本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Factorization Machines 的運作方式
因式分解機模型的預測任務是預估從功能集 xi 到目標域的函式。此領域是迴歸的真值,以及分類的二進位。因式分解機模型受到監督,因此具有訓練資料集 (xi,yj)。此模型的優勢,在於其使用分解參數化來擷取逐對特徵互動。可以用數學方式呈現如下:
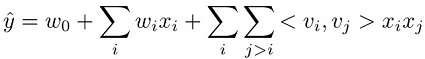
此方程式中的三項分別對應至模式的三個元件:
-
w0 項代表全域偏差。
-
wi 線性項模仿 ith 變數的強度。
-
<vi,vj> 分解項模仿 ith 和 jth 變數之間的逐對互動。
全域偏差和線性項會與線性模型一致。系統會以第三項建立逐對特徵互動模型,並將其用於對應因素的內積值,以供各種特徵學習。或者,您也可以將學習因素視為各特徵的內嵌向量。以分類任務為例,如果在標籤為正數的樣本中,一組特徵同時出現的頻率逐漸提升,則這組特徵的內積值也會隨之提高。換句話說,這組特徵的內嵌向量在餘絃相似度上,結果會非常相近。如需因式分解機模型的詳細資訊,請參閱因式分解機
針對迴歸任務,系統為了有效訓練模型,會將模型預測值 ŷn 與目標值 yn 之間的平方誤差減到最低。這也稱為平方損失:
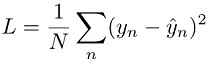
針對分類任務,系統會訓練模型來將跨熵遺失減到最低 (也稱為損失函式):
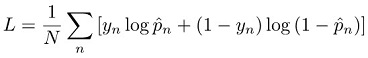
其中:
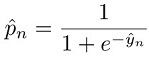
如需分類之損失函式的詳細資訊,請參閱分類的損失函式
