本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
訓練模型
在此步驟中,您可以選擇訓練演算法並執行模型的訓練任務。Amazon SageMaker Python SDK
選擇訓練演算法
若要為資料集選擇正確的演算法,您通常需要評估不同的模型,以找出最適合您資料的模型。為了簡單起見,本教學課程中使用 SageMaker AI 搭配 Amazon SageMaker AI 的 XGBoost 演算法 內建演算法,無需預先評估模型。
提示
如果您希望 SageMaker AI 為您的表格式資料集尋找適當的模型,請使用 Amazon SageMaker Autopilot 自動化機器學習解決方案。如需詳細資訊,請參閱SageMaker Autopilot。
建立和執行訓練任務
找出要使用的模型後,開始建構 SageMaker AI 估算器以進行訓練。本教學課程使用 SageMaker AI 一般估算器的 XGBoost 內建演算法。
執行模型訓練任務
-
匯入 Amazon SageMaker Python SDK
,並從您目前的 SageMaker AI 工作階段擷取基本資訊開始。 import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))其會傳回下列資訊:
-
region– SageMaker AI 筆記本執行個體執行所在的目前 AWS 區域。 -
role— 筆記本執行個體使用的 IAM 角色。
注意
透過執行
sagemaker.__version__檢查 SageMaker Python SDK 版本。本教學課程是基於sagemaker>=2.20。如果 SDK 已過期,請執行下列命令來安裝最新版本:! pip install -qU sagemaker如果您在現有的 SageMaker Studio 或筆記本執行個體中執行此安裝,則需要手動重新整理核心以完成套用版本更新。
-
-
使用
sagemaker.estimator.Estimator類別建立一個 XGBoost 估算器。在下列範例程式碼中,XGBoost 估算器命名為xgb_model。from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )若要建構 SageMaker AI 估算器,請指定下列參數:
-
image_uri— 指定訓練容器映像 URI。在此範例中,使用 指定 SageMaker AI XGBoost 訓練容器 URIsagemaker.image_uris.retrieve。 -
role– SageMaker AI 用來代表您執行任務的 AWS Identity and Access Management (IAM) 角色 (例如,讀取訓練結果、從 Amazon S3 呼叫模型成品,以及將訓練結果寫入 Amazon S3)。 -
instance_count和instance_type— 模型訓練使用的 Amazon EC2 機器學習 (ML) 運算執行個體類型和數量。在本訓練練習中,您將使用具有 4 個 CPU、16 GB 記憶體、Amazon Elastic Block Store (Amazon EBS) 儲存和高網路效能的單一ml.m4.xlarge執行個體。如需 EC2 運算執行個體類型的更多相關資訊,請參閱 Amazon EC2 運算執行個體類型。如需帳單的更多相關資訊,請參閱 Amazon SageMaker 定價 。 -
volume_size— 要連接到訓練執行個體之 EBS 儲存磁碟區的大小 (以 GB 為單位)。如果您使用File模式 (File是預設模式),這必須大到足以存放訓練資料。如果未指定此參數,預設值將為 30。 -
output_path– SageMaker AI 存放模型成品和訓練結果的 S3 儲存貯體路徑。 -
sagemaker_session– 管理與 SageMaker API 操作和訓練任務使用之其他服務互動 AWS 的工作階段物件。 -
rules— 指定 SageMaker Debugger 內建規則的清單。在此範例中,create_xgboost_report()規則會建立 XGBoost 報告,提供訓練進度和結果的深入資訊,並且ProfilerReport()規則會建立有關 EC2 運算資源使用率的報告。如需詳細資訊,請參閱XGBoost 的 SageMaker Debugger 互動式報告。
提示
如果您想要對大型深度學習模型執行分散式訓練,例如卷積神經網路 (CNN) 和自然語言處理 (NLP) 模型,請使用 SageMaker AI 分散式進行資料平行處理或模型平行處理。如需詳細資訊,請參閱Amazon SageMaker AI 中的分散式訓練。
-
-
呼叫估算器的
set_hyperparameters方法,來設定 XGBoost 演算法的超參數。有關 XGBoost 超參數的完整清單,請參閱XGBoost 超參數。xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )提示
您也可以使用 SageMaker AI 超參數最佳化功能來調校超參數。如需詳細資訊,請參閱使用 SageMaker AI 自動調校模型。
-
使用
TrainingInput類別來設定用於訓練的資料輸入流程。以下範例程式碼來顯示如何設定TrainingInput物件來使用您上傳到 Amazon S3 的訓練和驗證資料集,請參閱將資料分割為訓練、測試和驗證資料集。部分。from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
若要開始模型訓練,請使用訓練和驗證資料集呼叫估算器的
fit方法。透過設定wait=True,fit方法會顯示進度日誌並等待訓練完成,再傳回結果。xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)如需模型訓練的更多相關資訊,請參閱使用 Amazon SageMaker 訓練模型。本教學課程訓練工作最多可能需要 10 分鐘的時間。
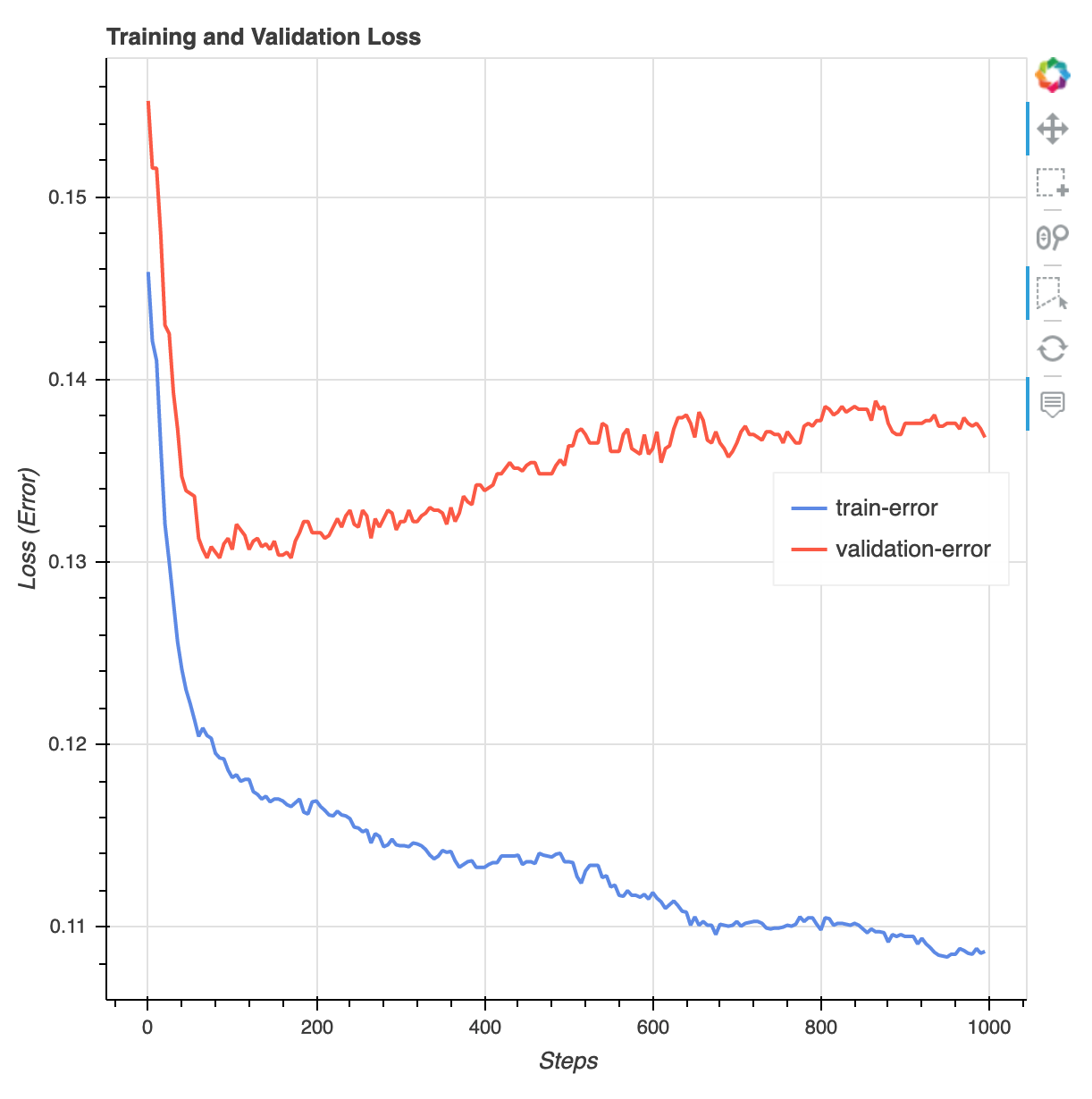
訓練工作完成後,您可以下載 XGBoost 訓練報告和 SageMaker Debugger 所產生的效能分析報告。XGBoost 訓練報告可讓您深入瞭解訓練進度和結果,例如與迭代、功能重要性、混淆矩陣、準確度曲線以及其他訓練統計結果相關的損失函式。例如,您可以從 XGBoost 訓練報告中找到以下損失曲線,清楚地表明存在過度擬合的問題。
執行下列程式碼以指定產生 Debugger 訓練報告的 S3 儲存貯體 URI,並檢查報告是否存在。
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursive將 Debugger XGBoost 訓練和效能分析報告下載到目前的工作區:
! aws s3 cp {rule_output_path} ./ --recursive執行下列 IPython 指令碼以取得 XGBoost 訓練報告的檔案連結:
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))下列 IPython 指令碼會傳回 Debugger 分析報告的檔案連結,其中顯示 EC2 執行個體資源使用率、系統瓶頸偵測結果和 python 作業剖析結果的摘要和詳細資訊:
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))提示
如果 HTML 報表未在 JupyterLab 檢視中轉譯繪圖,您必須選擇報表頂端的信任 HTML。
若要識別訓練問題,例如過度擬合、漸層消失,以及其他阻止模型收斂的問題,請使用 SageMaker Debugger 並在製作機器學習 (ML) 模型的原型和訓練時採取自動化動作。如需詳細資訊,請參閱Amazon SageMaker Debugger。要查找模型參數的完整分析,請參閱 Amazon SageMaker Debugger 可解釋性
範例筆記本。
您現在擁有一個成功地訓練好的 XGBoost 模型。SageMaker AI 會將模型成品存放在 S3 儲存貯體中。若要尋找模型成品的位置,請執行下列程式碼以列印 xgb_model 估算器的 model_data 屬性:
xgb_model.model_data
提示
若要測量機器學習 (ML) 生命週期每個階段 (資料收集、模型訓練和調整,以及監控部署用於預測的機器學習 (ML) 模型) 期間可能發生的偏差,請使用 SageMaker Clarify。如需詳細資訊,請參閱模型可解釋性。有關端對端範例,請參閱公平性和解釋性與 SageMaker Clarify
