本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
取得有關資料和資料品質的洞察
使用資料品質和洞察報告,對已匯入至 Data Wrangler 的資料執行分析。建議您在匯入資料集之後建立報告。您可以使用該報告來幫助您清理和處理資料。它為您提供相關資訊,像是缺少值的數量和極端值數量等。如果您的資料有問題,例如目標洩漏或不平衡,洞察報告可以提醒您注意這些問題。
使用下列程序建立資料品質與洞察報告。它假設您已將資料集匯入 Data Wrangler 流程。
若要建立資料品質與洞察報告
-
選擇 Data Wrangler 流程節點旁邊的 +。
-
選取取得資料洞見。
-
分析名稱的部分,指定洞察報告的名稱。
-
(選用) 針對目標欄的部分,指定目標欄。
-
為問題類型指定迴歸或分類。
-
針對資料大小,請指定下列其中一項:
-
50 K — 使用您已匯入資料集的前 50000 列來建立報告。
-
整個資料集 — 使用您匯入的整個資料集來建立報告。
注意
使用 Amazon SageMaker 處理任務建立整個資料集的資料品質和洞察報告。 SageMaker 處理任務會佈建所需的其他運算資源,以取得所有資料的見解。如需 SageMaker 處理工作的詳細資訊,請參閱使用處理工作執行資料轉換工作負載。
-
-
選擇建立。
下列主題顯示報告的各區段:
您可以下載報告或線上查看報告。若要下載報告,請選取畫面右上角的下載按鈕。下列影像顯示按鈕。

Summary
洞察報告提供資料的簡短摘要,其中包含一般資訊,例如缺少值、無效值、功能類型、極端值計數等。它還可以包含高嚴重性警告,指出資料可能出現的問題。出現警告時,建議您進行調查。
以下是報告摘要的範例。

目標欄
當您建立資料品質和洞察報告時,Data Wrangler 會提供選取目標欄的選項。目標欄是您試圖預測的資料欄。當您選擇目標欄時,Data Wrangler 會自動建立目標欄分析。它還按照其預測能力的順序,對功能進行排名。當您選取目標欄時,您必須指定要試圖解決迴歸還是分類問題。
分類問題的話,Data Wrangler 顯示一個資料表和直方圖,其中包含最常見的分類。一個類別就是一個分類。它還會呈現觀測值或資料行,顯示缺少或無效的目標值。
下列影像顯示分類問題的範例目標欄分析。
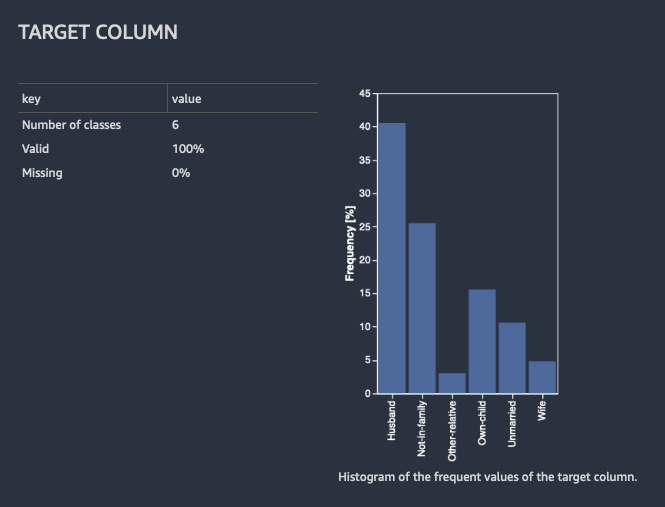
迴歸問題的話,Data Wrangler 會顯示目標欄中所有值的長條圖。它還會呈現觀測值或資料行,顯示缺少、無效或極端的目標值。
下列影像顯示迴歸問題的範例目標欄分析。

快速模型
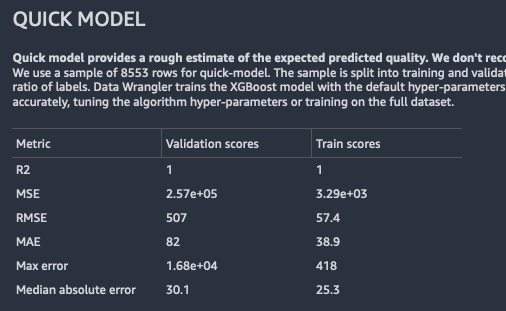
快速模型提供以您的資料訓練的模型,其預期的預測品質估計。
Data Wrangler 會將您的資料分割成訓練和驗證折疊。它使用 80% 的樣本進行訓練,20% 的值進行驗證。分類的話,取樣是採分層分割。分層分割情況下,每個資料分割區具有相同的標籤比例。分類問題的話,重要的是要在訓練和分類折疊之間保持相同的標籤比例。Data Wrangler 使用預設的超參數來訓練 XGBoost 模型。它適用於驗證資料提前停止的情形,並執行最小的功能預先處理。
分類模型的話,Data Wrangler 會傳回模型摘要和混淆矩陣。
以下是分類模型摘要的範例。若要進一步了解其傳回的資訊,請參閱定義。

以下是快速模型傳回之混淆矩陣的範例。

混淆矩陣為您提供以下資訊:
-
預測標籤與實際標籤相符的次數。
-
預測標籤與實際標籤不相符的次數。
實際標籤代表在資料中實際觀察到的情形。例如,如果您使用模型來偵測詐騙交易,則實際標籤代表該交易實際上是否為詐騙。預測標籤表示模型指派給資料的標籤。
您可以透過混淆矩陣,查看模型預測條件存在或不存在的情況。如果您要預測詐騙交易,則可以使用混淆矩陣來了解模型的敏感度和明確性。敏感度是指模型偵測詐騙交易的能力。明確性是指模型避免將非詐騙交易檢測為詐騙交易的能力。
以下是迴歸問題的快速模型輸出的範例。
功能摘要
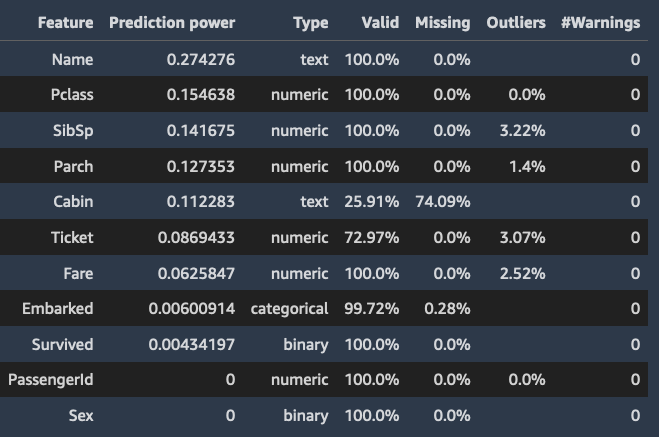
當您指定目標欄時,Data Wrangler 會依其預測力對功能排序。預測力是在資料分成 80% 訓練和 20% 驗證折疊之後測量的。針對訓練折疊上的每項個別特徵,Data Wrangler 都會對應一個模型。它會套用最少的特徵預處理,並測量驗證資料的預測效能。
它將分數標準化為 [0,1] 範圍。較高的預測分數,表示這些資料欄單獨使用時,對於預測目標更為有用。得分較低,表示這些欄對於預測目標欄來說不具預測能力。
當一欄單獨來看不具預測性時,它與其他欄搭配使用時通常也不會變得有預測性。您可以放心地使用預測分數,來判斷資料集內的特徵是否可預測。
分數較低通常表示該特徵是多餘的。分數為 1 意味著完美的預測能力,這通常表示目標洩漏。目標洩漏通常發生在資料集包含一個欄,其在預測時間內為不可用。例如,它可能是目標欄的副本。
以下是顯示每個特徵預測值的表格和長條圖的範例。

範例
Data Wrangler 會提供有關您的樣本是否異常,或資料集內是否有所重複的資訊。
Data Wrangler 使用隔離樹演算法偵測異常樣本。隔離樹會將異常狀況分數與資料集的每個樣本 (列) 產生關聯。低異常狀況分數表示出現異常樣本。高分與非異常樣本有關。具有負異常狀況分數的樣本通常被視為異常,具有正異常狀況分數的樣本被視為非異常。
當您查看可能異常的樣本時,我們建議您注意不尋常的值。例如,您的極端值可能是由於收集和處理資料時發生錯誤而產生的。以下是根據 Data Wrangler 對隔離樹演算法實作的最異常樣本範例。我們建議您在檢查異常樣本時,運用領域知識和商業邏輯。
Data Wrangler 會偵測重複的資料列,並計算資料中重複資料列的比例。某些資料來源可能包含有效的重複項。其他資料來源可能具有指向資料收集問題的重複項目。由於錯誤的資料收集而產生的重複範例,可能會干擾將資料分割為獨立訓練和驗證折疊的機器學習程序。
以下是可能受到重複樣本影響的洞察報告元素:
-
快速模型
-
預測力估算
-
自動超參數調校
您可以使用管理列底下的捨棄重複轉換工具,從資料集中移除重複樣本。Data Wrangler 會顯示最常重複的資料列。
定義
下列是資料洞見報告中使用的技術詞彙定義。
