本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
轉換資料
Amazon SageMaker Data Wrangler 提供大量的機器學習資料轉換,以簡化資料的清理、轉換和功能化作業。當您新增轉換時,它會在資料流程中新增一個步驟。您新增的每個轉換都會修改資料集並產生新的資料框。所有後續轉換都會套用至產生的資料框。
Data Wrangler 包含內建的轉換,您可以用它來轉換資料欄,而不需要任何程式碼。您還可以使用 PySpark、Python (使用者定義函式)、pandas 和 PySpark SQL 來新增自訂轉換。有些轉換會就地運作,而有些則會在資料集中建立新的輸出資料欄。
您可以一次將轉換套用至多個資料欄。例如,您可以在一個步驟中刪除多個欄位。
您只能將處理數字和處理遺漏的轉換套用至單一欄位。
使用此頁面進一步瞭解這些內建和自訂轉換。
轉換使用者介面
大部分的內建轉換都位於 Data Wrangler 使用者介面的準備索引標籤中。您可以透過資料流程視圖存取聯結和串連轉換。使用下表預覽這兩個視圖。




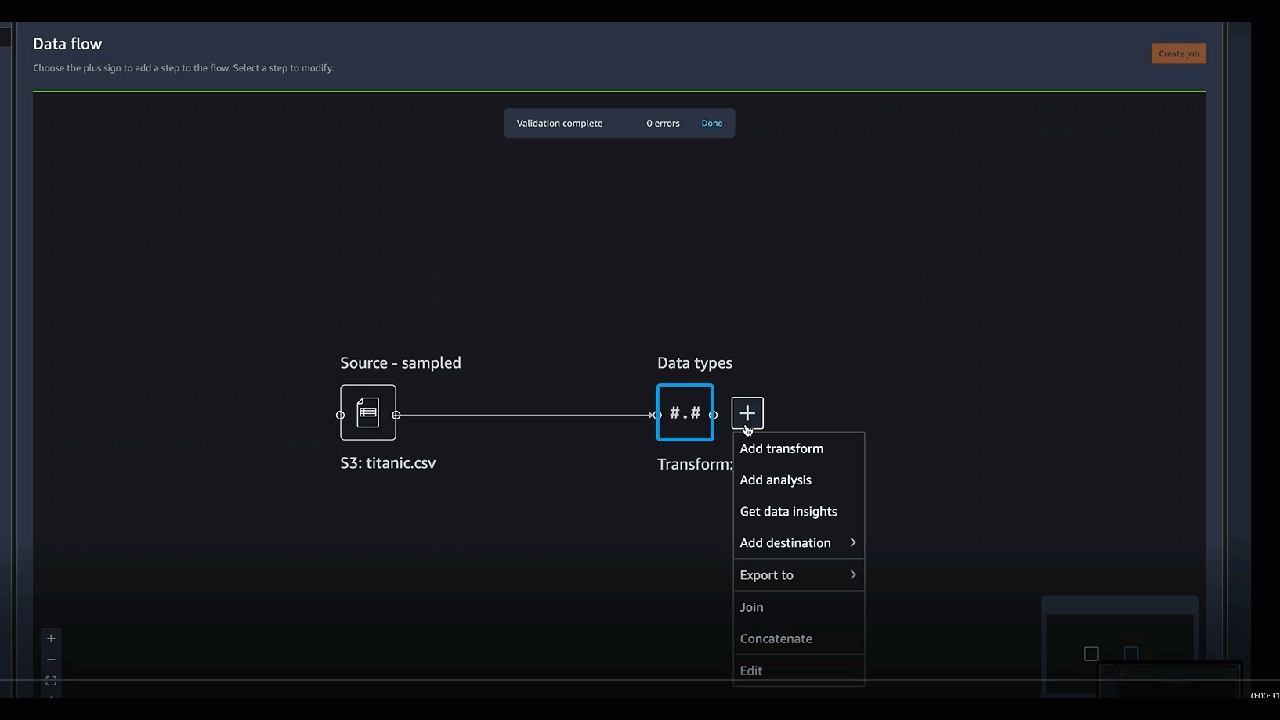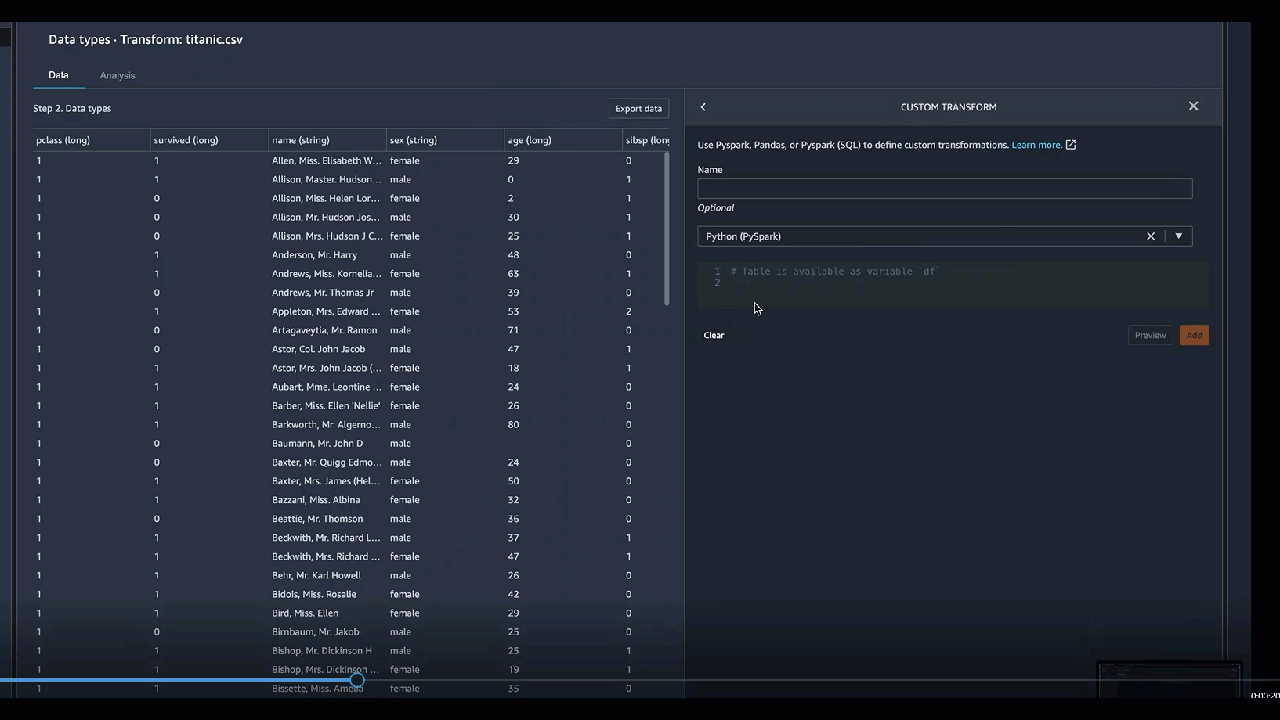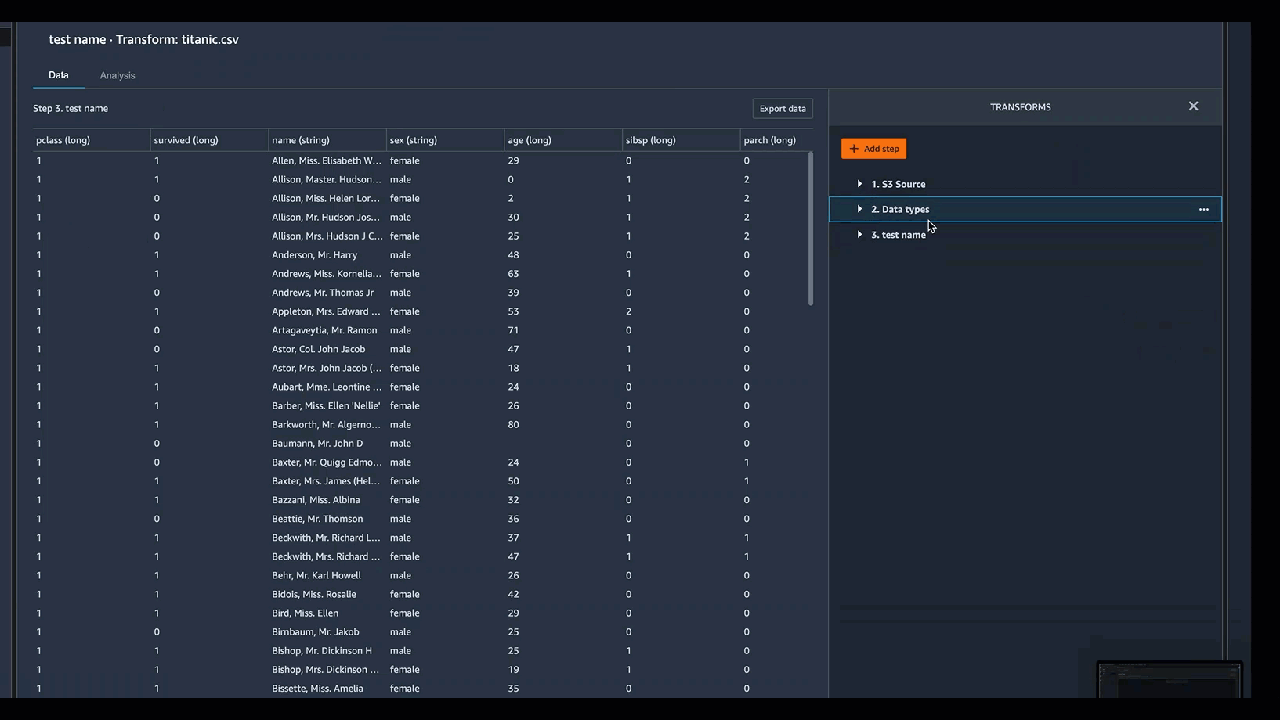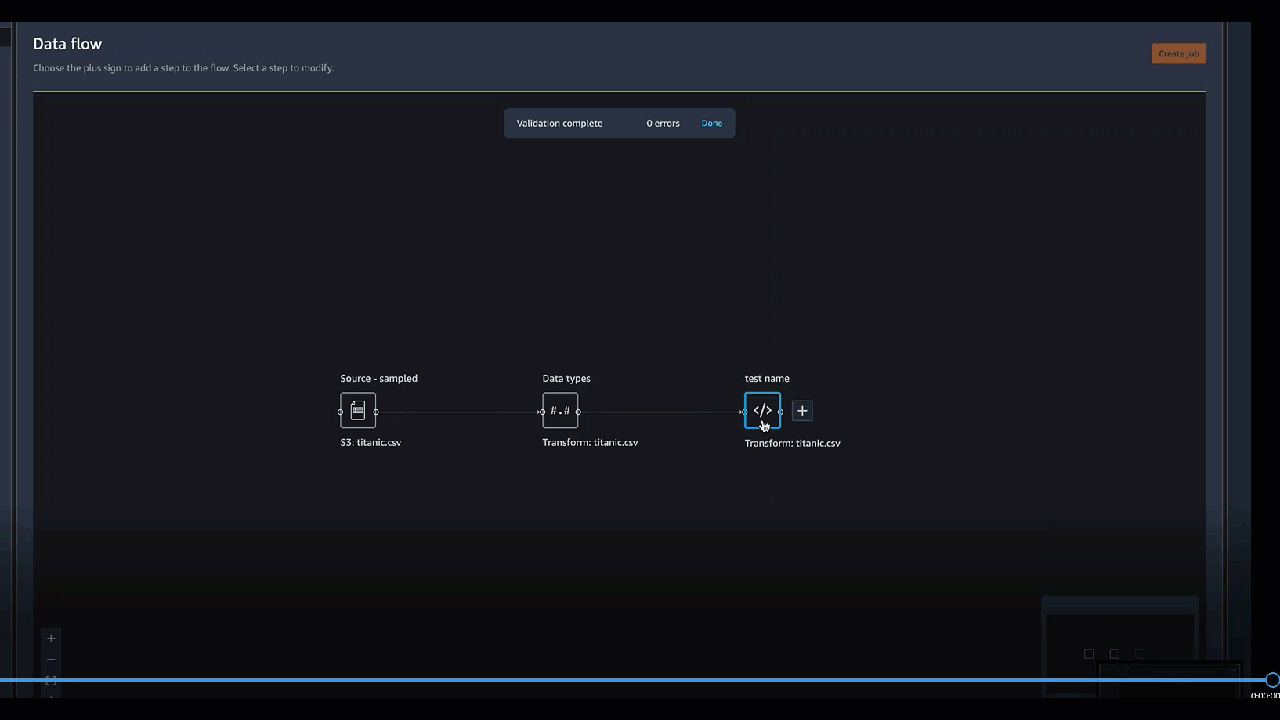
聯結資料集
您可以直接在資料流程中聯結資料框。聯結兩個資料集時,產生的聯結資料集會顯示在流程中。Data Wrangler 目前支援下列聯結類型。
-
Left Outer – 包括左表中的所有列。如果左側資料表列中聯結的資料欄值與右側資料表列值不相符,則該資料列會包含聯結資料表中所有右側資料表欄位的 Null 值。
-
Left Anti – 在聯結欄的右表中包含左側表格中不包含值的列。
-
Left semi – 針對符合聯結陳述式中標準的所有相同列,包括左側資料表中的單一資料列。這會排除左側資料表中符合聯結標準的重複資料列。
-
Right Outer – 包括右表中的所有列。如果右側資料表列中聯結的資料欄值與左側資料表列值不相符,則該資料列會包含聯結資料表中所有左側資料表欄位的 Null 值。
-
Inner – 包括左右表格中包含聯結欄中相符值的資料列。
-
Full Outer – 包括左側和右側表格中的所有列。如果任一表格中聯結資料欄的列值不相符,則會在聯結的表格中建立單獨的列。如果資料列不包含聯結資料表中的欄值,則會針對該資料欄插入 null。
-
Cartesian Cross – 包括將第一個表中的每一列與第二個表中的每一列合併的資料列。這是來自聯結表列的笛卡爾乘積
。乘積的結果是左表的大小乘以右表的大小。因此,我們建議您在非常大的資料集之間要謹慎使用此聯結。
使用以下程序來聯結兩個資料框。
-
選取要聯結的左側資料框旁的 +。您選取的第一個資料框始終是聯結中的左表。
-
選擇聯結。
-
選擇正確的資料框。您選取的第二個資料框始終是聯結中的右表。
-
選擇設定以設定您的聯結。
-
使用名稱欄位為聯結的資料集命名。
-
選取聯結類型。
-
從左側和右側表格中選取要聯結的資料欄。
-
選擇套用以預覽右側的聯結資料集。
-
若要將聯結資料表新增至資料流程,請選擇新增。
串連資料集
串連兩個資料集:
-
選擇要串連的左側資料框旁的 +。您選取的第一個資料框始終是串連中的左表。
-
選擇串連。
-
選擇右側的資料框。您選取的第二個資料框始終是串連中的右表。
-
選擇設定以設定您的串連。
-
使用名稱欄位為串連的資料集命名。
-
(選用) 選取串連後移除重複項目旁的核取方塊以移除重複的資料欄。
-
(選用) 如果您想要新增資料欄來源的指標,則對每個新資料集的資料欄選取新增資料欄以指示來源資料框旁的核取方塊。
-
選擇套用以預覽新資料集。
-
若要將新資料集新增至資料流程,請選擇新增。
平衡資料
您可以平衡不具代表性類別資料集的資料。平衡資料集可協助您建立更好的二進制分類模型。
注意
您無法平衡包含資料欄向量的資料集。
您可以使用平衡資料作業以使用下列任一個運算子平衡資料:
-
隨機過採樣 – 隨機複製少數類別中的範例。例如,如果您試圖偵測欺詐,則可能只有 10% 的資料中有欺詐案例。對於相同比例的欺詐和非欺詐性案件,此運算子會在資料集中隨機複製 8 次欺詐案例。
-
隨機欠採樣– 大致與隨機過採樣類似。從過度代表的類別中隨機移除範例,以獲得您想要的範例比例。
-
合成少數過採樣技術 (SMOTE) – 使用欠代表類別的範例插入新的合成少數範例。如需有關 SMOTE 的詳細資訊,請參閱以下說明。
您可以對同時包含數值和非數值特徵的資料集使用所有轉換。SMOTE 會使用相鄰範例來內插數值。Data Wrangler 使用 R 平方距離來決定附加範例內插的鄰近點。Data Wrangler 僅使用數字特徵來計算不具代表性群組中範例之間的距離。
對於不具代表性群組中的兩個實際範例,Data Wrangler 會使用加權平均值插補數字特徵。它將權重隨機分配給 [0, 1] 範圍內的範例。對於數字特徵,Data Wrangler 會使用範例的加權平均值插補樣本。對於範例 A 和 B,Data Wrangler 可以隨機分配權重 0.7 到 A,0.3 分配給 B。內插範例具有 0.7A + 0.3B 的值。
Data Wrangler 透過複製任一插補的實際範例來插補非數字特徵。它以隨機分配給每個範例的概率複製範例。對於範例 A 和 B,它可以將概率 0.8 分配給 A,將 0.2 分配給 B。對於它分配的機率,它在 80% 的情況下複製 A。
自訂轉換
自訂轉換群組允許您使用 Python (使用者定義函式)、PySpark、pandas 或 PySpark (SQL) 來定義自訂轉換。對於這三個選項,您可以使用變數 df 來存取要套用轉換的資料框。要將自訂程式碼應用於資料框,請分配具有對 df 變量進行的轉換的資料框。如果您不使用 Python (使用者定義函式),則無須納入 return 陳述式。選擇預覽以預覽自訂轉換的結果。選擇新增,將自訂轉換新增至上一個步驟清單。
您可以使用自訂轉換程式碼區塊中的 import 陳述式匯入常用程式庫,如下所示:
-
NumPy 版本 1.19.0
-
scikit-learn version 0.23.2
-
SciPy 版本 1.5.4
-
pandas 版本 1.0.3
-
PySpark 版本 3.0.0
重要
自訂轉換不支援名稱中包含空格或特殊字元的資料欄。建議您指定只有英數字元和底線的資料欄名稱。您可以使用管理資料欄中的重新命名資料欄轉換來轉換群組,以移除資料欄名稱的空格。您還可以新增類似於以下內容的 Python (Pandas)自訂轉換,以在一個步驟中從多個資料欄中刪除空格。這個範例會將名為 A
column 和 B column 的資料欄分別變更為 A_column 和 B_column。
df.rename(columns={"A column": "A_column", "B column": "B_column"})
如果您在程式碼區塊中包含列印陳述式,結果會在您選取預覽時顯示。您可以調整自訂程式碼轉換器面板的大小。調整面板大小會提供更多撰寫程式碼的空間。下列影像顯示調整面板大小的結果。
下列各節提供撰寫自訂轉換程式碼的其他內容和範例。
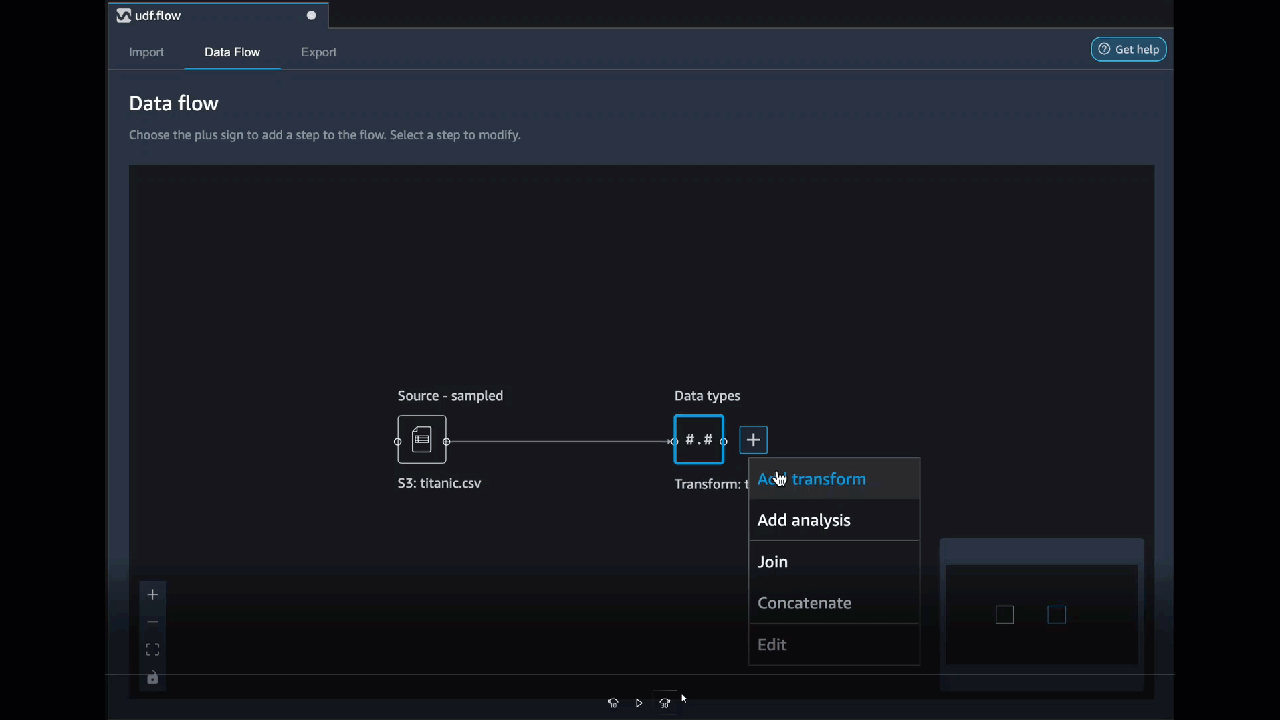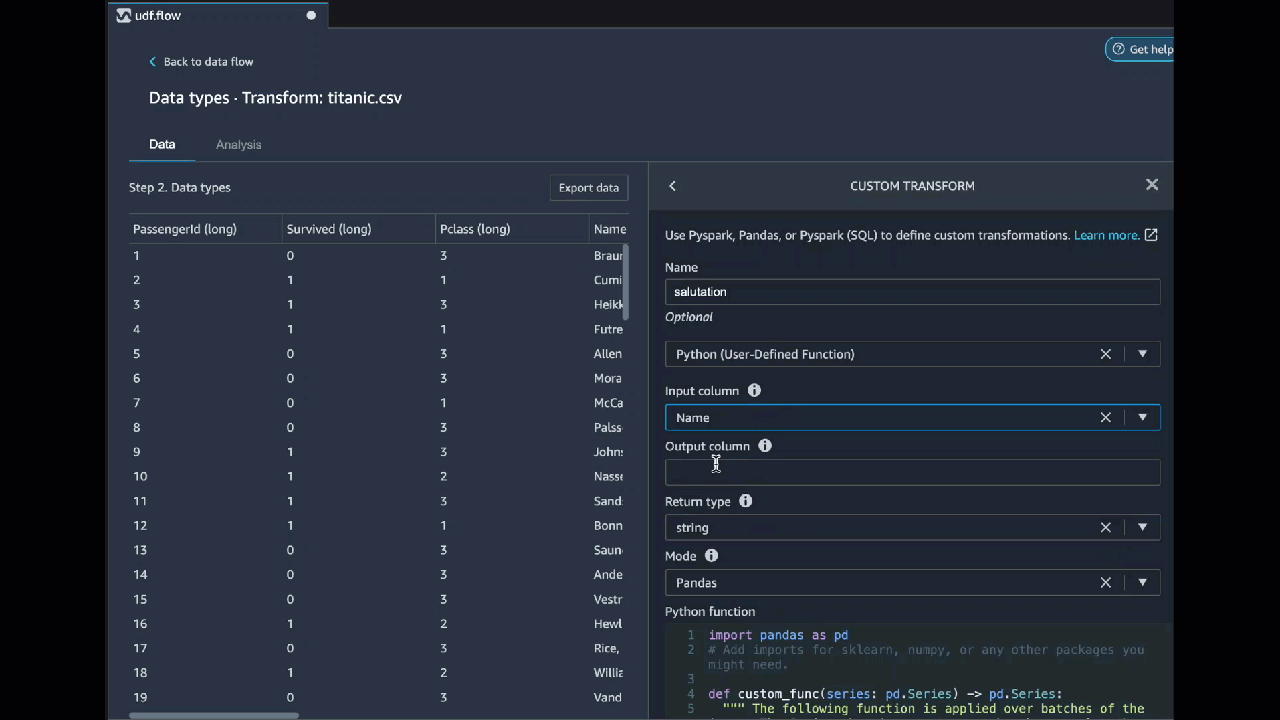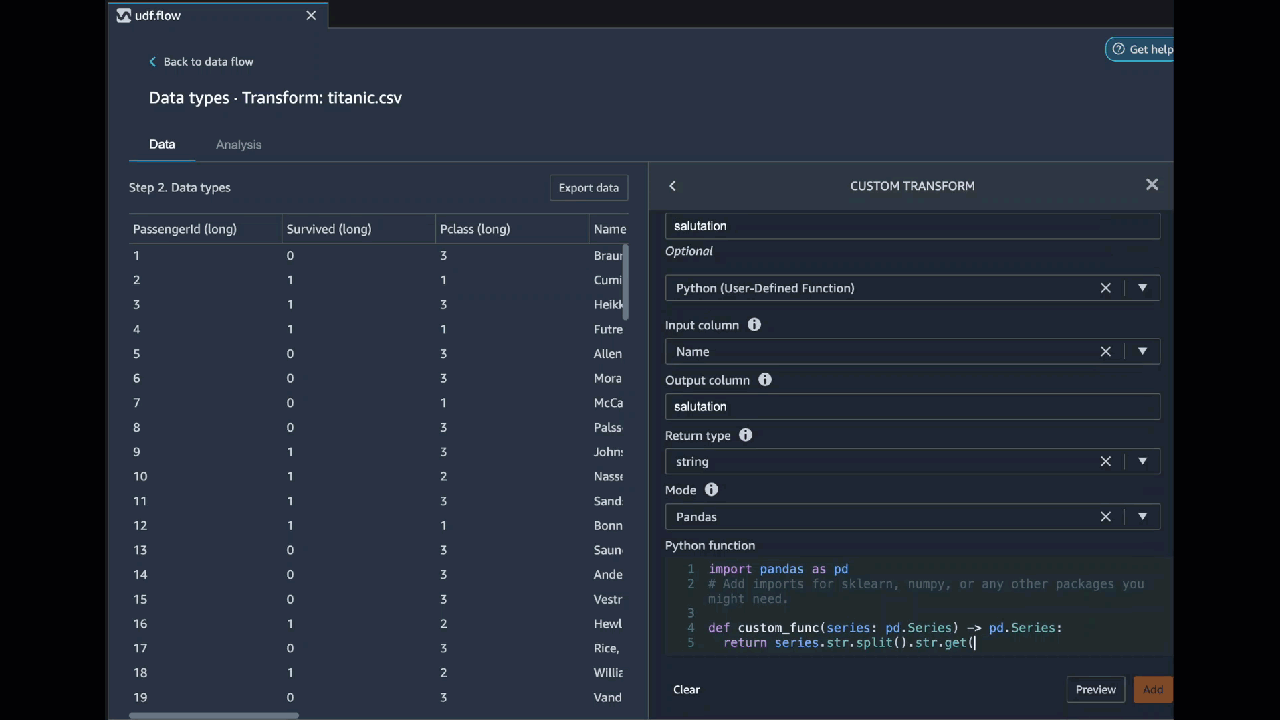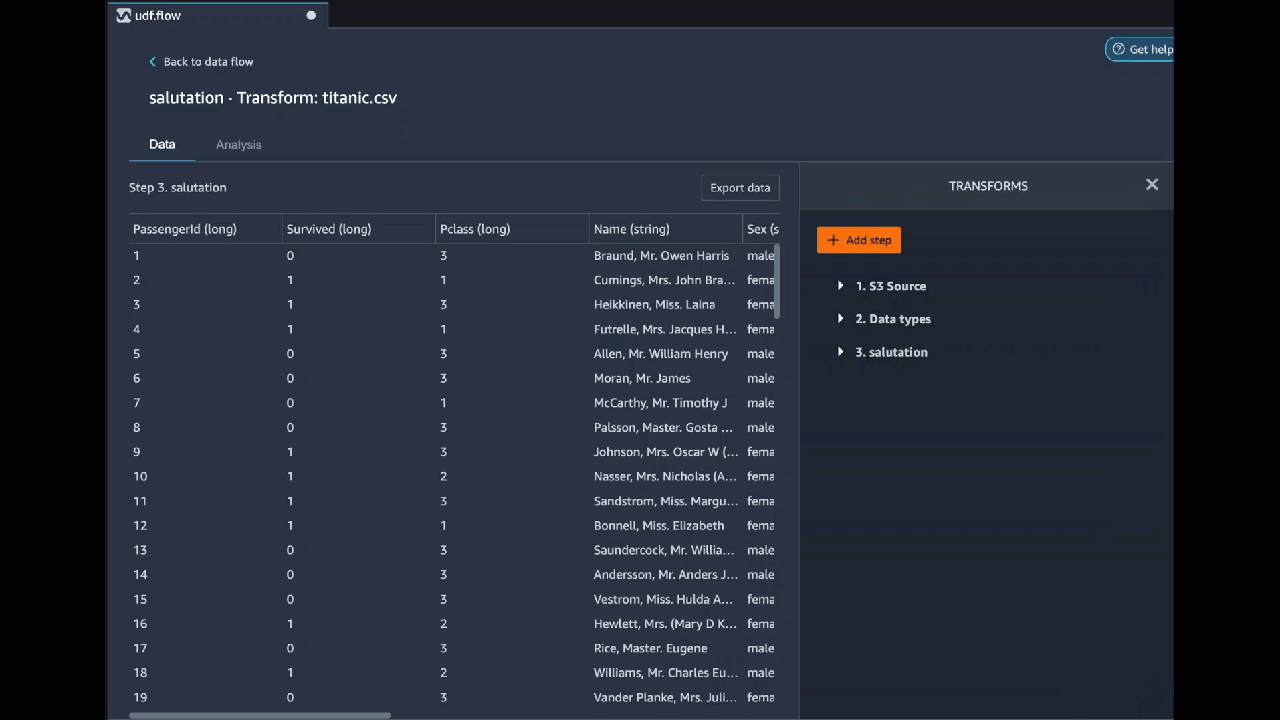
Python (使用者定義函式)
Python 函式使您能夠編寫自訂轉換,而無需知道 Apache Spark 或 pandas 的能力。Data Wrangler 經過最佳化,可以快速執行自訂程式碼。您可以使用自訂 Python 程式碼和 Apache Spark 外掛程式獲得類似的性能。
若要使用 Python (使用者定義函式) 程式碼區塊,請指定下列項目:
-
輸入資料欄 – 您要套用轉換的輸入資料欄。
-
模式 – 腳本模式,可以是 pandas 或 Python。
-
傳回類型 – 您要傳回值的資料類型。
使用 pandas 模式可提供更好的性能。Python 模式使您可以更輕鬆地使用純 Python 函式來編寫轉換。
下列影片顯示如何使用自訂程式碼建立轉換的範例。它使用 Titanic 資料集
PySpark
下列範例會從時間戳記擷取日期和時間。
from pyspark.sql.functions import from_unixtime, to_date, date_format df = df.withColumn('DATE_TIME', from_unixtime('TIMESTAMP')) df = df.withColumn( 'EVENT_DATE', to_date('DATE_TIME')).withColumn( 'EVENT_TIME', date_format('DATE_TIME', 'HH:mm:ss'))
pandas
下列範例提供您要新增轉換之資料框的概觀。
df.info()
PySpark (SQL)
以下範例建立了一個包含以下四個資料欄的新資料框:姓名、船票價格、船票等級、是否倖存。
SELECT name, fare, pclass, survived FROM df
如果您不知道如何使用 PySpark,可以使用自訂程式碼片段來協助您入門。
Data Wrangler 有一個可搜尋的程式碼片段集合。您可以使用程式碼片段來執行工作,例如捨棄欄、按欄分組或建立模型。
若要使用程式碼片段,請選擇搜尋範例程式碼片段,然後在搜尋列中指定查詢。您在查詢中指定的文字不一定要完全符合程式碼片段的名稱。
下列範例顯示捨棄重複資料列程式碼片段,此程式碼片段可刪除資料集中具有類似資料的資料列。您可以搜尋下列其中一項來尋找程式碼片段:
-
Duplicates (複製)
-
Identical (相同)
-
Remove (移除)
下列程式碼片段有註解,可協助您瞭解您需要進行的變更。對於大多數程式碼片段,您必須在程式碼中指定資料集的資料欄名稱。
# Specify the subset of columns # all rows having identical values in these columns will be dropped subset = ["col1", "col2", "col3"] df = df.dropDuplicates(subset) # to drop the full-duplicate rows run # df = df.dropDuplicates()
若要使用程式碼片段,請將其內容複製並貼到自訂轉換欄位中。您可以將多個程式碼片段複製並貼到自訂轉換欄位中。
自訂公式
使用自訂公式可使用 Spark SQL 運算式來定義新資料欄,以查詢目前資料框中的資料。查詢必須使用 Spark SQL 運算式的慣例。
重要
自訂公式不支援名稱中包含空格或特殊字元的資料欄。建議您指定只有英數字元和底線的資料欄名稱。您可以使用管理資料欄中的重新命名資料欄轉換來轉換群組,以移除資料欄名稱的空格。您還可以新增類似於以下內容的 Python (Pandas)自訂轉換,以在一個步驟中從多個資料欄中刪除空格。這個範例會將名為 A
column 和 B column 的資料欄分別變更為 A_column 和 B_column。
df.rename(columns={"A column": "A_column", "B column": "B_column"})
您可以使用此轉換對資料欄執行作業,並依名稱參照資料欄。例如,假設目前的資料框包含名為 col_a 和 col_ b 的資料欄,您可以使用以下操作產生一個輸出欄,該欄是這兩個欄的乘積,程式碼如下:
col_a * col_b
假設資料框包含 col_a 和 col_b 欄,則其他常見操作包括以下內容:
-
串連兩欄:
concat(col_a, col_b) -
新增兩欄:
col_a + col_b -
減去兩欄:
col_a - col_b -
分隔兩欄:
col_a / col_b -
取一欄的絕對值:
abs(col_a)
如需詳細資訊,請參閱選取資料相關的 Spark 文件
降低資料集內的維度
使用主元件分析 (PCA) 降低資料的維度。資料集的維度會對應特徵數量。當您在 Data Wrangler 中使用降維時,您會得到一組稱為元件的新特徵。每個元件都會考慮資料中的某些變異。
第一個元件會考慮資料中最大的變異量。第二個元件會考慮資料中第二大的變異量,以此類推。
您可以使用降維來減少用於訓練模型的資料集大小。您可以改用主體元件,而不是使用資料集中的特徵。
若要執行 PCA,Data Wrangler 會為您的資料建立軸。軸是資料集中資料欄的仿射組合。第一個主元件是軸上具有最大變異數的值。第二個主元件是軸上具有第二大變異數的值。第 n 個主元件是軸上具有第 n 大變異數的值。
您可以設定 Data Wrangler 傳回的主元件數目。您可以直接指定主要元件的數目,也可以指定變異數閾值百分比。每個主元件都會解釋資料中的變異數。例如,您可能有一個值為 0.5 的主元件。該元件將說明 50% 的資料變異數。當您指定變異數閾值百分比時,Data Wrangler 會傳回符合指定百分比的最小元件數目。
以下是主體元件範例,其中包含它們在資料中解釋的變異數。
-
元件 1 – 0.5
-
元件 2 – 0.45
-
元件 3 – 0.05
如果您指定 94 或 95 的變異數閾值百分比,則 Data Wrangler 會傳回元件 1 和元件 2。如果您指定 96 的變異數閾值百分比,則 Data Wrangler 會傳回所有三個主要元件。
您可以使用下列程序在資料集上執行 PCA。
若要在資料集上執行 PCA,請執行以下操作。
-
開啟 Data Wrangler 資料流程。
-
選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇降維。
-
對於輸入資料欄,請選擇要縮減為主要元件的特徵。
-
(選用) 在主要元件數目中,選擇 Data Wrangler 在資料集中傳回的主要元件數目。如果指定欄位的值,就無法指定變異數閾值百分比的值。
-
(選用) 針對變異數閾值百分比,指定您要由主體元件解釋的變異數百分比。如果您未指定變異數閾值的話,Data Wrangler 會使用
95的預設值。如果您已指定 主要元件數目的值,則無法指定變異數閾值百分比。 -
(選用) 取消選取置中以不使用資料欄的平均值做為資料的中心。根據預設,Data Wrangler 會在調整資料之前以平均值為中心。
-
(選用) 取消選取縮放,不會以單位標準差縮放資料。
-
(選用) 選擇資料欄,將元件輸出至不同的資料欄。選擇向量,將元件輸出為單一向量。
-
(選用) 對於 輸出欄,指定輸出資料欄的名稱。如果要將元件輸出到單獨的欄,則指定的名稱為字首。如果要將元件輸出到向量,則指定的名稱是向量欄的名稱。
-
(選用) 選取保留輸入資料欄。如果您計劃僅使用主體元件來訓練模型,則不建議選取此選項。
-
選擇預覽。
-
選擇新增。
分類編碼
分類資料通常由有限數量的類別組成,其中每個類別都以字串表示。例如,如果您有一個客戶資料表,則表示使用者所居住的國家/地區的資料欄即為類別。類別為阿富汗、阿爾巴尼亞、阿爾及利亞等。分類資料可以是名目或序數。序數類別具有固有的順序,名目類別則沒有。獲得的最高學位 (高中、學士、碩士等) 是序數類別的一個例子。
編碼分類資料是為類別建立數值表示的過程。例如,如果您的類別是狗和貓,則可以將此資訊編碼為兩個向量,[1,0] 表示 狗,而 [0,1] 表示貓。
當您編碼序數類別時,您可能需要將類別的自然順序轉換為編碼。例如,您可以透過以下地圖表示取得的最高學位:{"High school": 1, "Bachelors": 2,
"Masters":3}。
使用分類編碼將字串格式的分類資料編碼為整數陣列。
Data Wrangler 分類編碼器會在定義步驟時,為資料欄中存在的所有類別建立編碼。您啟動 Data Wrangler 工作以在時間 t 處理資料集時,如果已將新類別新增至資料欄,而且此資料欄是在 t-1 時間進行 Data Wrangler 分類編碼轉換的輸入,則這些新類別會被視為在 Data Wrangler 工作中遺失。您為無效處理策略選取的選項會套用至這些缺少值上。何時可能發生這種情況的範例如下:
-
當您使用 .flow 檔案建立 Data Wrangler 工作以處理在建立資料流程後更新的資料集時。例如,您可以使用資料流程來定期處理每個月的銷售資料。如果銷售資料每週更新一次,則可能會在已定義編碼分類步驟的欄中引入新類別。
-
當您在匯入資料集時,選取取樣,某些類別可能會被排除在範例之外。
在這些情況下,這些新類別會被視為 Data Wrangler 工作中的缺少值。
您可以選擇和設定序數和 one-hot 編碼。閱讀下列章節以進一步瞭解這些選項。
這兩種轉換都會建立名為輸出欄名稱的新資料欄。您可以使用輸出樣式以指定此資料欄的輸出格式:
-
選取向量以產生含稀疏向量的單一資料欄。
-
選取資料欄可為每個類別建立一個欄,其中包含一個指標變數,用於指示原本資料欄中的文字是否包含等於該類別的值。
序數編碼
選取序數編碼,將類別編碼為介於 0 和所選輸入欄中類別總數之間的整數。
無效的處理策略:選取處理無效或缺少值的方法。
-
如果您要省略缺少值的資料列,請選擇略過。
-
選擇保留,將缺少值保留為最後一個類別。
-
如果您希望 Data Wrangler 在輸入欄中遇到缺少值時擲回錯誤,請選擇錯誤。
-
選擇以 NaN 取代,以用 NaN 取代缺少值。如果您的機器學習 (ML) 演算法可以處理缺少值,則建議使用此選項。否則,此清單中的前三個選項可能會產生更好的結果。
One-Hot 編碼
為轉換選取 One-hot 編碼,即可使用 one-hot 編碼。使用下列項目設定此轉換:
-
捨棄最後一個類別:如果
True,則最後一個類別在 one-hot 編碼中沒有對應的索引。如果可能存在缺少值,則缺少的類別始終為最後一個類別,並將其設定為True表示缺少值會導致全部零向量。 -
無效的處理策略:選取處理無效或缺少值的方法。
-
如果您要省略缺少值的資料列,請選擇略過。
-
選擇保留,將缺少值保留為最後一個類別。
-
如果您希望 Data Wrangler 在輸入欄中遇到缺少值時擲回錯誤,請選擇錯誤。
-
-
輸入序數是否編碼:如果輸入向量包含序數編碼資料,請選取此選項。此選項要求輸入資料包含非負數整數。如果為 True,則輸入 i 會編碼為第 i 個位置中具有非零的向量。
相似性編碼
當您具有以下條件時,請使用相似性編碼:
-
大量的類別變數
-
雜訊資料
相似性編碼器為具有分類資料的資料欄建立嵌入。內嵌是指從離散物件 (例如單字) 到實數向量的映射。它將類似的字串編碼為包含相似值的向量。例如,它為 “California” 和 “Calfornia” 建立非常相似的編碼。
Data Wrangler 會使用 3 gram 權杖產生器,將資料集中的每個類別轉換成一組權杖。它將權杖轉換為使用 mini-hash 編碼的內嵌。
以下範例示範相似性編碼器如何從字串建立向量。


Data Wrangler 建立的相似性編碼:
-
具有較低的維度
-
可擴展到大量類別
-
堅固耐用且抗雜噪
由於上述原因,相似性編碼比 one-hot 編碼更多樣化。
使用下列程序,新增相似性編碼轉換。
若要使用相似性編碼,請執行以下操作。
-
選擇開啟 Studio Classic。
-
選擇啟動應用程式。
-
選擇 Studio。
-
指定資料流程。
-
選擇具有轉換的步驟。
-
選擇新增步驟。
-
選擇編碼分類。
-
指定下列內容:
-
轉換 – 相似性編碼
-
輸入資料欄 – 包含您正在編碼的分類資料欄。
-
目標維度 – (選用) 分類內嵌向量的維度。預設值為 30。如果您的大型資料集包含許多類別,建議您使用較大的目標維度。
-
輸出樣式 – 針對包含所有編碼值的單一向量選擇向量。選擇資料欄將編碼值放在不同的資料欄中。
-
輸出資料欄 – (選用) 向量編碼輸出的輸出資料欄名稱。對於資料欄編碼的輸出,這是資料欄名稱的字首,隨後接續列出的數字。
-
功能化文字
使用功能化文字轉換群組來偵測字串類型的資料欄,並使用內嵌文字來功能化這些資料欄。
此特徵群組包含兩個功能,分別為字元統計資料和向量化。閱讀下列章節以進一步瞭解這些轉換。對於這兩個選項,輸入欄必須包含文字資料 (字串類型)。
字元統計資料
使用字元統計資料來產生包含文字資料之資料欄中每一個資料列的統計資料。
此轉換會針對每一列計算下列比率和計數,並建立新資料欄來報告結果。新資料欄的名稱是使用輸入資料欄名稱做為字首,以及特定比率或計數的字尾。
-
字數:該行中的單詞總數。此輸出資料欄的字尾為
-stats_word_count。 -
字元數:該列中的字元總數。此輸出資料欄的字尾為
-stats_char_count。 -
上限比率:A 到 Z 的大寫字元數除以欄中的所有字元。此輸出資料欄的字尾為
-stats_capital_ratio。 -
下限比率:a 到 z 的小寫字元數除以欄中的所有字元。此輸出資料欄的字尾為
-stats_lower_ratio。 -
位數比率:單一列中的位數與輸入欄中的位數總合的比率。此輸出資料欄的字尾為
-stats_digit_ratio。 -
特殊字元比率:非英數字元 (例如 #$&%:@ 等字元) 與輸入欄中所有字元總和的比率。此輸出資料欄的字尾為
-stats_special_ratio。
向量化
文字嵌入涉及將字彙中的單字或片語映射到實數向量。使用 Data Wrangler 文字內嵌轉換,以將權杖化和向量化文字資料轉為詞頻逆向檔案頻率 (TF-IDF) 向量。
當針對一欄文字資料計算 TF-IDF 時,每個句子中的每個單字都會轉換成代表其語意重要性的實數。較高的數字與較不頻繁的單詞相關聯,這往往會更有意義。
定義向量化轉換步驟時,Data Wrangler 會使用資料集中的資料來定義 CountVectorizer 和 TF-IDF 方法。執行 Data Wrangler 工作會使用這些相同的方法。
您可以使用下列項目設定此轉換:
-
輸出資料欄名稱:此轉換作業會建立含有內嵌文字的新資料欄。使用此欄位可指定此輸出資料欄的名稱。
-
權杖產生器:權杖產生器將句子轉換為單詞或權杖清單。
選擇標準以使用透過空格分割並將每個單字轉換為小寫的權杖產生器。例如,
"Good dog"會被權杖化為["good","dog"]。選擇自訂以使用自訂的權杖產生器。如果您選擇自訂,您可以透過下列欄位來設定權杖產生器:
-
權杖長度下限:有效權杖的最小長度 (以字元為單位)。預設為
1。例如,如果您指定3為權杖長度下限,則會從權杖化句子中捨棄類似a, at, in的文字。 -
Reggex 應該在差距上分割:如果選擇,Regex 會在差距上分割。否則則會符合權杖。預設為
True。 -
Regex 模式:定義權杖化程序的 Regex 模式。預設為
' \\ s+'。 -
轉為小寫:如果選擇,則 Data Wrangler 在權杖化之前會將所有字元轉換為小寫字母。預設為
True。
如需進一步了解,請參閱權杖產生器
上的 Spark 文件。 -
-
向量化器:向量化器會將權杖清單轉換為稀疏的數值向量。每個權杖對應於向量中的索引,而非零表示輸入句子中存在權杖。您可以從兩個向量化器選項中進行選擇,計數和雜湊。
-
計數向量化允許自訂不常見或過於常見權杖的篩選條件。計數向量化參數包含以下內容:
-
字詞頻率下限:在每一列中,會篩選頻率較低的字詞 (權杖)。如果指定整數,此整數為絕對閾值 (含)。如果您指定介於 0 (含) 和 1 之間的分數,則閾值與總字詞數相關。預設為
1。 -
文件頻率下限:必須呈現包含字詞 (權杖) 的列數下限。如果指定整數,此整數為絕對閾值 (含)。如果您指定介於 0 (含) 和 1 之間的分數,則閾值與總字詞數相關。預設為
1。 -
文件頻率上限:必須呈現包含字詞 (權杖) 的文件 (列) 數上限。如果指定整數,此整數為絕對閾值 (含)。如果您指定介於 0 (含) 和 1 之間的分數,則閾值與總字詞數相關。預設為
0.999。 -
字彙大小上限:字彙的大小上限。字彙由資料欄中所有列中的所有字詞 (權杖) 組成。預設為
262144。 -
二進位輸出:如果選取,向量輸出不包括文件中字詞的出現次數,而是其出現次數的二進位指標。預設為
False。
要進一步了解此選項,請參閱與 CountVectorizer
相關的 Spark 文件。 -
-
雜湊計算速度更快。雜湊向量化參數包含以下內容:
-
雜湊期間的特徵數:雜湊向量器根據其雜湊值將權杖映射到向量索引。此特徵決定可能的雜湊值的數目。較大的值會女導致雜湊值之間的衝突較少,但維度輸出向量較高。
要進一步了解此選項,請參閱與 FeatureHasher
相關的 Spark 文件。 -
-
-
套用 IDF會套用 IDF 轉換,該轉換會將術語出現頻率與用於 TF-IDF 嵌入的標準反向文件頻率相乘。IDF 參數包含以下項目:
-
文件頻率下限:必須呈現包含字詞 (權杖) 的文件 (列) 數下限。如果 count_vectorize 是選擇的向量化器,我們建議您保留預設值,並且只在計數向量化參數中修改 min_doc_freq 欄位。預設為
5。
-
-
輸出格式:每列的輸出格式。
-
選取向量以產生含稀疏向量的單一資料欄。
-
選取平面化可為每個類別建立一個欄,其中包含一個指標變數,用於指示原本資料欄中的文字是否包含等於該類別的值。只有當向量化器設定為計數向量化器時,您才能選擇平面化。
-
轉換時間序列
在 Data Wrangler 中,您可以轉換時間序列資料。時間序列資料集中的值會編製索引至特定時間。例如,顯示一天中每小時商店中客戶數量的資料集就是時間序列資料集。下表顯示時間序列資料集的範例。
每小時店內客戶數
| 顧客人數 | 時間 (小時) |
|---|---|
| 4 | 09:00 |
| 10 | 10:00 |
| 14 | 11:00 |
| 25 | 12:00 |
| 20 | 13:00 |
| 18 | 14:00 |
對於前面的表格,客戶數量欄包含時間序列資料。時間序列資料會根據時間 (小時) 欄中的每小時資料編製索引。
您可能需要對資料執行一系列轉換,才能取得可用於分析格式的資料。使用時間序列轉換群組來轉換您的時間序列資料。如需有關您可以執行的轉換詳細資訊,請參閱下列各節。
主題
依時間序列分組
您可以透過作業群組,將資料欄中特定值的時間序列資料分組。
例如,下列表格可讓您追蹤家庭每日平均用電量。
平均每日家庭用電量
| 家庭 ID | 每日時間戳 | 用電量 (千瓦小時) | 住戶人數序列 |
|---|---|---|---|
| household_0 | 1/1/2020 | 30 | 2 |
| household_0 | 1/2/2020 | 40 | 2 |
| household_0 | 1/4/2020 | 35 | 3 |
| household_1 | 1/2/2020 | 45 | 3 |
| household_1 | 1/3/2020 | 55 | 4 |
如果您選擇按 ID 進行分組,您會得到下表。
用電量按家庭 ID 分組
| 家庭 ID | 用電量序列 (千瓦小時) | 住戶人數序列 |
|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] |
| household_1 | [45, 55] | [3, 4] |
時間序列中的每個項目都會依對應的時間戳記排序。序列的第一個元素對應於該系列的第一個時間戳記。對於 household_0,30是用電量序列的第一個值。30 的值對應於 1/1/2020 的第一個時間戳記。
您可以包含開始時間戳記和結束時間戳記。下表顯示該資訊的顯示方式。
用電量按家庭 ID 分組
| 家庭 ID | 用電量序列 (千瓦小時) | 住戶人數序列 | Start_time | End_time |
|---|---|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] | 1/1/2020 | 1/4/2020 |
| household_1 | [45, 55] | [3, 4] | 1/2/2020 | 1/3/2020 |
您可以透過下列程序,依照時間序列資料欄分組。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇時間序列。
-
在變形下,選擇分組條件。
-
在依此欄分組中指定資料欄。
-
對套用至欄指定一個值。
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
重新取樣時間序列資料
時間序列資料通常具有不定期取樣的觀察值。例如,資料集可能會有一些每小時記錄的觀察值,以及每兩個小時記錄一次的其他觀察值。
許多分析,例如預測演算法,都需要定期取樣觀察值。重新取樣可讓您為資料集中的觀察值建立定期間隔的取樣時間。
您可以對時間序列進行擴大取樣或縮減取樣。縮減取樣會增加資料集中觀察值取樣的間隔時間。例如,如果您縮減取樣每小時或每兩個小時取樣一次的觀察值,則資料集中的每個觀察值會每兩小時取樣一次。每小時觀察值會使用彙總方法 (例如平均值或中值) 彙總成單一值。
擴大取樣縮減資料集中觀察取樣的間隔時間。例如,如果您將每兩個小時採樣一次的觀測值擴大取樣為每一小時取樣一次,則可以使用插補方法從每兩個小時取樣的觀察值來推斷每小時觀察值。如需有關插補方法的資訊,請參閱pandas.DataFrame.interpolate
您可以重新取樣數值和非數值資料。
使用重新取樣作業重新取樣時間序列資料。如果您的資料集中有多個時間序列,Data Wrangler 會將每個時間序列的時間間隔標準化。
下表顯示使用均值作為彙總方法以縮減取樣時間序列資料的範例。資料會從每兩個小時縮減取樣到每小時一次。
縮減取樣前一天的每小時溫度讀數
| 時間戳記 | 溫度 (攝氏) |
|---|---|
| 12:00 | 30 |
| 1:00 | 32 |
| 2:00 | 35 |
| 3:00 | 32 |
| 4:00 | 30 |
溫度讀數縮減取樣至每兩小時
| 時間戳記 | 溫度 (攝氏) |
|---|---|
| 12:00 | 30 |
| 2:00 | 33.5 |
| 4:00 | 35 |
您可以透過下列程序,重新取樣照時間序列資料。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇重新取樣。
-
對於時間戳記,選擇時間戳記欄。
-
對於頻率單位,指定要重新取樣的頻率。
-
(選用) 指定頻率數量的值。
-
指定剩餘欄位以設定轉換。
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
處理缺少的時間序列資料
如果資料集中有缺少值,您可以執行以下其中一項作業:
-
對於具有多個時間序列的資料集,請捨棄缺少值大於指定閾值的時間序列。
-
使用時間序列中的其他值來推算時間序列中的缺少值。
推算缺少值涉及透過指定一個值或透過使用推論方法來取代資料。以下是您可以用於推算的方法:
-
常數值 – 以您指定的值取代資料集中所有遺失的資料。
-
最常見的值 – 以資料集中出現頻率最高的值取代所有遺失的資料。
-
向前填充 – 使用向前填充,將缺少值取代為缺少值之前的非缺少值。對於序列:[2,4,7,NaN,NaN,Nan, 8],所有缺少值取代為 7。使用向前填充後產生的序列為 [2, 4, 7, 7, 7, 7, 8]。
-
向後填充 – 使用向後填充,將缺少值取代為缺少值後面的非缺少值。對於序列:[2,4,7,NaN,NaN,Nan, 8],所有缺少值取代為 8。使用向後填充後產生的序列為 [2, 4, 7, 8, 8, 8, 8]。
-
插補 – 使用插補函式來推算缺少值。如需有關可用於插補的函式詳細資訊,請參閱 pandas.DataFrame.interpolate
。
某些推算方法可能無法推算出資料集的所有缺少值。例如,向前填充無法推算出現在時間序列開頭的缺少值。您可以使用向前填充或向後填充來推算值。
您可以推算儲存格內或資料欄內的缺少值。
以下範例顯示如何在儲存格內推算值。
用電量的缺少值
| 家庭 ID | 用電量序列 (千瓦小時) |
|---|---|
| household_0 | [30, 40, 35, NaN, NaN] |
| household_1 | [45, NaN, 55] |
使用向前填充推算出用電量的值
| 家庭 ID | 用電量序列 (千瓦小時) |
|---|---|
| household_0 | [30, 40, 35, 35, 35] |
| household_1 | [45, 45, 55] |
以下範例顯示如何在資料欄內推算值。
家庭平均每日用電量的缺少值
| 家庭 ID | 用電量 (千瓦小時) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | NaN |
| household_1 | NaN |
| household_1 | NaN |
使用向前填充推算出平均每日家庭用電量的值
| 家庭 ID | 用電量 (千瓦小時) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | 40 |
| household_1 | 40 |
| household_1 | 40 |
您可以使用以下程序處理缺少值。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇處理缺少。
-
針對時間序列輸入類型,選擇是要處理儲存格內部或資料欄的缺少值。
-
對於為此欄輸入缺少值,請指定具有缺少值的資料欄。
-
對於推算值的方法,請選取一種方法。
-
指定剩餘欄位以設定轉換。
-
選擇預覽以產生轉換的預覽。
-
如果缺少值,您可以在用於推算值的方法下指定推算值的方法。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
驗證時間序列資料的時間戳記
您可能有無效的時間戳記資料。您可以使用驗證時間戳記功能來判斷資料集中的時間戳記是否有效。您的時間戳記可能因以下一個或多個原因而無效:
-
您的時間戳記欄有缺少值。
-
時間戳記欄中的值格式不正確。
如果您的資料集中有無效的時間戳記,就無法成功執行分析。您可以使用 Data Wrangler 識別無效的時間戳記,並了解您需要清理資料的位置。
時間序列驗證可以下列兩種的其中一種方式運作:
您可以設定 Data Wrangler,以在資料集中遇到缺少值時執行以下其中一項作業:
-
捨棄具有缺少值或無效值的列。
-
識別具有缺少值或無效值的列。
-
如果在資料集中發現任何缺少或無效的值,就會擲回錯誤。
您可以驗證具有 timestamp 類型或 string 類型的資料欄上的時間戳記。如果資料行具有string類型,Data Wrangler 會將資料行的類型轉換為timestamp並執行驗證。
您可以使用下列程序驗證資料集中的時間戳記。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇驗證時間戳記。
-
對於時間戳記欄,請選擇時間戳記欄。
-
在 政策中,選擇是否要處理缺少的時間戳記。
-
(選用) 對於 輸出欄,指定輸出資料欄的名稱。
-
如果日期時間欄要針對字串類型進行格式化,請選擇轉換為日期時間。
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
標準化時間序列的長度
如果您將時間序列資料儲存為陣列,則可以將每個時間序列標準化為相同的長度。標準化時間序列陣列的長度可能會讓您更輕鬆地對資料執行分析。
您可以將時間序列標準化,以進行需要固定資料長度的資料轉換。
許多機器學習 (ML) 演算法會要求您在使用時間序列資料之前,先將其平面化。平面化時間序列資料會將時間序列的每個值分隔成資料集中的專屬資料欄。資料集中的資料欄數目無法變更,因此在您將每一陣列平面化為特徵集的期間,需要標準化時間序列的長度。
每個時間序列都會設定為您指定為時間序列集的分位數或百分位數的長度。例如,您可以有三個具有以下長度的序列:
-
3
-
4
-
5
您可以將所有序列設定為有 50 個百分位數長度的序列。
短於您指定長度的時間序列陣列會新增缺少值。以下是將時間序列標準化為長度較長的範例格式:[2, 4, 5, NaN, NaN, NaN]。
您可以使用不同的方法來處理缺少值。如需這些方法的詳細資訊,請參閱處理缺少的時間序列資料。
超過指定長度的時間序列陣列會被截短。
您可以使用下列程序以標準化時間序列的長度。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇標準化長度。
-
對於標準化資料欄的時間序列長度,請選擇一個資料欄。
-
(選用) 對於 輸出欄,指定輸出資料欄的名稱。若您沒有指定名稱,就地完成轉換。
-
如果日期時間欄要針對字串類型進行格式化,請選擇轉換為日期時間。
-
選擇截止分位數並指定分位數以設定序列的長度。
-
選擇平面化輸出,將時間序列的值輸出到單獨的資料欄中。
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
從時間序列資料擷取特徵
如果您對時間序列資料執行分類或迴歸演算法,建議您先從時間序列擷取特徵,然後再執行演算法。擷取特徵可能會提高演算法的效能。
使用以下選項可選擇要從資料中擷取特徵的方式:
-
使用最小子集指定擷取 8 個您知道在下游分析中有用的特徵。當您需要快速執行計算時,則可以使用最小的子集。當您的機器學習 (ML) 演算法過度擬合的風險很高,並且想要提供較少的特徵時,也可以使用它。
-
使用高效率子集指定擷取最多可能的特徵,而無需擷取分析中運算密集型的特徵。
-
使用所有特徵可指定從微調序列擷取的所有特徵。
-
使用手動子集選擇您認為可以很好地解釋資料變化的特徵表。
使用下列程序從時間序列資料擷取特徵。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇擷取特徵。
-
對於擷取此欄特徵,請選擇一欄。
-
(選用) 選取平面化,將功能輸出至單獨的資料欄。
-
對於策略,請選擇要擷取特徵的策略。
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
從時間序列資料使用延遲特徵
對於許多使用案例,預測時間序列未來行為的最佳方式是使用其最新行為。
延遲特徵的最常見用途如下:
-
收集少數過去的數值。例如,對於時間,t + 1,您收集 t、t-1、t-2 和 t-3。
-
收集對應於資料中的季節性行為值。例如,若要預測下午 1:00 在餐廳的佔用率,您可能想要使用自前一天下午 1:00 開始的特徵。使用同一天中午 12:00 或上午 11:00 的特徵可能不像使用前幾天的特徵那樣可預測。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇延遲功能。
-
對於產生此欄的延遲特徵,請選擇一欄。
-
對於時間戳記欄,請選擇包含時間戳記的資料欄。
-
對於延遲,請指定延遲的持續時間。
-
(選用) 使用以下選項之一設定輸出:
-
包含整個延遲視窗
-
平面化輸出
-
不包含歷程記錄的捨棄列
-
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
在時間序列中建立日期時間範圍
您可能有沒有時間戳記的時間序列資料。如果您知道觀察值經過定期取樣,則可以在單獨的資料欄中產生時間序列的時間戳。若要產生時間戳記,請指定開始時間戳記的值和時間戳記的頻率。
例如,您可能擁有以下餐廳顧客人數的時間序列資料。
餐廳顧客人數的時間序列資料
| 顧客人數 |
|---|
| 10 |
| 14 |
| 24 |
| 40 |
| 30 |
| 20 |
如果您知道餐廳在下午 5:00 開放,而且觀察值是每小時進行的,則可以新增與時間序列資料相對應的時間戳記欄。您可以在下表中看到時間戳記資料欄。
餐廳顧客人數的時間序列資料
| 顧客人數 | 時間戳記 |
|---|---|
| 10 | 1:00 PM |
| 14 | 2:00 PM |
| 24 | 3:00 PM |
| 40 | 4:00 PM |
| 30 | 5:00 PM |
| 20 | 6:00 PM |
使用下列程序,以將日期時間範圍新增至您的資料。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇日期時間範圍。
-
對於頻率類型,選擇用來測量時間戳記頻率的單位。
-
對於開始時間戳記,請指定開始時間戳記。
-
對於輸出欄,指定輸出資料欄的名稱。
-
(選用) 使用剩餘欄位設定輸出。
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
在您的時間序列中使用滾動時段
您可以擷取一段時間內的特徵。例如,對於時間、t 和時間時段長度為 3,而對於表示第 t 個時間戳記的列,我們會附加從時間序列 (t-3、t -2 和 t-1) 擷取的特徵 。如需擷取特徵的資訊,請參閱從時間序列資料擷取特徵。
您可以透過下列程序擷取一段時間內的特徵。
-
開啟 Data Wrangler 資料流程。
-
如果您尚未匯入資料集,請在資匯入資料索引標籤下匯入資料集。
-
在資料流程中的資料類型下,選擇 +,然後選取新增轉換。
-
選擇新增步驟。
-
選擇滾動時段特徵。
-
對於產生此欄的滾動時段特徵,請選擇一欄。
-
對於時間戳記欄,請選擇包含時間戳記的資料欄。
-
(選用) 對於 輸出資料欄,請指定輸出資料欄的名稱。
-
對於視窗大小,請指定視窗大小。
-
對於策略,請選擇擷取策略。
-
選擇預覽以產生轉換的預覽。
-
選擇新增,將轉換作業新增至 Data Wrangler 資料流程。
特徵化日期時間
使用特徵化日期/時間來建立代表日期時間欄位的向量內嵌。若要使用此轉換,您的日期時間資料格式必須為下列其中一種:
-
描述日期時間的字串:例如:
"January 1st, 2020, 12:44pm"。 -
Unix 時間戳記:Unix 時間戳記描述了自 1970 年 1 月 1 日開始的秒數、毫秒數、微秒數或納秒數。
您可以選擇推論日期時間格式並提供日期時間格式。如果您提供日期時間格式,則必須使用 Python 文件
-
最手動和計算速度最快的選項是指定日期時間格式,並針對推論日期時間格式選取否。
-
若要減少人工,您可以選擇推論日期時間格式,而不要指定日期時間格式。它也是一個快速計算的操作;然而,會假定在輸入欄中遇到的第一個日期時間格式為整欄的格式。如果欄中有其他格式,則這些值在最終輸出中為 NaN。推論日期時間格式可以給你未剖析的字串。
-
如果您沒有指定格式,並針對推論日期時間格式選取否,就會得到最可靠的結果。所有有效的日期時間字串都會被剖析。但是,此操作可能會比此清單中的前兩個選項慢一個量級。
使用此轉換時,您可以指定包含上述所列一種格式的日期時間資料的輸入資料欄。轉換會建立一個名為輸出資料欄名稱的輸出欄。輸出欄的格式取決於您使用下列內容所定的組態:
-
向量:將單一欄輸出為向量。
-
欄:為每個特徵建立新資料欄。例如,如果輸出包含年、月和日,則會針對年、月和日建立三個單獨的資料欄。
此外,您必須選擇內嵌項目模式。對於線性模型和深度網路,我們建議選擇循環。對於樹狀演算法,我們建議選擇序數。
格式字串
格式字串轉換包含標準字串格式化作業。例如,您可以使用這些作業來移除特殊字元、標準化字串長度,以及更新字串大小寫。
此特徵群組包含下列轉換。所有轉換都會傳回輸入欄中字串的副本,並將結果新增至新的輸出欄。
| 名稱 | 函式 |
|---|---|
| 左填充 |
以特定填充字元向左填充至特定寬度的字串。如果字串長於寬度,則傳回值將縮短為寬度字元。 |
| 右填充 |
以特定填充字元向右填充至特定寬度的字串。如果字串長於寬度,則傳回值將縮短為寬度字元。 |
| 置中 (於任一側填充) |
以特定填充字元置中填充 (在字串兩側加入填充) 至特定寬度的字串。如果字串長於寬度,則傳回值將縮短為寬度字元。 |
| 以零字首 |
以零向左填充一個數字字串,直到特定的寬度。如果字串長於寬度,則傳回值將縮短為寬度字元。 |
| 去除左右 |
傳回移除字首和後加字元的字串副本。 |
| 從左去除字元 |
傳回移除字首字元的字串副本。 |
| 從右去除字元 |
傳回移除後加字元的字串副本。 |
| 小寫 |
將文字中的所有字母轉換為小寫。 |
| 大寫 |
將文字中的所有字母轉換為大寫。 |
| 首字母大寫 |
將每個句子的第一個字母大寫。 |
| 大小寫交換 | 將指定字串的所有大寫字元轉換為小寫字元,並將所有小寫字元轉換為大寫字元,然後加以傳回。 |
| 新增字首或字尾 |
新增字串欄的字首和字尾。您必須至少指定一個字首和字尾。 |
| 移除符號 |
從字串中刪除指定的符號。所有已列出的字元都會被移除。預設為空格。 |
處理極端值
機器學習模型對特徵值的分佈和範圍很敏感。極端值或稀有值可能會對模型準確性產生負面影響,並導致訓練時間延長。使用此特徵群組可偵測並更新您的資料集中的極端值。
當您定義處理極端值轉換步驟時,將根據 Data Wrangler 中的可用資料產生用於偵測極端值的統計資料。執行 Data Wrangler 工作時,會使用這些相同的統計資料。
使用下列章節以進一步了解此群組所包含的轉換。您可以指定輸出名稱,每個轉換都會產生含有結果資料的輸出欄。
強大的標準偏差數值極端值
此轉換使用對極端值強大的統計資料,偵測並修正數值特徵中的極端值。
您必須為用於計算極端值的統計資料定義上分位數和下分位數。您還必須指定標準偏差的數值,其值必須與平均值不同,才能被視為極端值。例如,如果您指定 3 為標準偏差,則值必須與平均值的標準偏差必須超過 3,才能被視為極端值。
修正方法是偵測到極端值時用來處理的方法。您可以選擇下列項目:
-
剪裁:使用此選項可將極端值裁剪為對應的極端值偵測界限。
-
移除:使用此選項可從資料框中移除具有極端值的列。
-
無效:使用此選項可用無效值取代極端值。
標準偏差數值極端值
此轉換會使用平均值和標準偏差來偵測並修復數值特徵中的極端值。
您可以指定標準偏差的數目,值必須與平均值不同,才能被視為極端值。例如,如果您指定 3 為標準偏差,則值必須與平均值的標準偏差必須超過 3,才能被視為極端值。
修正方法是偵測到極端值時用來處理的方法。您可以選擇下列項目:
-
剪裁:使用此選項可將極端值裁剪為對應的極端值偵測界限。
-
移除:使用此選項可從資料框中移除具有極端值的列。
-
無效:使用此選項可用無效值取代極端值。
分位數值極端值
使用此轉換可以使用分位數偵測和修復數值特徵中的極端值。您可以定義上分位數和下分位數。高於上分位數或低於下分位數的所有值都被視為極端值。
修正方法是偵測到極端值時用來處理的方法。您可以選擇下列項目:
-
剪裁:使用此選項可將極端值裁剪為對應的極端值偵測界限。
-
移除:使用此選項可從資料框中移除具有極端值的列。
-
無效:使用此選項可用無效值取代極端值。
最小-最大數值極端值
此轉換會使用上限和下限閾值來偵測並修復數值特徵中的極端值。如果您知道分開極端值的閾值,請使用此方法。
您可以指定閾值上限和閾值下限,如果值分別高於或低於這些閾值,則將其視為極端值。
修正方法是偵測到極端值時用來處理的方法。您可以選擇下列項目:
-
剪裁:使用此選項可將極端值裁剪為對應的極端值偵測界限。
-
移除:使用此選項可從資料框中移除具有極端值的列。
-
無效:使用此選項可用無效值取代極端值。
取代稀有
當您使用取代稀有轉換時,您可以指定閾值,Data Wrangler 會尋找符合該閾值的所有值,並以您指定的字串取代這些值。例如,您可能想要使用此轉換,將資料欄中的所有極端值分類為 “其他” 類別。
-
取代字串:用來取代極端值的字串。
-
絕對閾值:如果執行個體數目小於或等於此絕對閾值,則類別為稀有。
-
分數閾值:如果執行個體數目小於或等於此分數閾值乘以列數,則該類別為稀有。
-
最大常見類別:操作後保留的非稀有上限類別。如果閾值沒有篩選出足夠的類別,那些具有最多外觀數目的類別將被分類為非稀有。如果設定為 0 (預設值),則類別數量沒有硬性限制。
處理缺少值
缺少值是機器學習資料集中常見的情況。在某些情況下,適用於以計算值推算遺失資料,例如平均值或已分類的常見值。您可以使用處理缺少值轉換群組來處理缺少值。此群組包含下列轉換。
填充缺少
使用填充缺少轉換指令,以您定義的填充值取代缺少值。
推算缺少
使用推算缺少轉換來建立包含導入值的新資料欄,其中會在輸入分類和數值資料中找到缺少值。組態取決於您的資料類型。
對於數值資料,請選擇推算策略,也就是用來決定要推算新值的策略。您可以選擇推算在於您的資料集中的平均值或中間值。Data Wrangler 會使用它所計算的值來導入缺少值。
對於分類資料,Data Wrangler 會使用資料欄中最常用的值來算出缺少值。若要推算自訂字串,請改用填充缺少轉換。
新增缺少的指標
使用新增缺少的指標轉換以建立新的指標欄,其中如果一列包含一個值,則包含布林值 "false",如果一列包含缺少值,則為 "true"。
捨棄缺少
您可以使用捨棄缺少選項,從輸入資料欄捨棄包含缺少值的資料列。
管理欄
您可以使用下列轉換來快速更新和管理資料集中的資料欄:
| 名稱 | 函式 |
|---|---|
| 捨棄資料欄 | 刪除資料欄。 |
| 複製資料欄 | 複製資料欄。 |
| 重新命名資料欄 | 重新命名資料欄。 |
| 移動資料欄 |
在資料集中移動資料欄的位置。選擇將資料欄移至資料集的開頭或結尾、參考資料欄之前或之後,或移至特定索引。 |
管理資料列
使用此轉換群組可快速對資料列執行排序和隨機顯示操作。此群組包含下列轉換。
-
排序:按指定資料欄對整個資料框進行排序。選取此選項遞增排列旁邊的核取方塊;否則,取消選取核取方塊,排序會使用遞減排列。
-
隨機顯示:隨機顯示資料集中的所有資料列。
管理向量
使用此轉換群組可合併或平面化向量欄。此群組包含下列轉換。
-
組合:使用此轉換可將 Spark 向量和數值資料合併為單一欄。例如,您可以合併三欄:兩欄包含數值資料,另一欄包含向量。在輸入資料欄中新增要組合的所有資料欄,並為組合資料指定輸出資料欄名稱。
-
平面化:使用此轉換可將包含向量資料的單一資料欄平面化。輸入資料欄必須包含 PySpark 向量或類似陣列的物件。您可以透過指定偵測輸出數目的方法來控制建立的欄數。例如,如果您選取第一個向量的長度,則在資料欄中找到的第一個有效向量或陣列中的元素數目會決定建立的輸出欄數。所有其他具有太多項目的輸入向量都會被截斷。項目太少的輸入會填入 NaNs。
您也可以指定輸出字首作為每個輸出資料欄的字首。
處理數值
使用處理數值特徵群組來處理數值資料。此組中的每個純量是使用 Spark 資料庫定義的。支援下列純量:
-
標準純量:透過從每個值減去平均值並擴屋至單位變異數來標準化輸入欄。若要進一步了解,請參閱StandardScaler 的 Spark 文件。
-
強大的純量:使用對極端值強大的統計資量來擴展輸入欄。如需進一步了解,請參閱 RobustScaler
的 Spark 文件。 -
純量上下限:透過將每個特徵擴展到指定範圍來轉換輸入欄。如需進一步了解,請參閱 MinMaxScaler
的 Spark 文件。 -
絕對純量上限:透過將每個值除以最大絕對值來擴展輸入欄。如需進一步了解,請參閱 MaxAbsScaler
的 Spark 文件。
抽樣
匯入資料之後,您可以使用取樣轉換器以取得一或多個樣本。當您使用取樣轉換器時,Data Wrangler 會對原始資料集進行取樣。
您可以選擇下列其中一種取樣方法:
-
限制:從第一列開始,直到您指定的限制為止,對資料集進行抽樣。
-
隨機化:取得您指定大小的隨機範例。
-
分層:採取分層隨機範例。
您可以分層隨機範例,以確保其代表資料集的原始分佈。
您可能正在為多個使用案例執行資料準備。對於每個使用案例,您都可以取得不同的範例並套用不同的轉換組。
下列程序描述建立隨機範例的程序。
從您的資料中獲取隨機範例。
-
選擇已匯入資料集右側的 +。您的資料集名稱位於 + 下方。
-
選擇新增轉換。
-
選擇抽樣。
-
對於取樣方法,請選擇取樣方法。
-
對於大約範例大小,請選擇範例中所需的大約觀察次數。
-
(選用) 為隨機種子指定一個整數,以建立可再生的範例。
下列程序描述建立分層範例的程序。
從您的資料中獲取分層範例。
-
選擇已匯入資料集右側的 +。您的資料集名稱位於 + 下方。
-
選擇新增轉換。
-
選擇抽樣。
-
對於取樣方法,請選擇取樣方法。
-
對於大約範例大小,請選擇範例中所需的大約觀察次數。
-
對於分層欄,指定要分層的欄名稱。
-
(選用) 為隨機種子指定一個整數,以建立可再生的範例。
搜尋與編輯
您可以使用此區段來搜尋和編輯字串中的特定模式。例如,您可以尋找和更新句子或文件中的字串、以分隔符號分隔字串,以及尋找特定字串的出現次數。
搜尋和編輯支援下列轉換。所有轉換都會傳回輸入欄中字串的副本,並將結果新增至新的輸出欄。
| 名稱 | 函式 |
|---|---|
|
尋找子字串 |
傳回您搜尋子字串第一次出現的索引。您可以分別在開始和結束位置開始和結束搜尋。 |
|
尋找子字串 (從右側) |
傳回您搜尋的子字串上次出現的索引。您可以分別在開始和結束位置開始和結束搜尋。 |
|
相符字首 |
如果字串包含一個特定的模式,則傳回一個布爾值。模式可以是字元序列或規則表達式。或者,您可以將模式區分大小寫。 |
|
尋找所有出現次數 |
傳回具有特定模式的所有出現次數陣列。模式可以是字元序列或規則表達式。 |
|
使用 regex 擷取 |
傳回一個與特定 Regex 模式匹配的字串。 |
|
在分隔符號之間擷取 |
傳回在左分隔符和右分隔符之間找到的所有字元的字串。 |
|
從位置擷取 |
傳回一個字串,從輸入字串中的開始位置開始,該字串包含直到開始位置的所有字元加長度。 |
|
尋找和取代子字串 |
傳回由取代字串取代特定模式 (正規表示式) 的全部相符字串。 |
|
取代分隔符號之間 |
傳回一個字串,其中包含由取代字串所取代的左分隔符號的第一個外觀和右分隔符號的最後一個外觀之間的子字串。若無相符項目,則不會取代任何項目。 |
|
從位置取代 |
傳回一個字串,其中包含由取代字串所取代的開始位置和開始位置加長度之間的子字串。如果開始位置加長度大於取代字串的長度,則輸出包含……。 |
|
轉換 regex 至缺失 |
若無效,則將字串轉換為 |
|
按分隔符號分割字串 |
傳回來自輸入字串的字串陣列,由分隔符號分隔,具有分隔數量上限 (選用)。分隔符號預設為空格。 |
分隔資料
使用分隔資料轉換,將資料集分隔為兩個或三個資料集。例如,您可以將資料集分割成用於訓練模型的資料集,以及用來測試模型的資料集。您可以決定進入每個分割的資料集比例。例如,如果您要將一個資料集分割成兩個資料集,則訓練資料集可以有 80% 的資料,而測試資料集則有 20%。
將資料分割為三個資料集,讓您能夠建立訓練、驗證和測試資料集。您可以透過捨棄目標資料欄來查看模型在測試資料集上的效能。
您的使用案例會決定每個資料集取得的原始資料集數量,以及您用來分割資料的方法。例如,您可能想要使用分層分割,以確保目標欄中的觀測值在資料集之間的分佈相同。您可以使用下列分割轉換:
-
隨機分割 – 每個分割都是原始資料集的隨機、非重疊範例。對於較大的資料集,使用隨機分割可能在計算上很昂貴,而且花費的時間比排序分割還要長。
-
排序分割 – 根據觀察值的順序分割資料集。例如,對於 80/20 訓練測試分割,構成資料集 80% 的第一個觀察值將轉到訓練資料集。最後 20% 的觀察值進入測試資料集。排序分割可以有效地保持分割之間資料的現有順序。
-
分層分割 – 分割資料集,以確保輸入資料欄中的觀察數目具有比例代表性。對於具有觀察值 1,1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3 的輸入欄,資料欄上的 80/20 分割代表大約 80% 的 1、80% 的 2 和 80% 的 3 進入訓練集。每種觀察類型的約 20% 進入測試集。
-
按鍵分割 – 避免在大於一個的分割中發生具有相同索引鍵的資料。例如,如果您有一個包含 'customer_id' 欄的資料集,並且您將其用作索引鍵,則不會在超過一個的分割中存在任何客戶 ID。
分割資料之後,您可以對每個資料集套用其他轉換。對於大多數使用案例,它們不是必要的。
Data Wrangler 計算分割的比例以實現性能。您可以選擇錯誤閾值來設定分割的準確度。較低的錯誤閾值會更準確地反映您為分割指定的比例。如果您設定較高的錯誤閾值,您可以獲得較佳的效能,但準確度會降低。
若要完美分割資料,請將錯誤閾值設定為 0。您可以指定介於 0 到 1 之間的閾值,以獲得較佳效能。如果指定大於 1 的值,Data Wrangler 會將該值解譯為 1。
如果您的資料集中有 10000 個資料列,而且您指定了一個具備 0.001 錯誤值的 80/20 分割,您會得到接近下列其中一個結果的觀察值:
-
在訓練集中為 8010 觀察值和在測試集中則為 1990
-
在訓練集中為 7990 觀察值和在測試集中則為 2010
在前面的例子中的測試集觀察數目是介於 8010 和 7990 之間。
預設情況下,Data Wrangler 使用隨機種子來使分割可重現。您可以為種子指定不同的值,以建立不同的可重現的分割。
將值剖析為類型
使用此轉換可將資料欄轉換為新類型。支援的 Data Wrangler 資料類型為:
-
Long
-
Float
-
Boolean
-
日期格式為 DD-MM-yyyy,分別代表日、月和年。
-
字串
驗證字串
使用驗證字串轉換建立新資料欄,指出符合指定條件的文字資料列。例如,您可以使用驗證字串轉換來驗證字串只包含小寫字元。驗證字串支援下列轉換。
下列轉換包含在此轉換群組中。如果轉換輸出布林值,則 True 以 1 表示,而 False 以 0 表示。
| 名稱 | 函式 |
|---|---|
|
字串長度 |
如果字串長度等於指定的長度,則傳回 |
|
開頭為 |
如果字串以特定字首起始,則返回 |
|
結尾為 |
如果字串長度等於指定的長度,則傳回 |
|
為英數字元 |
如果一個字串只包含數字和字母,則傳回 |
|
為字母 |
如果一個字串只包含字母,則傳回 |
|
為數字 |
如果一個字串只包含數字,則傳回 |
|
為空間 |
如果一個字串只包含數字和字母,則傳回 |
|
為標題 |
如果一個字串包含任何空格,則傳回 |
|
為小寫 |
如果一個字串只包含小寫字母,則傳回 |
|
為大寫 |
如果一個字串只包含大寫字母,則傳回 |
|
為數值 |
如果一個字串只包含數字,則傳回 |
|
為小數 |
如果一個字串只包含小數,則傳回 |
將 JSON 資料解除巢狀化
如果您有 .csv 檔案,資料集中的值可能是 JSON 字串。同樣地,可能會在 Parquet 檔案或 JSON 文件的資料欄中有巢狀資料。
使用平面化結構運算子,將第一層索引鍵分隔為單獨的資料欄。第一層索引鍵是未嵌套在值中的索引鍵。
例如,您可能有一個資料集,其中有一個人員資料欄,其中包含儲存為 JSON 字串的每個人人口統計資訊。JSON 字串結構可能如下。
"{"seq": 1,"name": {"first": "Nathaniel","last": "Ferguson"},"age": 59,"city": "Posbotno","state": "WV"}"
平面化結構運算子會將下列第一層索引鍵轉換為資料集中的其他資料欄:
-
seq
-
name
-
age
-
城市
-
state
Data Wrangler 把索引鍵的值作為資料欄下的值。下列顯示 JSON 的資料欄名稱與值。
seq, name, age, city, state 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV
對於包含 JSON 的資料集中的每個值,平面化結構運算子會為第一層級索引鍵建立資料欄。若要為巢狀索引鍵建立欄,請再次呼叫運算子。在前述範例中,呼叫運算子會建立資料欄:
-
name_first
-
name_last
下列範例顯示再次呼叫操作所產生的資料集。
seq, name, age, city, state, name_first, name_last 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV, Nathaniel, Ferguson
選擇要平面化的索引鍵,以指定要擷取為單獨欄的第一層級索引鍵。如果您未指定任何索引鍵,Data Wrangler 預設會擷取所有索引鍵。
爆炸陣列
使用 爆炸陣列將陣列的值展開為單獨的輸出資料列。例如,該作業可以獲取陣列 [[1, 2, 3,], [4, 5, 6], [7, 8, 9]] 中的每個值,並建立具有以下列的新資料欄:
[1, 2, 3] [4, 5, 6] [7, 8, 9]
Data Wrangler 將新資料欄命名為 input_column_name_flatten。
您可以多次呼叫 Explode 陣列作業,以將陣列的巢狀值取至不同的輸出資料欄。下列範例顯示在具有巢狀陣列的資料集上多次呼叫作業的結果。
將嵌套陣列的值置入單獨的資料欄中
| id | 陣列 | id | array_items | id | array_items_items |
|---|---|---|---|---|---|
| 1 | [ [cat, dog], [bat, frog] ] | 1 | [貓, 狗] | 1 | cat |
| 2 |
[[rose, petunia], [lily, daisy]] |
1 | [蝙蝠, 青蛙] | 1 | 狗 |
| 2 | [玫瑰, 矮牽牛] | 1 | bat | ||
| 2 | [百合, 雛菊] | 1 | 青蛙 | ||
| 2 | 2 | 玫瑰 | |||
| 2 | 2 | 矮牽牛 | |||
| 2 | 2 | 百合 | |||
| 2 | 2 | 雛菊 |
轉換影像資料
使用 Data Wrangler 匯入和轉換您用於機器學習 (ML) 管道的影像。準備好影像資料之後,您可以將其從 Data Wrangler 流程匯出至機器學習 (ML) 管道。
您可以使用此處提供的資訊熟悉 Data Wrangler 中影像資料的匯入和轉換。Data Wrangler 使用 OpenCV 導入影像。如需有關支援的影像格式詳細資訊,請參閱影像檔案讀取和寫入
熟悉轉換影像資料的概念之後,請參閱下列教學課程使用 Amazon SageMaker Data Wrangler 預備影像資料
以下產業和使用案例是將機器學習應用於已轉換影像資料時可能會很有用的範例:
-
製造 – 從組裝線識別物品中的瑕疵
-
食物 – 識別變質或腐爛的食物
-
藥物 – 識別組織中的病變
當您在 Data Wrangler 中使用影像資料時,會經過下列程序:
-
匯入 – 選擇 Amazon S3 儲存貯體中包含影像的目錄以選取影像。
-
轉換 – 使用內建轉換為您的機器學習管道預備影像。
-
匯出 – 將已轉換的影像匯出至可從管道存取的位置。
請使用下列程序來匯入您的影像資料。
若要匯入影像資料
-
導覽至建立連線頁面。
-
選擇 Amazon S3。
-
指定包含影像資料的 Amazon S3 檔案路徑。
-
對於檔案類型,選擇影像。
-
(選用) 選擇匯入巢狀目錄以從多個 Amazon S3 路徑匯入影像。
-
選擇匯入。
Data Wrangler 使用開放源程式碼 imgaug
-
ResizeImage
-
EnhanceImage
-
CorruptImage
-
SplitImage
-
DropCorruptedImages
-
DropImageDuplicates
-
Brightness
-
ColorChannels
-
Grayscale
-
Rotate
使用下列程序,無須撰寫程式碼即可轉換映像。
在不撰寫程式碼的情況下轉換映像
-
在 Data Wrangler 流程中,選擇代表您匯入映像節點旁邊的 +。
-
選擇新增轉換。
-
選擇新增步驟。
-
選擇轉換並加以設定。
-
選擇預覽。
-
選擇新增。
除了使用 Data Wrangler 提供的轉換之外,您也可以使用自己的自訂程式碼片段。如需使用自訂程式碼片段的詳細資訊,請參閱自訂轉換。您可以在程式碼片段中匯入 OpenCV 和 imgaug 程式庫,並使用與它們相關聯的轉換。以下是偵測映像邊緣的程式碼片段範例。
# A table with your image data is stored in the `df` variable import cv2 import numpy as np from pyspark.sql.functions import column from sagemaker_dataprep.compute.operators.transforms.image.constants import DEFAULT_IMAGE_COLUMN, IMAGE_COLUMN_TYPE from sagemaker_dataprep.compute.operators.transforms.image.decorators import BasicImageOperationDecorator, PandasUDFOperationDecorator @BasicImageOperationDecorator def my_transform(image: np.ndarray) -> np.ndarray: # To use the code snippet on your image data, modify the following lines within the function HYST_THRLD_1, HYST_THRLD_2 = 100, 200 edges = cv2.Canny(image,HYST_THRLD_1,HYST_THRLD_2) return edges @PandasUDFOperationDecorator(IMAGE_COLUMN_TYPE) def custom_image_udf(image_row): return my_transform(image_row) df = df.withColumn(DEFAULT_IMAGE_COLUMN, custom_image_udf(column(DEFAULT_IMAGE_COLUMN)))
在 Data Wrangler 流程中套用轉換時,Data Wrangler 只會將它們套用至資料集中的映像範例。為了最佳化您使用應用程式的體驗,Data Wrangler 不會將轉換套用於您的所有映像。
若要將轉換套用至所有映像,請將 Data Wrangler 流程匯出到 Amazon S3 位置。您可以使用已在訓練或推論管道中匯出的映像。使用目的地節點或 Jupyter 筆記本匯出資料。您可以存取任一種從 Data Wrangler 流程匯出資料的方法。如需這些方法的用法詳細資訊,請參閱匯出至 Amazon S3。
篩選資料
使用 Data Wrangler 篩選資料欄中的資料。當您篩選資料欄中的資料時,請指定下列欄位:
-
欄名稱 – 您用來篩選資料的資料欄名稱。
-
條件 – 您要套用至資料欄中值的篩選類型。
-
值 – 您要套用篩選條件的資料欄中的值或類別。
您可以依照下列條件篩選:
-
= – 傳回與您指定的值或類別相符的值。
-
!= – 傳回與您指定的值或類別不相符的值。
-
>= – 對於長或浮動資料,篩選大於或等於您指定值的值。
-
<= – 對於長或浮動資料,篩選小於或等於您指定值的值。
-
> – 對於長或浮動資料,篩選大於您指定值的值。
-
< – 對於長或浮動資料,篩選小於您指定值的值。
對於具有類別 male 和 female 的資料欄,您可以過濾掉所有 male 值。您也可以篩選所有 female 值。因為資料欄中只有 male 和 female 值,所以篩選條件會傳回只有 female 值的資料欄。
您也可以新增多個篩選條件。篩選條件可套用至多個資料欄或同一個資料欄。例如,如果您要建立的資料欄只有特定範圍內的值,您可以新增兩個不同的篩選條件。一個篩選條件指定資料欄的值必須大於您提供的值。另一個篩選條件指定資料欄的值必須小於您提供的值。
使用下列程序,將篩選條件轉換新增至您的資料。
若要篩選資料
-
在 Data Wrangler 流程中,選擇包含您要篩選資料節點旁邊的 +。
-
選擇新增轉換。
-
選擇新增步驟。
-
選擇篩選資料。
-
為下列欄位:
-
資料欄名稱 – 您要篩選的資料欄。
-
條件 – 篩選條件。
-
值 – 您要套用篩選條件的資料欄中的值或類別。
-
-
(選用) 選擇您建立篩選條件後的 +。
-
設定篩選條件。
-
選擇預覽。
-
選擇新增。
Amazon Personalize 的地圖資料欄
Data Wrangler 與 Amazon Personalize 整合,這是一種全受管的機器學習服務,可產生項目建議和使用者區段。您可以使用 Amazon Personalize 的地圖欄轉換,將您的資料轉換為 Amazon Personalize 可解釋的格式。如需有關 Amazon Personalize 特定轉換的詳細資訊,請參閱使用 Amazon SageMaker Data Wrangler 匯入資料。如需有關 Amazon Personalize 的更多資訊,請參閱什麼是 Amazon Personalize?
