本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
建議結果
每個推論建議任務結果都包含 InstanceType、InitialInstanceCount 和 EnvironmentParameters,這些參數是針對容器調整的環境變數參數,以改善其延遲和輸送量。結果還包含效能和成本指標,例如 MaxInvocations、ModelLatency、CostPerHour、CostPerInference、CpuUtilization 和 MemoryUtilization。
在下表中,我們提供了這些指標的說明。這些指標可協助您縮小搜尋範圍,找出適合您使用案例的最佳端點組態。例如,如果您的動機是強調輸送量的整體價格表現,那麼您應專注於 CostPerInference。
| 指標 | 描述 | 使用案例 |
|---|---|---|
|
|
從 SageMaker AI 檢視時,模型回應所花費的時間間隔。這個間隔包含傳送請求和從模型容器擷取回應的本機通訊時間,以及在容器中完成推論的時間。 單位:毫秒 |
延遲敏感的工作負載,例如廣告投放和醫療診斷 |
|
|
一分鐘內傳送到模型端點的 單位:無 |
以輸送量為中心的工作負載,例如影片處理或批次推論 |
|
|
即時端點每小時的預估成本。 單位:美元 |
成本敏感的工作負載,無延遲期限 |
|
|
即時端點每次推論呼叫的預估成本。 單位:美元 |
專注於輸送量,將整體價格效能發揮到極致 |
|
|
端點執行個體每分鐘調用上限時的預期 CPU 利用率。 單位:百分比 |
透過了解執行個體的核心 CPU 利用率,掌握基準測試期間的執行個體運作狀態 |
|
|
端點執行個體每分鐘調用上限時的預期記憶體利用率。 單位:百分比 |
透過了解執行個體的核心記憶體利用率,掌握基準測試期間的執行個體運作狀態 |
在某些情況下,您可能想要探索其他 SageMaker AI 端點調用指標,例如 CPUUtilization。每個 Inference Recommender 任務結果都包含負載測試期間啟動的端點名稱。即使這些端點已刪除,您也可以使用 CloudWatch 來檢閱這些端點的日誌。
下列影像是 CloudWatch 指標和圖表的範例,您可以從建議結果檢閱單一端點。此建議結果來自某項預設任務。解讀建議結果中的純量值的方法是,它們是根據調用圖表首次開始向外平整時的時間點。例如,報告的 ModelLatency 值是在 03:00:31 高原的開始處持平。
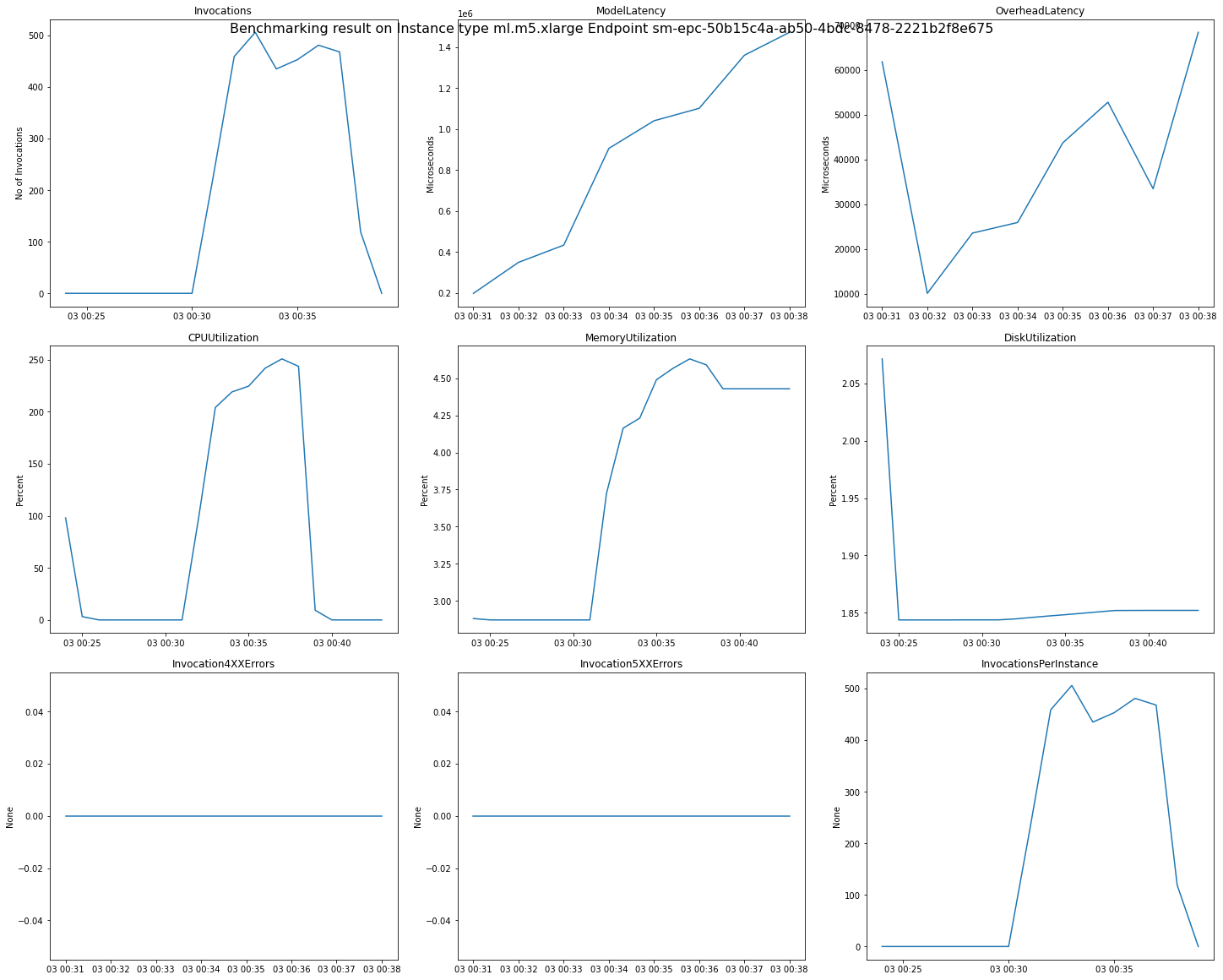
如需前述圖表中使用的 CloudWatch 指標的完整說明,請參閱 SageMaker AI 端點調用指標。
您也可以在 /aws/sagemaker/InferenceRecommendationsJobs 命名空間中查看 Inference Recommender 所發佈的效能指標,例如 ClientInvocations 和 NumberOfUsers。如需 Inference Recommender 所發佈的指標和說明之完整指標清單,請參閱SageMaker Inference Recommender 任務指標。
請參閱 amazon-sagemaker-examples
