本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon SageMaker Debugger 架構
這個主題會逐步引導您了解 Amazon SageMaker Debugger 工作流程的高階概觀。
Debugger 支援效能最佳化的分析功能,識別諸如系統瓶頸和使用量過低等運算問題,並協助大規模最佳化硬體資源使用率。
Debugger 模型最佳化的偵錯功能涉及分析可能出現的非收斂訓練問題,同時使用諸如梯度下降及其變化等最佳化演算法,以最小化損耗函式。
下圖顯示 SageMaker Debugger 的架構。具有粗邊界的區塊即為 Debugger 管理來分析訓練任務的區塊。
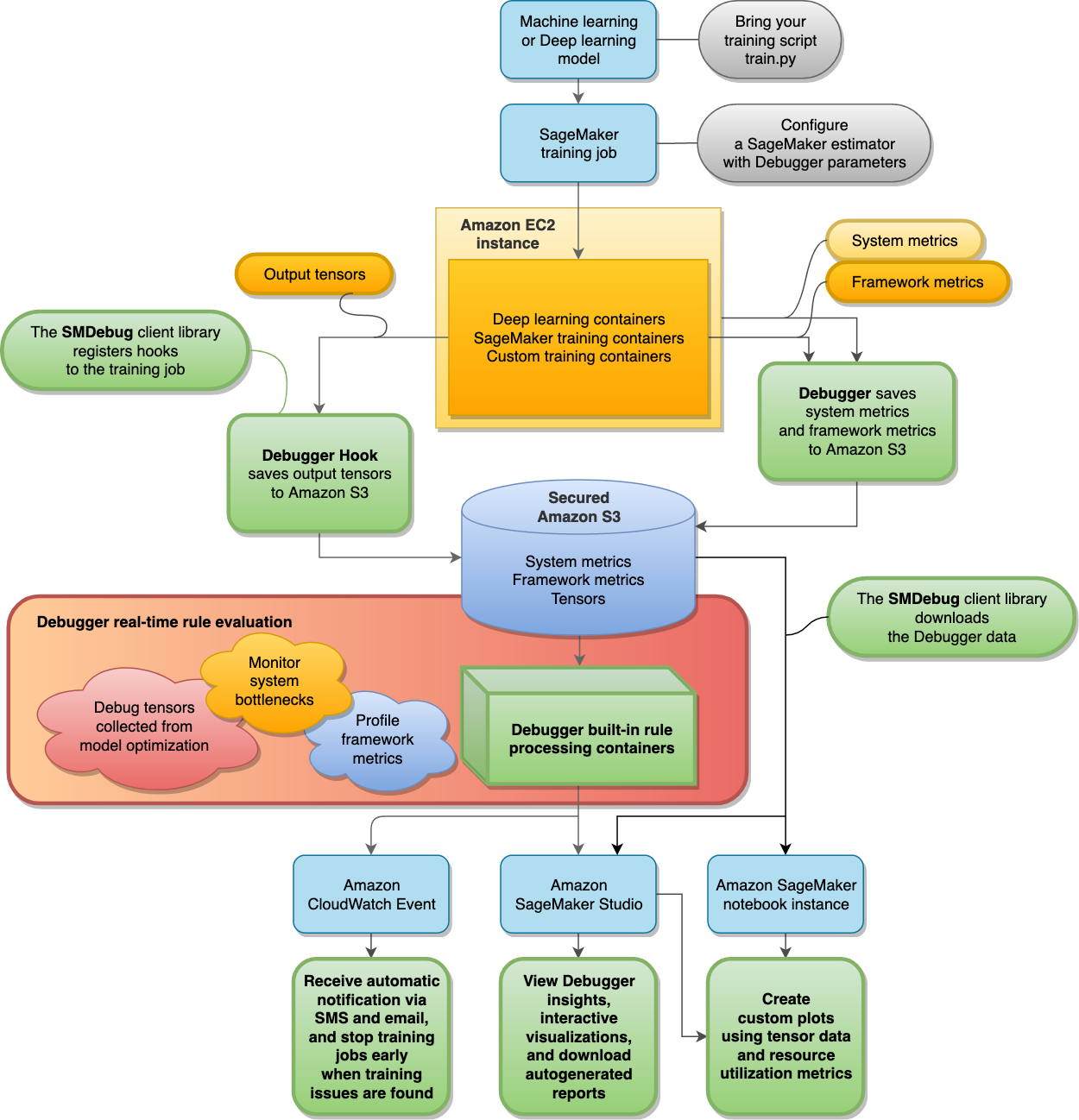
Debugger 會將訓練任務的下列資料存放在安全的 Amazon S3 儲存貯體中:
-
輸出張量 — 訓練機器學習 (ML) 模型時,在向前和向後傳遞期間持續更新純量和模型參數的集合。輸出張量包含純量值 (準確度和損失) 和矩陣 (權重、梯度、輸入層和輸出層)。
注意
根據預設,Debugger 會監控和偵錯 SageMaker 訓練任務,而不會在 SageMaker AI 估算器中設定任何 Debugger 特定參數。Debugger 每 500 毫秒收集一次系統指標,並且每 500 個步驟收集一次基本輸出張量 (諸如損失和準確度等純量輸出)。它也執行
ProfilerReport規則來分析系統指標,並彙總 Studio Debugger 深入分析儀表板和分析報告。Debugger 會將輸出資料儲存在安全的 Amazon S3 儲存貯體。
Debugger 內建規則在處理容器上執行,這些容器旨在通過處理 S3 儲存貯體中收集的訓練資料來評估機器學習模型 (請參閱處理資料和評估模型)。Debugger 會完全管理內建規則。您也可以建立自己的自訂模型規則,以監看您想要監控的任何問題。
