本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
分析與視覺化
Amazon SageMaker Data Wrangler 包含內建分析,只要按幾下滑鼠,即可協助您產生視覺化和資料分析。您還可以使用自己的程式碼建立自訂分析。
在資料流程中選取一個步驟,然後選擇新增分析,藉此將一項分析新增至資料框。若要存取您已建立的分析,請選取包含分析的步驟,然後選取分析。
所有分析資料都是使用您資料集的 100,000 列產生的。
您可以將下列分析新增至資料框:
-
資料視覺化,包括長條圖和散佈圖。
-
資料集的快速摘要,包括項目數量、最小值和最大值 (針對數值資料),以及最常用和最不常用的類別 (針對分類資料)。
-
資料集的快速模型,可用來產生每個功能的重要性分數。
-
目標洩漏報告,可用於確定一個或多個功能是否與目標功能有密切關聯。
-
使用您自己的程式碼自訂視覺化。
請參閱以下各節,進一步了解這些選項。
直方圖
使用長條圖來查看特定功能的功能值計數。您可以使用顏色顯示依據選項,檢查功能之間的關係。例如,以下長條圖將 2009-2019 年 Amazon 上最暢銷書籍的使用者評分,按類型著色製成分佈圖表。

您可以使用構面顯示依據功能,為另一欄中的每個值,建立一欄的長條圖。例如,下圖顯示 Amazon 上暢銷書籍的使用者評論之長條圖 (按年份劃分)。

散佈圖
使用散佈圖功能檢查功能之間的關係。若要建立散佈圖,請選取要在 X 軸和 Y 軸上繪製的功能。這兩個資料欄都必須是數字類型的資料欄。
您可以按附加資料欄為散佈圖著色。例如,以下範例顯示了一個散佈圖,比較 2009 年至 2019 年之間 Amazon 上最暢銷書籍的使用者評分與評論數量。散佈圖按書籍類別著色。
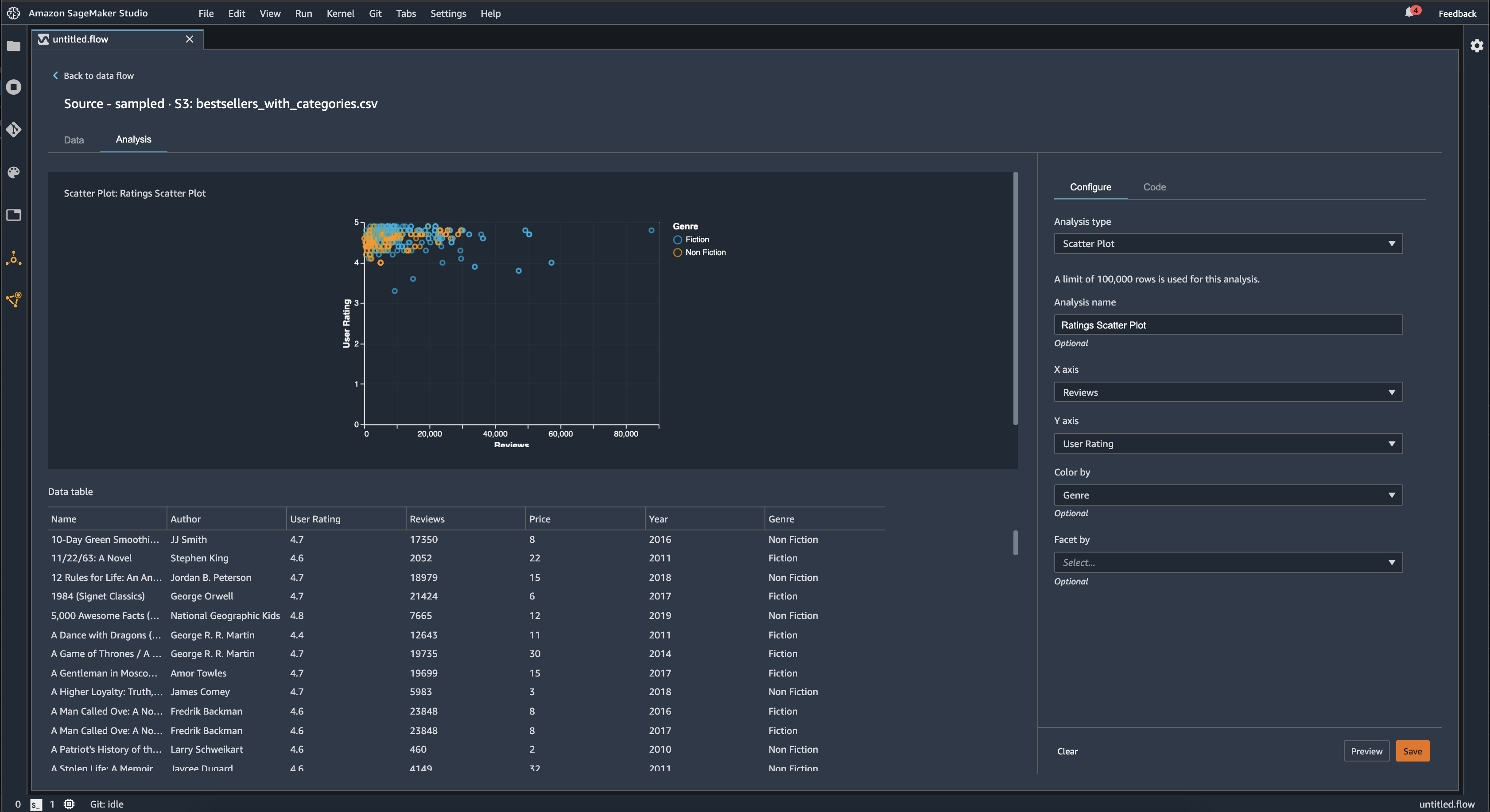
此外,您可以按功能構面劃分散佈圖。例如,以下影像顯示相同評論與使用者評分的散佈圖範例,並依年份劃分。

資料表摘要
使用資料表摘要分析來快速總結資料。
對於包含數值資料的資料欄,包括對數和浮點資料,表格摘要裡會告訴您每欄的條目數 (count)、最小值 (min)、最大值 (max)、平均值 (mean)和標準差 (stddev)。
對於包含非數值資料的資料欄,像是字串、布林值或日期/時間資料的,表格摘要會告訴您每欄的項目數 (計數)、最少出現的值 (最小值) 和最常出現的值 (最大值)。
快速模型
使用快速模型視覺化可快速評估您的資料,並為每項功能產生重要性分數。功能重要性評分
建立快速模型圖表時,您可以選取要評估的資料集,以及要比較功能重要性的目標標籤。Data Wrangler 會進行以下項目:
-
推論所選資料集中,目標標籤和每項功能的資料類型。
-
決定問題類型。基於標籤欄中的數字相異值,Data Wrangler 判斷這是迴歸還是分類問題類型。Data Wrangler 設置一個分類閾值為 100。如果標籤欄中有超過 100 個相異值,則 Data Wrangler 會將其歸類為迴歸問題;沒有的話,會歸類為分類問題。
-
預先處理功能和訓練用標籤資料。使用的演算法需要將功能編碼成向量類型,並將標籤編碼成雙精度浮點數類型。
-
使用 70% 資料訓練一組隨機森林演算法。Spark 的RandomForestRegressor
用於訓練迴歸問題的模型。RandomForestClassifier 用於訓練分類問題的模型。 -
使用剩餘 30% 的資料評估隨機森林模型。Data Wrangler 使用 F1 分數評估分類模型,並使用 MSE 分數評估迴歸模型。
-
使用 Gini 重要性方法計算每個功能的功能重要性。
下列影像展示快速模型功能的使用者介面。

目標洩漏
當機器學習訓練資料集中存在與目標標籤密切關聯的資料,但在實際資料中無法使用時,就會發生目標洩漏。例如,您的資料集中可能有一個資料欄,作為您要使用模型預測資料欄的代理。
使用目標洩漏分析時,請指定下列項目:
-
目標:這是您希望機器學習 (ML) 模型能夠進行預測的功能。
-
問題類型:這是您正在使用的機器學習 (ML) 問題類型。問題類型可以是分類或迴歸。
-
(選用) 最大功能數:這是視覺化中顯示的功能數量上限,顯示依據其目標洩漏風險進行排序。
在分類問題中,目標洩漏分析使用接收者操作特性下的區域,或每欄使用 AUC-ROC 曲線,最多到功能最大值。迴歸問題中,它使用判定係數或 R2 指標。
AUC-ROC 曲線提供了一個預測指標,在最多約 1000 個資料列的樣本中,針對每個資料欄使用交叉驗證個別運算。分數為 1 代表完美的預測能力,這通常表示目標洩漏。分數為 0.5 或更低,表示資料欄上的資訊本身無法提供任何有用的預測目標資訊。雖然資料欄本身可能不具有效資訊,但在與其他功能串聯使用來預測目標很有用,但分數較低可能表示該功能是多餘的。
例如,下列影像顯示了糖尿病分類問題的目標洩漏報告,即預測一個人是否患有糖尿病。AUC-ROC 曲線用來計算五個功能的預測能力,並確定所有功能都是安全的,不會發生目標洩漏。

多共線性
多共線性是兩個或多個預測器變數彼此相關的情況。預測器變數是資料集內,用來預測目標變數的功能。當您具有多重共線性時,預測器變數不僅可以預測目標變數,還可以預測彼此。
您可以使用變異數膨脹因子 (VIF)、主成份分析 (PCA)或套索功能選擇,以測量資料中多重共線性。如需更多資訊,請參閱下列內容。
偵測時間序列資料中的異常狀況
您可以使用異常偵測視覺化來查看時間序列資料中的極端值。要了解決異常狀況的原因,您需要了解我們將時間序列分解為預測項和錯誤項。我們將時間序列的季節性和趨勢視為預測項。我們將殘差視為錯誤項。
錯誤項的話,您可以指定閾值,作為殘差可偏離平均值的標準差數,以便將其視為異常狀況。例如,您可以將閾值指定為 3 個標準差。任何超過 3 個偏離平均值標準差的殘差都是異常狀況。
您可以使用下列程序來執行異常偵測分析。
-
開啟 Data Wrangler 資料流程。
-
在資料流程中的資料類型下,選擇 +,然後選取新增分析。
-
在分析類型部分,選擇時間序列。
-
在視覺化部分,選擇異常偵測。
-
在異常狀況閾值部分,選擇閾值以判定異常的值。
-
選擇預覽以產生分析的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
時間序列資料中的季節趨勢分解
您可以使用季節性趨勢分解視覺化,來判斷時間序列資料中是否有季節性。我們使用 STL (使用 LOESS 分解季節趨勢) 方法進行分解。我們將時間序列分解為季節性、趨勢和殘差部分。該趨勢反映了該系列的長期進展。季節性部分是在一段時間內反覆出現的訊號。從時間序列中移除趨勢和季節性部分後,就是殘差部分。
您可以使用下列程序來執行季節性-趨勢分解分析。
-
開啟 Data Wrangler 資料流程。
-
在資料流程中的資料類型下,選擇 +,然後選取新增分析。
-
在分析類型部分,選擇時間序列。
-
在視覺化中,選擇季節性-趨勢分解。
-
在異常狀況閾值部分,選擇閾值以判定異常的值。
-
選擇預覽以產生分析的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
偏差報告
您可以使用 Data Wrangler 中的偏差報告,發現資料中的潛在偏差。若要產生偏差報告,您必須指定要預測的目標欄或標籤以及一個構面,或是您要檢查偏差的欄。
標籤:關於您希望模型進行預測的功能。例如,如果您要預測客戶轉換率,則可以選取包含客戶是否已下訂單之資料的資訊欄。您還必須指定此功能是標籤還是閾值。如果您指定標籤,則必須指定正向結果在資料中的模樣。在客戶轉換率範例中,正向結果可以是訂單欄中的 1,代表客戶在過去三個月內下過訂單的正向結果。如果您指定閾值,則必須指定正向結果的下限。例如,如果您的客戶訂單欄包含去年下達的訂單數量,您可能需要指定 1。
構面:您要檢查偏差的資料欄。例如,如果您試圖預測客戶轉換率,則您的構面可能是客戶的年齡。您可以選擇此構面,因為您認為資料偏向於特定年齡群組。您必須確認構面是以值還是閾值來進行測量。例如,如果您想要檢查一或多個特定年齡,請選取值並指定這些年齡。如果您想要查看年齡群組,請選取閾值並指定您要檢查的年齡閾值。
選取功能和標籤後,您可以選取要計算的偏差指標類型。
如需進一步了解,請參閱透過訓練前資料產生偏差報告。
建立自訂視覺化
您可以將分析新增至 Data Wrangler 流程,以建立自訂視覺化。您的資料集和已套用的所有轉換,都可以作為Pandas DataFramedf變數來儲存資料框。您可以透過呼叫變數來存取資料框。
您必須提供輸出變數chart,才能儲存 Altair
import altair as alt df = df.iloc[:30] df = df.rename(columns={"Age": "value"}) df = df.assign(count=df.groupby('value').value.transform('count')) df = df[["value", "count"]] base = alt.Chart(df) bar = base.mark_bar().encode(x=alt.X('value', bin=True, axis=None), y=alt.Y('count')) rule = base.mark_rule(color='red').encode( x='mean(value):Q', size=alt.value(5)) chart = bar + rule
若要建立自訂視覺化:
-
在包含您想要視覺化之轉換的節點旁邊,選擇 +。
-
選擇 新增分析。
-
分析類型部分,請選擇自訂視覺化。
-
分析名稱部分,指定一個名稱。
-
在程式碼方框中輸入您的代碼。
-
選擇預覽以預覽視覺化。
-
選擇儲存以新增視覺化。

如果您不知道如何在 Python 使用 Altair 視覺化套裝元件,可以使用自訂程式碼片段來協助您入門。
Data Wrangler 有一個可搜尋的視覺化程式碼片段集合。若要使用視覺化程式碼片段,請選擇搜尋範例程式碼片段,然後在搜尋列中指定查詢。
下面的範例使用量化散點圖程式碼片段。它繪製出一份二維的長條圖。
這些程式碼片段有註解,可協助您了解您需要對程式碼進行的變更。您通常需要在程式碼中指定資料集的資料欄名稱。
import altair as alt # Specify the number of top rows for plotting rows_number = 1000 df = df.head(rows_number) # You can also choose bottom rows or randomly sampled rows # df = df.tail(rows_number) # df = df.sample(rows_number) chart = ( alt.Chart(df) .mark_circle() .encode( # Specify the column names for binning and number of bins for X and Y axis x=alt.X("col1:Q", bin=alt.Bin(maxbins=20)), y=alt.Y("col2:Q", bin=alt.Bin(maxbins=20)), size="count()", ) ) # :Q specifies that label column has quantitative type. # For more details on Altair typing refer to # https://altair-viz.github.io/user_guide/encoding.html#encoding-data-types
