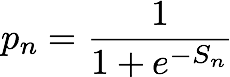本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
IP Insights 的運作方式
Amazon SageMaker AI IP Insights 是一種非監督式演算法,會使用觀察資料,形式為 (實體、IPv4 地址) 配對,將實體與 IP 地址建立關聯。IP Insights 會學習實體和 IP 地址的隱藏向量表示,判斷實體使用特定 IP 地址的機率有多高。這兩個表示之間的距離接著可做為代理,表示此關聯成立的機率有多高。
IP Insights 演算法會使用神經網路來學習實體和 IP 地址的隱藏向量表示。實體會先雜湊到大型但固定的雜湊空間,然後由簡單的內嵌層編碼。字元字串 (例如使用者名稱或帳戶 ID) 則可以在日誌檔案中呈現的方式,直接提供給 IP Insights。您不需要為實體識別符預先處理資料。您可以在訓練和推論期間提供實體做為任意字串值。雜湊大小應使用夠高的值設定,確保當相異實體映射到相同的隱藏向量時所發生的衝突數量會維持在少量狀態。如需如何選取適當雜湊大小的詳細資訊,請參閱 Feature Hashing for Large Scale Multitask Learning
在訓練期間,IP Insights 會隨機配對實體和 IP 地址,自動產生負面樣本。這些負面樣本可代表現實中較不容易發生的資料。模型會訓練成可辨別在訓練資料中觀察到的正面樣本,以及這些產生的負面樣本。更精確而言,模型會訓練成可最小化交叉熵,又稱為對數損失,其定義如下:
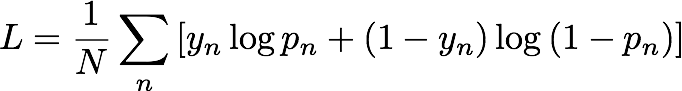
yn 是標籤,指出樣本是來自掌管觀察資料的真實分佈 (yn=1),還是來自產生負面樣本的分佈 (yn=0)。pn 是樣本來自真實分佈的機率,如模型所預測。
產生負面樣本是一項重要程序,用於達到觀察資料的準確模型。若負面樣本的機率過低 (例如,若所有負面樣本中的 IP 地址都是 10.0.0.0),則模型會無法學習如何辨別負面樣本,而無法準確地了解實際觀察資料集的特性。為了使負面樣本維持在較真實的狀態,IP Insights 不但會隨機產生 IP 地址,同時也會從訓練資料中隨機挑選 IP 地址,來產生負面樣本。您可以使用 random_negative_sampling_rate 和 shuffled_negative_sampling_rate 超參數,設定負面抽樣的類型,以及產生任一種負面樣本的比例。
指定第 n 個 (實體、IP 地址配對),IP Insights 模型會輸出一個分數 (Sn),指出實體和 IP 地址的相容程度為何。相較於來自負面分布,此分數會對應到來自真實分布配對指定 (實體、IP 地址) 的對數機率比 (log odds ratio)。其定義如下:
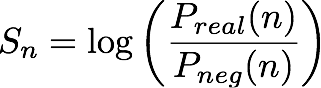
該分數基本上是測量第 n 個實體及 IP 地址向量表示之間相似度的指標。它可以解譯為相較於隨機產生的資料集,在現實中更可能會觀察到此事件的機率。在訓練期間,演算法會使用分數來計算來自真實分布 (pn) 樣本的機率估計,以在最小化交叉熵的過程中使用,其中: