量結果的簡短名稱。例如
CI。 -
description – 偏差指標的完整名稱。例如
Class Imbalance (CI)。 -
value – 偏差指標值,或 JSON Null 值 (如果未因特定原因運算偏差指標)。值 ±∞ 表示為字串
∞和-∞分別。 -
error – 選擇性錯誤訊息,說明未運算偏差指標的原因。
-
-
-
-
post_training_bias_metrics – 此區段包含訓練後偏差指標量,並遵循與訓練前部分類似的配置和結構。如需更多資訊,請參閱訓練後資料和模型偏差指標。
以下是分析組態的範例,可運算訓練前和訓練後偏差指標。
{ "version": "1.0", "pre_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "CDDL", "description": "Conditional Demographic Disparity in Labels (CDDL)", "value": -0.06 }, { "name": "CI", "description": "Class Imbalance (CI)", "value": 0.6 }, ... ] }] } }, "post_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "AD", "description": "Accuracy Difference (AD)", "value": -0.13 }, { "name": "CDDPL", "description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)", "value": 0.04 }, ... ] }] } } }
偏差分析報告
偏差分析報告包含數個包含詳細說明和描述的表格和圖表。其中包含但不限於標籤值的分布、構面值的分布、高階模型效能圖表、偏差指標表及其描述。如需有關偏差指標以及如何解譯它們的更多資訊,請參閱了解 Amazon SageMaker Clarify 如何協助偵測偏差
SHAP 分析
SageMaker Clarify 處理任務使用核心 SHAP 演算法來運算功能屬性。SageMaker Clarify 處理任務會產生本地和整體 SHAP 值。這有助於確定每個功能對模型預測的貢獻。本地 SHAP 值代表每個個別執行個體的功能重要性,而整體 SHAP 值會彙總資料集在所有執行個體中的本地 SHAP 值。如需 SHAP 值和如何解譯它們的更多資訊,請參閱使用塑形值的特徵屬性。
SHAP 分析檔案的結構描述
整體 SHAP 分析結果儲存在kernel_shap方法下的分析檔案說明區段中。SHAP 分析檔案的不同參數如下:
-
explanations – 包含功能重要性分析結果的分析檔案區段。
-
kernal_shap – 分析檔案中包含整體 SHAP 分析結果的區段。
-
global_shap_values – 分析檔案的一個區段,其中包含數個鍵值對。鍵值組中的每個鍵都代表輸入資料集中的功能名稱。鍵值組中的每個值都對應到功能的整體 SHAP 值。整體 SHAP 值是透過使用
agg_method組態彙總功能的每個執行個體 SHAP 值來取得。如果啟動use_logit組態,則會使用邏輯迴歸係數來運算該值,該係數可解譯為對數-賠率比率。 -
expected_value – 基準資料集的平均預測。如果啟動
use_logit組態,則使用邏輯迴歸係數運算該值。 -
global_top_shap_text – 用於 NLP 可解釋性分析。分析檔案的一個區段,其中包含一組鍵值對。SageMaker Clarify 處理任務會彙總每個權杖的 SHAP 值,然後根據其整體 SHAP 值選取常用權杖。
max_top_tokens組態定義了要選取的權杖的數量。每個選定的常用權杖都有一個鍵值組。鍵值組中的鍵對應到常用權杖的文字功能名稱。鍵值對中的每個值都是常用權杖的整體 SHAP 值。如需
global_top_shap_text鍵值對的範例,請參閱下列輸出。
-
-
下列範例顯示表格式資料集的 SHAP 分析輸出。
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Age": 0.022486410860333206, "Gender": 0.007381025261958729, "Income": 0.006843906804137847, "Occupation": 0.006843906804137847, ... }, "expected_value": 0.508233428001 } } } }
下列範例顯示文字資料集的 SHAP 分析輸出。與欄Comments對應的輸出是在文字功能分析之後產生的輸出範例。
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Rating": 0.022486410860333206, "Comments": 0.058612104851485144, ... }, "expected_value": 0.46700941970297033, "global_top_shap_text": { "charming": 0.04127962903247833, "brilliant": 0.02450240786522321, "enjoyable": 0.024093569652715457, ... } } } } }
產生的基準檔案的結構描述
未提供 SHAP 基準組態時,SageMaker Clarify 處理任務會產生基準資料集。SageMaker Clarify 使用以距離為基礎的叢集演算法,從輸入資料集建立的叢集產生基準資料集。產生的基準資料集會儲存在 CSV 檔案中,位於explanations_shap/baseline.csv。此輸出檔案包含標題列和數個以分析組態中指定的num_clusters參數為基礎的執行個體。基準資料集僅由功能欄組成。下列範例顯示透過叢集輸入資料集建立的基準。
Age,Gender,Income,Occupation 35,0,2883,1 40,1,6178,2 42,0,4621,0
表格式資料集解譯性分析中的本地 SHAP 值結構描述
對於表格式資料集,如果使用單一運算執行個體,SageMaker Clarify 處理任務會將本地 SHAP 值儲存到名為explanations_shap/out.csv的 CSV 檔案。如果您使用多個運算執行個體,本地 SHAP 值會儲存到explanations_shap目錄中的數個 CSV 檔案。
包含本地 SHAP 值的輸出檔案具有一列,其中包含由標題定義的每欄本地 SHAP 值。標題遵循功能名稱後面加底線後跟目標變數的名稱的Feature_Label命名慣例。
對於多類別問題,標題中的功能名稱會先變更,然後是標籤。例如,兩個功能F1, F2和兩個類L1和L2,在標題中為F1_L1、F2_L1、F1_L2、和F2_L2。如果分析組態包含joinsource_name_or_index參數的值,則連接中使用的鍵欄會附加到標題名稱的末尾。這允許將本地 SHAP 值映射到輸入資料集的執行個體。以下是包含 SHAP 值的輸出檔案範例。
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
來自 NLP 解譯性分析的本地 SHAP 值的結構描述
對於 NLP 解譯性分析,如果使用單一運算執行個體,SageMaker Clarify 處理任務會將本地 SHAP 值儲存到名為 JSON 行的檔案中。explanations_shap/out.jsonl如果您使用多個運算執行個體,本地 SHAP 值會儲存到explanations_shap目錄中的數個 JSON 行檔案。
包含本地 SHAP 值的每個檔案都有多個資料行,每行都是一個有效的 JSON 物件。JSON 物件具有下列屬性:
-
explanations – 分析文件的部分,其中包含單一執行個體的核心 SHAP 說明陣列。陣列中的每個元素都具有下列項目:
-
feature_name – 由標題組態提供的功能標題名稱。
-
data_type – 由 SageMaker Clarify 處理任務推斷的功能類型。文字特徵的有效值包含
numerical、categorical、和free_text(對於文字特徵)。 -
attributions – 功能特定的歸因物件陣列。文字功能可以有多個歸因多重屬性物件,每個屬性物件用於
granularity組態所定義的單位。屬性物件具有下列項目:-
attribution – 類別特定的機率值陣列。
-
description – (針對文字特徵) 文字單位的描述。
-
partial_text – SageMaker Clarify 處理任務說明的文字部分。
-
start_idx – 從零開始的索引,用來識別指出部分文字片段開始的陣列位置。
-
-
-
以下是本地 SHAP 值文件中的單行的範例,範例有美化以增強其可讀性。
{ "explanations": [ { "feature_name": "Rating", "data_type": "categorical", "attributions": [ { "attribution": [0.00342270632248735] } ] }, { "feature_name": "Comments", "data_type": "free_text", "attributions": [ { "attribution": [0.005260534499999983], "description": { "partial_text": "It's", "start_idx": 0 } }, { "attribution": [0.00424190349999996], "description": { "partial_text": "a", "start_idx": 5 } }, { "attribution": [0.010247314500000014], "description": { "partial_text": "good", "start_idx": 6 } }, { "attribution": [0.006148907500000005], "description": { "partial_text": "product", "start_idx": 10 } } ] } ] }
SHAP 分析報告
SHAP 分析報告提供10常用整體 SHAP 最大值的長條圖。下列圖表範例說明常用4功能的 SHAP 值。

電腦視覺 (CV) 可解譯性分析
SageMaker Clarify 電腦視覺可解譯功能會取得由影像組成的資料集,並將每個影像視為超像素的集合。分析之後,SageMaker Clarify 處理任務會輸出影像資料集,其中每個影像都會說明超像素的熱度圖。
以下範例說明了左側的輸入速度限制符號,以及右側的 SHAP 散量的大小的熱度圖。這些 SHAP 值是由影像辨識工具 Resnet-18 模型運算,該模型經過訓練,可識別德國交通標誌

如需更多資訊,請參閱範例筆記本使用 SageMaker Clarify 解譯影像分類
部分相依性繪圖 (PDP) 分析
部分相依性繪圖說明預測目標回應對一組感興趣的輸入功能之相依性。與所有其他輸入功能的值相比,這些值會被邊界化,稱為補碼功能。直覺上,您可以將部分依賴性解譯為目標回應,該回應作為感興趣的每個輸入功能的函式。
分析檔案的結構描述
PDP 值儲存在pdp方法下的explanations分析檔案區段中。explanations參數的設定方式如下:
-
explanations – 包含功能重要性分析結果的分析檔案區段。
-
pdp – 分析檔案的區段,其中包含單一執行個體的 PDP 說明陣列。陣列的每個元素都有下列項目:
-
feature_name –
headers組態所提供之功能標題名稱。 -
data_type – 由 SageMaker Clarify 處理任務推斷的功能類型。
data_type的有效值包含數值和分類。 -
feature_values – 包含功能中存在的值。如果 SageMaker Clarify 所推斷的
data_type是分類,則feature_values會包含該功能可能的所有唯一值。如果 SageMaker Clarify 所推論的data_type是數字,則feature_values會包含所產生儲存貯體的中心值清單。grid_resolution參數決定用於群組功能資料欄值的儲存貯體數。 -
data_distribution – 百分比陣列,其中每個值都是儲存貯體所包含執行個體的百分比。
grid_resolution參數決定儲存貯體數。功能欄值會分組到這些儲存貯體中。 -
model_predictions – 模型預測的陣列,其中陣列的每個元素是對應到模型輸出中一個類別的預測陣列。
label_headers – 由
label_headers組態提供的標籤標題。 -
error – 如果未因特定原因運算 PDP 值,則會產生錯誤訊息。此錯誤訊息會取代包含於
feature_values、data_distributions和model_predictions欄位中的內容。
-
-
以下是從包含 PDP 分析結果的分析檔案輸出的範例。
{ "version": "1.0", "explanations": { "pdp": [ { "feature_name": "Income", "data_type": "numerical", "feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1], "data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01], "model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]], "label_headers": ["Target"] }, ... ] } }
PDP 分析報告
您可以為每個功能產生包含 PDP 圖表的分析報告。PDP 圖表feature_values沿著 X 軸繪製,並且其沿著 y 軸繪製model_predictions。對於多類模型,model_predictions是一個陣列,並且該陣列的每個元素對應到模型預測類中之一。
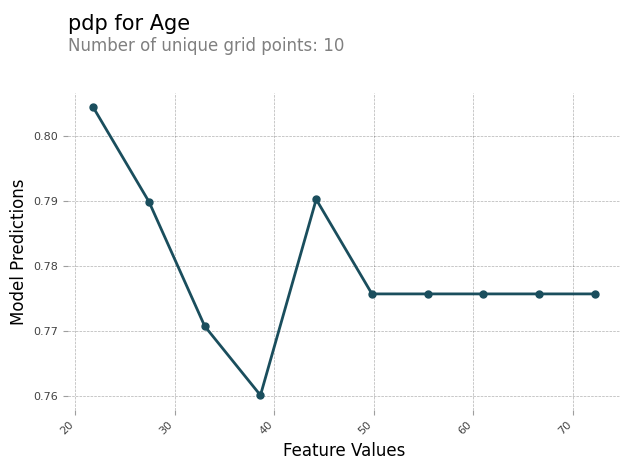
以下是該功能Age的 PDP 圖表範例。在範例輸出中,PDP 會說明群組到儲存貯體中的功能值數量。儲存貯體數由grid_resolution確定。功能值的儲存貯體會根據模型預測繪製。在此範例中,較高的功能值具有相同的模型預測值。
非對稱 Shapley 值
SageMaker Clarify 處理任務使用非對稱 Shapley 值演算法來計算時間序列預測模型解釋屬性。此演算法會決定每個時間點的輸入功能對預測的貢獻。
非對稱 Shapley 值分析檔案的結構描述
非對稱 Shapley 值結果會儲存在 Amazon S3 儲存貯體中。您可以在分析檔案的區段說明中找到此儲存貯體的位置。本節包含功能重要性分析結果。下列參數包含在非對稱 Shapley 值分析檔案中。
asymmetric_shapley_value — 分析檔案的區段,其中包含說明任務結果的中繼資料,包括下列項目:
explanation_results_path — 具有解釋結果的 Amazon S3 位置
direction — 使用者為 的組態值提供的組態
direction精細程度 — 使用者為 的組態值提供的組態
granularity
下列程式碼片段顯示範例分析檔案中先前提到的參數:
{ "version": "1.0", "explanations": { "asymmetric_shapley_value": { "explanation_results_path": EXPLANATION_RESULTS_S3_URI, "direction": "chronological", "granularity": "timewise", } } }
以下各節說明解釋結果結構如何取決於組態granularity中的 值。
時間精細程度
當精細程度為 時timewise,輸出會以下列結構表示。此scores值代表每個時間戳記的屬性。此offset值代表模型對基準資料的預測,並描述模型未接收資料時的行為。
下列程式碼片段顯示模型的範例輸出,可預測兩個時間步驟。因此,所有屬性都是兩個元素的清單,其中第一個項目是指第一個預測的時間步驟。
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]}, ] } { "item_id": "item2", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]}, ] }
精細精細程度
以下範例示範精細程度為 時的歸因結果fine_grained。offset 值具有與上一節中所述相同的意義。如果可用,則會針對目標時間序列和相關時間序列的每個時間戳記,以及每個靜態共變數,針對每個輸入功能計算屬性。
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]}, {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "static_covariate_1", "scores": [0.6, 0.1]}, {"feature_name": "static_covariate_2", "scores": [0.1, 0.3]}, ] }
對於 timewise和 fine-grained使用案例,結果會以 JSON Lines (.jsonl) 格式儲存。
