本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
多模型端點
多模型端點提供可擴展且經濟實惠的解決方案,而且可以部署大量模型。其運用相同資源機群及共享服務容器來託管所有模型。相較於使用單一模型端點,這能改善端點使用率,藉此降低託管成本。它也減少部署開銷,因為 Amazon SageMaker AI 會管理記憶體中的載入模型,並根據端點的流量模式進行擴展。
下圖顯示多模型端點與單一模型端點的運作方式。
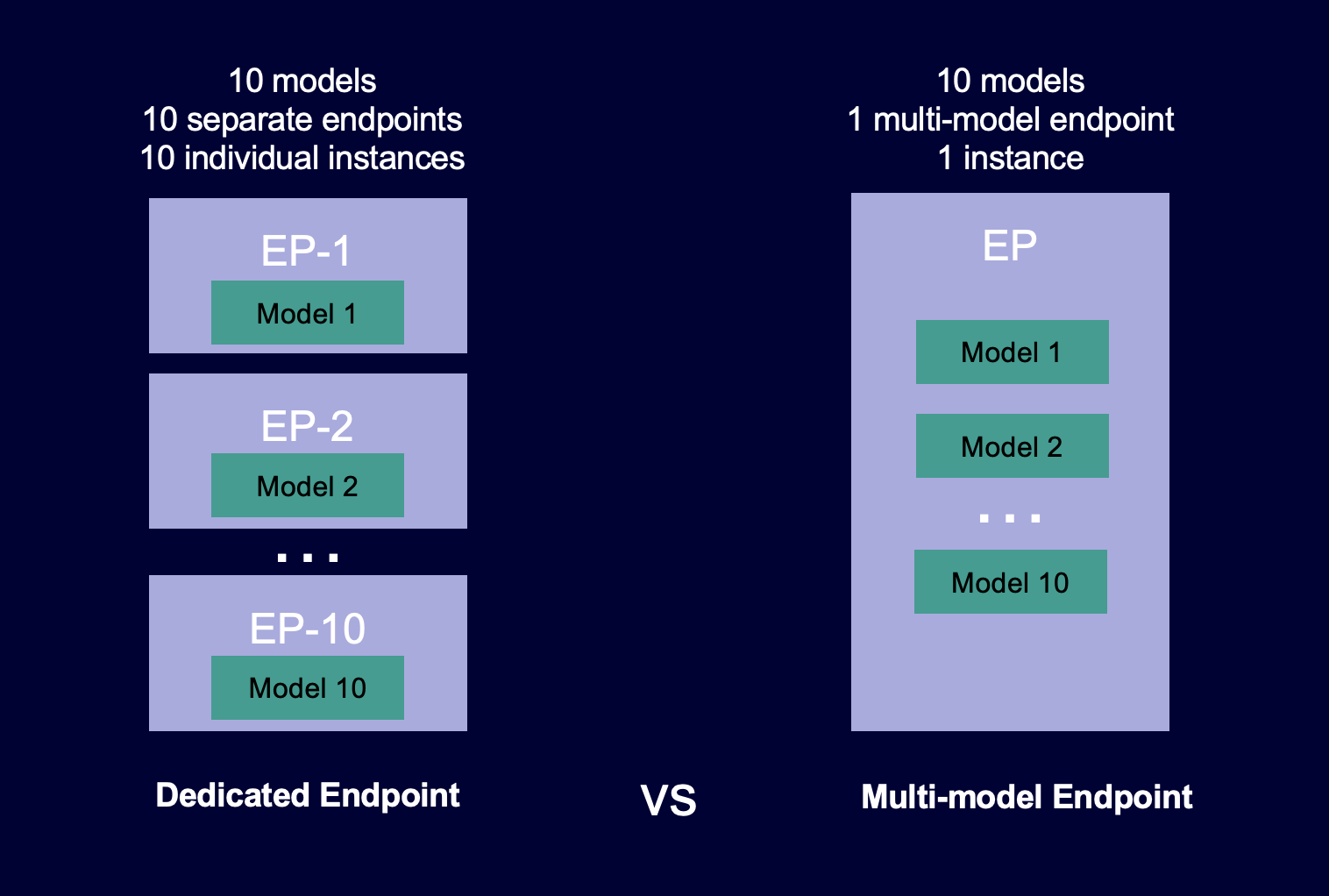
多模型端點非常適合託管大量模型,這些模型在共用服務容器採用相同機器學習 (ML) 架構。如您混合經常存取及不常存取的模型,則多模型端點可利用有效率的方式為此流量提供服務,運用更少資源並節省更多成本。您的應用程式應能容忍偶爾發生的冷啟動相關延遲處罰,這會在調用不常使用的模型時發生。
多模型端點支援託管 CPU 與 GPU 支援的模型。藉由採用 GPU 支援的模型,您可透過增加端點及其基礎加速運算執行個體的使用量來降低模型部署成本。
多模型端點也能支援跨模型記憶體資源的時間共享。這最適合用於模型大小和調用延遲相當類似的情況。在這種情況下,多模型端點可有效地在所有模型中使用執行個體。如果您的模型有明顯較高的每秒交易次數 (TPS) 或延遲需求,建議您將模型託管於專用端點。
您可利用具有下列特徵的多模型端點:
-
AWS PrivateLink VPCs
-
序列推論管道 (但推論管道僅能包含單一啟用多模型功能的容器)
-
A/B 測試
您可以使用 AWS SDK for Python (Boto) 或 SageMaker AI 主控台來建立多模型端點。對於 CPU 支援的多模型端點,您可整合多模型伺服器
主題
多模型端點的運作方式
SageMaker AI 會管理容器記憶體中多模型端點上託管的模型生命週期。當您建立端點時,SageMaker AI 不會將所有模型從 Amazon S3 儲存貯體下載到容器,而是在您叫用它們時動態載入和快取它們。當 SageMaker AI 收到特定模型的調用請求時,它會執行下列動作:
-
路由請求至端點後方單一執行個體。
-
將模型從 S3 儲存貯體下載到該執行個體的儲存磁碟區。
-
載入模型至該加速運算執行個體的容器記憶體 (CPU 或 GPU,視您擁有 CPU 或 GPU 支援的執行個體而定)。如果模型已載入容器的記憶體中,調用速度會更快,因為 SageMaker AI 不需要下載和載入它。
SageMaker AI 會持續將模型的請求路由到已載入模型的執行個體。不過,如果模型收到許多調用請求,且多模型端點還有其他執行個體,SageMaker AI 會將一些請求路由到另一個執行個體,以容納流量。如果模型尚未載入第二個執行個體,則模型會下載到該執行個體的儲存磁碟區,並載入容器的記憶體中。
當執行個體的記憶體使用率很高且 SageMaker AI 需要將另一個模型載入記憶體時,它會從該執行個體的容器卸載未使用的模型,以確保有足夠的記憶體載入模型。卸載的模型會留在執行個體的儲存磁碟區上,稍後可以載入容器的記憶體,而無須從 S3 儲存貯體再次下載。如果執行個體的儲存磁碟區達到其容量,SageMaker AI 會從儲存磁碟區中刪除任何未使用的模型。
若要刪除模型,請停止傳送請求,並從 S3 儲存貯體中刪除模型。SageMaker AI 在服務容器中提供多模型端點功能。將模型新增到多模型端點或從中刪除模型時,並不需要更新端點本身。若要新增模型,請將模型上傳到 S3 儲存貯體並進行調用。您不需要變更程式碼也能使用。
注意
當您更新多模型端點時,隨著多模型端點的智慧路由適應流量模式,端點的初始調用請求可能經歷較高延遲。但在其了解流量模式之後,您即可針對最常用模型體驗低延遲情況。較少使用的模型可能產生部分冷啟動延遲,這是由於模型會動態載入至執行個體。
多模型端點的範例筆記本
若要進一步了解如何使用多模型端點,可嘗試下列範例筆記本:
-
採用 CPU 支援執行個體的多模型端點範例:
-
多模型端點 XGBoost 範例筆記本
– 此筆記本說明如何將多個 XGBoost 模型部署至端點。 -
多模型端點 BYOC 範例筆記本
– 此筆記本說明如何在 SageMaker AI 中設定和部署支援多模型端點的客戶容器。
-
-
採用 GPU 支援執行個體的多模型端點範例:
-
使用 Amazon SageMaker AI 多模型端點 (MME) 在 GPUs 上執行多個深度學習模型
– 此筆記本說明如何使用 NVIDIA Triton 推論容器將 ResNet-50 模型部署到多模型端點。
-
如需如何建立和存取 Jupyter 筆記本執行個體的指示,您可以使用這些執行個體在 SageMaker AI 中執行先前的範例,請參閱 Amazon SageMaker 筆記本執行個體。在您建立並開啟筆記本執行個體之後,請選擇 SageMaker AI 範例索引標籤以查看所有 SageMaker AI 範例的清單。多模型端點筆記本位於 ADVANCED FUNCTIONALITY (進階功能) 區段。若要開啟筆記本,請選擇其 Use (使用) 標籤,然後選擇 Create copy (建立複本)。
如需有關多模型端點使用案例的詳細資訊,請參閱下列部落格與資源:
