本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用生產變體測試模型
在生產機器學習 (ML) 工作流程中,資料科學家和工程師經常嘗試以各種方式改善效能,例如執行 使用 SageMaker AI 自動調校模型、訓練其他或更新的資料、改善功能選擇、使用更好的更新執行個體和服務容器。您可以使用生產變體來比較模型、執行個體和容器,並選擇最佳執行候選項來回應推論請求。
使用 SageMaker AI 多變體端點,您可以透過為每個變體提供流量分佈,將端點調用請求分散到多個生產變體,或者您可以直接為每個請求調用特定變體。在本主題中,這兩種方法都會用來測試機器學習 (ML) 模型。
指定流量分配來測試模型
若要在多個模型之間分配流量以測試模型,請在端點組態中指定每個生產變體的權重,以指定要路由至每個模型的流量百分比。如需相關資訊,請參閱 CreateEndpointConfig。下圖顯示更詳細的運作情形。

調用特定變體來測試模型
若要透過調用每個請求的特定模型來測試多個模型,請在呼叫 InvokeEndpoint 時提供 TargetVariant 參數值,以指定要調用的特定模型版本。SageMaker AI 可確保請求由您指定的生產變體處理。如果您已提供流量分配並指定 TargetVariant 參數的值,則目標路由會覆寫隨機流量分配。下圖顯示更詳細的運作情形。

模型 A/B 測試範例
在新模型的驗證過程中,使用生產流量在新模型和舊模型之間執行 A/B 測試,是很有效的最後步驟。在 A/B 測試中,您可以測試模型的不同變體,並比較每個變體的表現。如果較新版的模型比現有版本的效能更好,請在生產環境中以新版本取代舊版模型。
下列範例示範如何執行 A/B 模型測試。如需實作此範例的範例筆記本,請參閱在生產環境中進行機器學習 (ML) 模型 A/B 測試
步驟 1:建立和部署模型
首先,我們在 Amazon S3 中定義模型所在的位置。我們在後續步驟部署模型時會使用這些位置:
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
接下來,我們以影像和模型資料建立模型物件。這些模型物件用於將生產變體部署到端點。我們以不同的資料集、不同的演算法或機器學習 (ML) 架構及不同的超參數來訓練機器學習 (ML) 模型,以開發模型:
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
現在,我們建立兩個生產變體,各自有不同的模型和資源需求 (執行個體類型和計數)。這可讓您在不同的執行個體類型上測試模型。
我們將兩個變體的 initial_weight 都設為 1。這表示 50% 的請求傳送至 Variant1,其餘 50% 的請求傳送至 Variant2。這兩個變體的權重總和是 2,每個變體的權重分配為 1。這表示每個變體會收到總流量的 1/2 (或 50%)。
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
最後,我們已準備好在 SageMaker AI 端點上部署這些生產變體。
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
步驟 2:調用已部署的模型
現在,我們將請求傳送至這個個端點以即時獲得推論。我們使用流量分配和直接設定目標。
首先,我們使用上一個步驟中設定的流量分配。每個推論回應都包含負責處理請求的生產變體名稱,因此,我們可以看到兩個生產變體的流量大致相等。
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker AI Invocations會針對 Amazon CloudWatch 中的每個變體發出 Latency和 等指標。如需 SageMaker AI 發出指標的完整清單,請參閱 Amazon CloudWatch 中的 Amazon SageMaker AI 指標 Amazon CloudWatch。我們來查詢 CloudWatch 以取得每個變體的調用次數,以了解調用如何依預設值分配給變體:
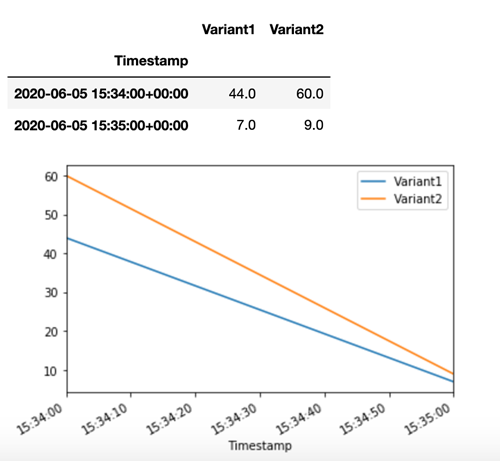
現在,讓我們在呼叫 invoke_endpoint 時將 Variant1 指定為 TargetVariant,以調用特定版本的模型。
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
若要確認所有新的調用都由 Variant1 處理,我們可以查詢 CloudWatch 以取得每個變體的調用次數。我們看到,在最近的調用中 (最新的時間戳記),所有請求都由 Variant1 處理,符合我們的指定。沒有調用 Variant2。

步驟 3:評估模型效能
為了判斷哪個模型版本表現更好,讓我們評估每個變體的準確性、精確度、召回、F1 分數及接受者操作特性/曲線下面積。首先,讓我們看看 Variant1 的這些指標:

現在,讓我們看看 Variant2 的這些指標:

在我們已定義的大多數指標上,Variant2 表現較好,所以這就是生產環境中應該使用的變體。
步驟 4:增加最佳模型的流量
既然已確定 Variant2 表現優於 Variant1,我們就將更多流量轉給此變體。我們可以繼續使用 TargetVariant 來調用特定的模型變體,但更簡單的方法是呼叫 UpdateEndpointWeightsAndCapacities,以更新分配給每個變體的權重。這樣可變更生產變體的流量分配,而不需要更新端點。回想一下設定這一節,我們設定變體權重將流量分割成 50/50。從以下每個變體調用總數的 CloudWatch 指標,可看出每個變體的調用模式:

現在,我們透過使用 UpdateEndpointWeightsAndCapacities 為每個變體指派新權重來將 75% 的流量轉移到 Variant2。SageMaker AI 現在會將 75% 的推論請求傳送至 ,Variant2並將剩餘的 25% 請求傳送至 Variant1。
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
從每個變體調用總數的 CloudWatch 指標,可看出 Variant2 的調用次數多於 Variant1:

我們可以繼續監控指標,而在滿意變體的效能時,就可以將 100% 的流量路由到該變體。我們使用 UpdateEndpointWeightsAndCapacities 來更新變體的流量分配。Variant1 的權重設定為 0,而 Variant2 的權重設定為 1。SageMaker AI 現在會將所有推論請求的 100% 傳送至 Variant2。
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
從每個變體調用總數的 CloudWatch 指標,可看出所有推論請求都由 Variant2 處理,而 Variant1 不處理任何推論請求。

現在,您可以放心地更新端點並從端點刪除 Variant1。在生產環境中,您也可以將新變體新增至端點,並遵循步驟 2-4,以繼續測試新模型。
