本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
了解座標系統和感應器融合
點雲資料永遠位於座標系統中。此座標系統可能是車輛或感測周遭環境的裝置的本地座標系統,也可能是世界座標系統。使用 Ground Truth 3D 點雲標籤工作時,所有註釋都是使用輸入資料的座標系統來產生。對於某些標籤工作類型和功能,您必須以世界座標系統提供資料。
在本主題中,您將了解:
-
何時需要以世界座標系統 (或全球參考架構) 提供輸入資料。
-
世界座標是什麼,以及如何將點雲資料轉換為世界座標系統。
-
使用感應器融合時,如何使用感應器和相機外部矩陣來提供姿態資料。
標籤工作的座標系統需求
如果您的點雲資料是以本地座標系統收集,您可以使用感應器的外部矩陣來收集資料,以轉換為世界座標系統 (或全球參考架構)。如果您無法取得點雲資料的外部矩陣,因而無法以世界座標系統取得點雲,則您可以採用本地座標系統,為 3D 點雲物件偵測和語意分割任務類型提供點雲資料。
對於物件追蹤,您必須以世界座標系統提供點雲資料。這是因為跨多個影格追蹤物件時,自駕車本身正在某個地方移動,因此,所有影格都需要參考點。
如果您包含感應器融合的相機資料,建議採用與 3D 感應器 (例如 LiDAR 感應器) 相同的世界座標系統來提供相機姿態。
在世界座標系統中使用點雲資料
本節說明什麼是世界座標系統 (WCS) (也稱為全球參考架構),並說明如何在世界座標系統中提供點雲資料。
什麼是世界座標系統?
WCS (或全球參考架構) 是固定的通用座標系統,也是車輛和感應器座標系統所依據的系統。例如,如果多個點雲影格因為是從兩個感應器收集,而位於不同的座標系統中,則可使用 WCS 將這些點雲影格中的所有座標,轉換為單一座標系統,其中所有影格都有相同的原點,即 (0,0,0)。此轉換的作法是使用平移向量,將每個影格的原點平移為 WCS 的原點,然後使用旋轉矩陣,將三個軸 (通常為 x、y 和 z) 旋轉到正確的方向。這種剛體轉換稱為齊次轉換。
世界座標系統在全球路徑規劃、本地化、製圖和駕駛情境模擬中非常重要。Ground Truth 使用右手笛卡兒世界座標系統,例如 ISO 8855
全球參考架構取決於資料。有些資料集使用第一個影格中的 LiDAR 位置作為原點。在這種情況下,所有影格都使用第一個影格作為參考,裝置方位和位置會在第一個影格的原點附近。例如,KITTI 資料集以第一個影格作為世界座標的參考。其他資料集使用不同於原點的裝置位置。
請注意,這不是 GPS/IMU 座標系統 (通常沿著 z 軸旋轉 90 度)。如果點雲資料採用 GPS/IMU 座標系統 (例如開放原始碼 AV KITTI 資料集裡的 OxTS),則您需要將原點轉換為世界座標系統 (通常是車輛的參考座標系統)。您可以將資料乘以轉換指標 (旋轉矩陣和平移向量),以套用此轉換。這會將資料從原始座標系統轉換為全球參考座標系統。請在下一節進一步了解這項轉換。
將 3D 點雲資料轉換為 WCS
Ground Truth 假定點雲資料已轉換為您選擇的參考座標系統。例如,您可以選擇感應器的參考座標系統 (例如 LiDAR),作為全球參考座標系統。您也可以從各種感應器取得點雲,然後將點雲從感應器視圖,轉換為車輛的參考座標系統視圖。您可以使用感應器的外部矩陣 (由旋轉矩陣和平移向量組成),將點雲資料轉換為 WCS (或全球參考架構)。
總之,平移向量和旋轉矩陣可用於組成外部矩陣,而此矩陣可用於將資料從區域座標系統轉換為 WCS。例如,假設 LiDAR 外部矩陣的組成如下,其中 R 是旋轉矩陣,T 是平移向量:
LiDAR_extrinsic = [R T;0 0 0 1]
例如,針對每個架構的 LiDAR 外在變換矩陣,自動駕駛 KITTI 資料集包含旋轉矩陣和平移向量。pykittidataset.oxts[i].T_w_imu 為第 i 個影格提供 LiDAR 外部轉換,而且可以與該影格中的點相乘,以轉換為世界架構 - np.matmul(lidar_transform_matrix, points)。將 LiDAR 影格中的點與 LiDAR 外部矩陣相乘,可將此點轉換為世界座標。將全球影格中的點與相機外部矩陣相乘,可得出相機參考架構中的點座標。
以下程式碼範例示範如何將 KITTI 資料集裡的點雲影格轉換為 WCS。
import pykitti import numpy as np basedir = '/Users/nameofuser/kitti-data' date = '2011_09_26' drive = '0079' # The 'frames' argument is optional - default: None, which loads the whole dataset. # Calibration, timestamps, and IMU data are read automatically. # Camera and velodyne data are available via properties that create generators # when accessed, or through getter methods that provide random access. data = pykitti.raw(basedir, date, drive, frames=range(0, 50, 5)) # i is frame number i = 0 # lidar extrinsic for the ith frame lidar_extrinsic_matrix = data.oxts[i].T_w_imu # velodyne raw point cloud in lidar scanners own coordinate system points = data.get_velo(i) # transform points from lidar to global frame using lidar_extrinsic_matrix def generate_transformed_pcd_from_point_cloud(points, lidar_extrinsic_matrix): tps = [] for point in points: transformed_points = np.matmul(lidar_extrinsic_matrix, np.array([point[0], point[1], point[2], 1], dtype=np.float32).reshape(4,1)).tolist() if len(point) > 3 and point[3] is not None: tps.append([transformed_points[0][0], transformed_points[1][0], transformed_points[2][0], point[3]]) return tps # customer transforms points from lidar to global frame using lidar_extrinsic_matrix transformed_pcl = generate_transformed_pcd_from_point_cloud(points, lidar_extrinsic_matrix)
感應器融合
Ground Truth 最多支援以 8 個攝影機輸入來進行點雲資料的感應器融合。此功能可讓標籤人員,將同步化視訊影格與 3D 點雲影格並排檢視。除了提供更視覺化的環境來協助標籤,感應器融合還可讓工作者在 3D 場景和 2D 影像中調整註釋,而調整會投影到其他視圖。以下影片示範使用 LiDAR 和相機感應器融合,以執行 3D 點雲標籤工作。
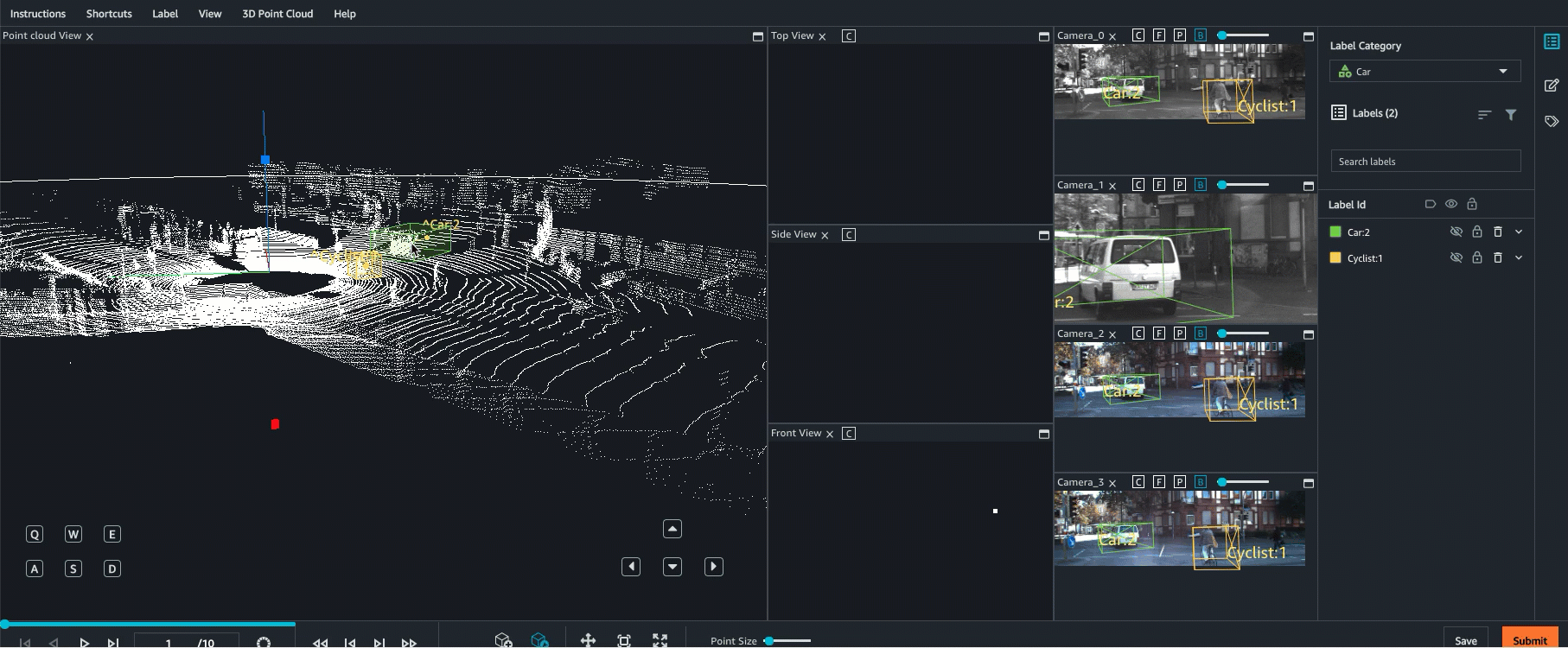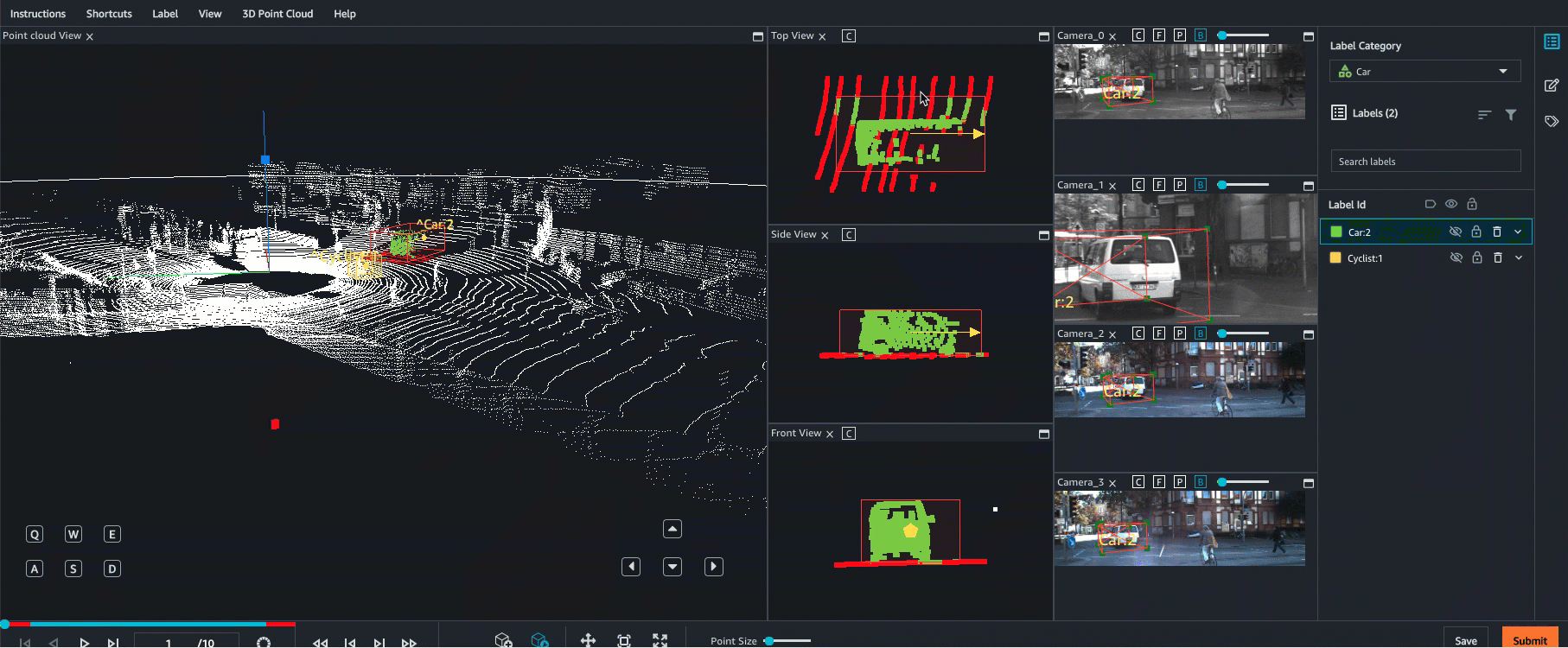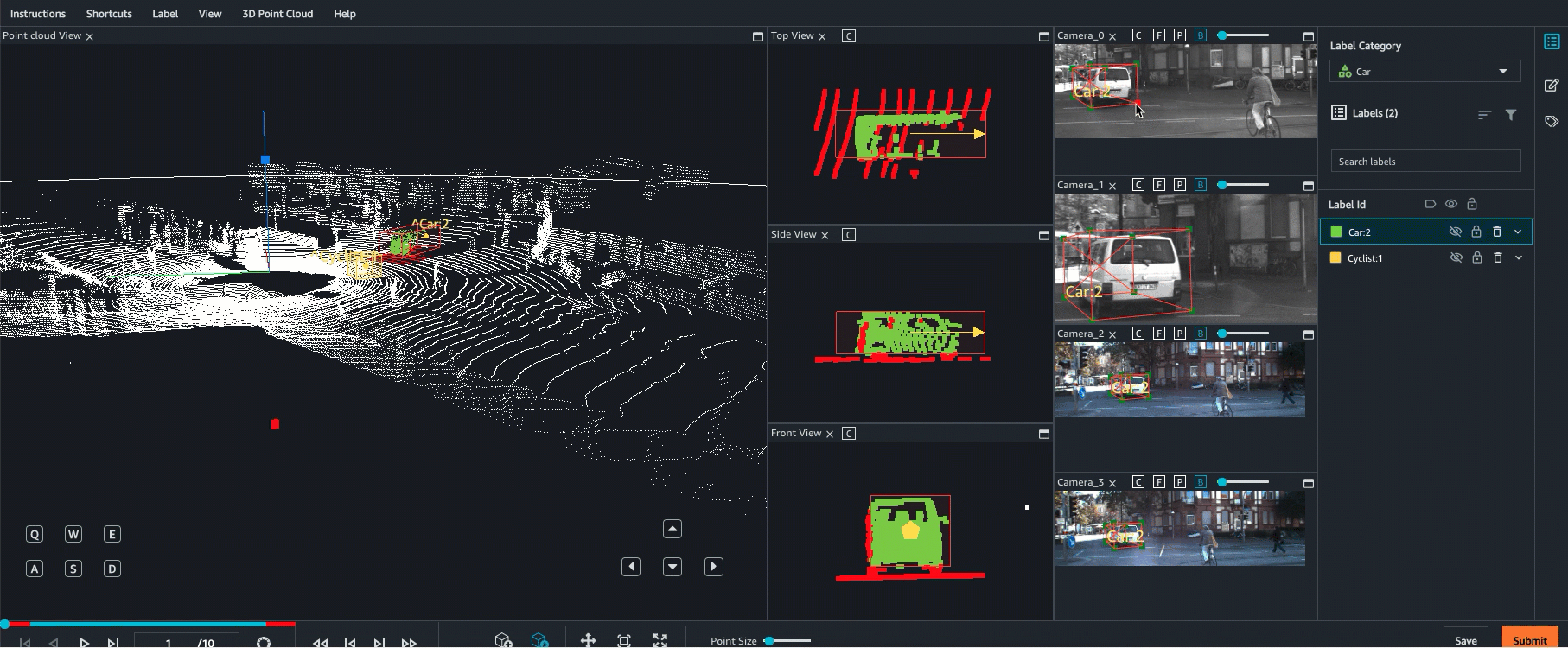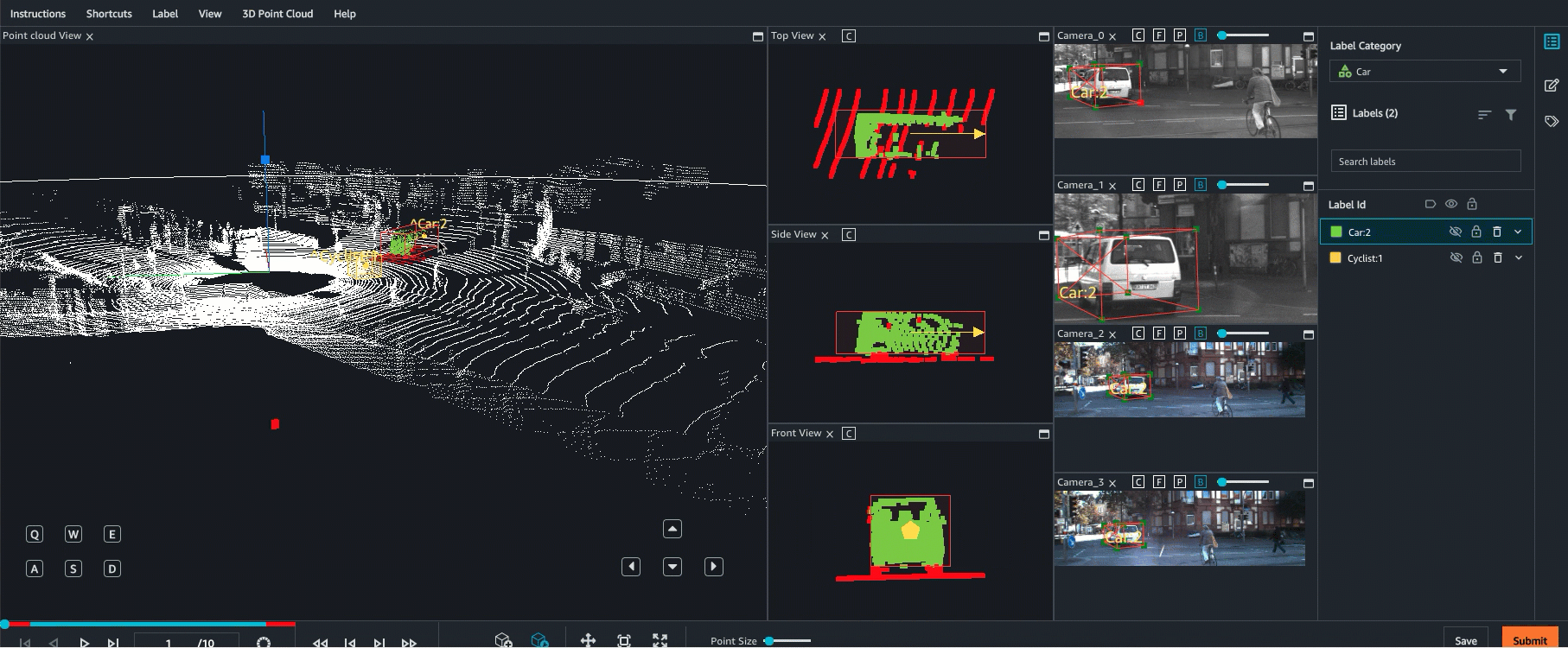
為獲得最佳結果,使用感應器融合時,點雲應採用 WCS。Ground Truth 使用感應器 (例如 LiDAR)、攝影機和自駕車姿態資訊,以計算感應器融合的外部和內部矩陣。
外部矩陣
Ground Truth 使用感應器 (例如 LiDAR) 外部矩陣及相機外部和內部矩陣,在點雲資料的參考架構和相機的參考架構之間,來回投影物件。
例如,為了將標籤從 3D 點雲投影至相機影像平面,Ground Truth 會將 3D 點從 LiDAR 自己的座標系統,轉換為相機的座標系統。在作法上,通常是先使用 LiDAR 外部矩陣,將 3D 點從 LiDAR 自己的座標系統轉換為世界座標系統 (或全球參考架構)。接著,Ground Truth 使用相機外部逆矩陣 (將點從全球參考架構轉換為相機的參考架構),將前一個步驟中取得的 3D 點,從世界座標系統轉換為相機影像平面。LiDAR 外部矩陣也可用於將 3D 資料轉換為世界座標系統。如果 3D 資料已轉換為世界座標系統,則第一次轉換完全不影響標籤平移,標籤平移只取決於相機外部逆矩陣。視圖矩陣用於將投影標籤視覺化。若要進一步了解這些轉換和視圖矩陣,請參閱Ground Truth 感應器融合轉換。
Ground Truth 使用您提供的 LiDAR 和相機姿態資料,以計算這些外部矩陣:heading (以四元數為單位:qx、qy、qz 及 qw) 和 position (x、y、z)。對於車輛而言,通常以世界座標系統在車輛參考架構中描述方位和位置,稱為自駕車姿態。對於每個相機外部矩陣,您可以為該相機新增姿態資訊。如需詳細資訊,請參閱姿態。
內部矩陣
Ground Truth 使用相機外部和內部矩陣來計算檢視指標,在 3D 場景和相機影像之間轉換標籤。Ground Truth 會使用您提供的相機焦距 (fx、fy) 和光學中心座標 (cx、cy) 計算相機內部矩陣。如需詳細資訊,請參閱 內部和失真。
影像失真
影像失真有各種原因。例如,影像可能因為桶形或魚眼效果而失真。Ground Truth 使用內部參數及失真係數,矯正您建立 3D 點雲標籤工作時提供的影像。如果已矯正相機影像,則所有失真係數應該都設為 0。
如需 Ground Truth 對失真影像所做轉換的更多相關資訊,請參閱相機校準:外部、內部和失真。
自駕車
為了收集自動駕駛應用的資料,將會從安裝在車輛上 (或自駕車) 的感應器收集測量值,以用來產生點雲資料。為了在 3D 場景和 2D 影像之間投影標籤調整,Ground Truth 需要採用世界座標系統的自駕車姿態。自駕車姿態由位置座標和方向四元數組成。
Ground Truth 使用自駕車姿態來計算旋轉矩陣和變換矩陣。三維旋轉可以透過圍繞一系列軸的一系列 3 個旋轉來表示。理論上,橫跨 3D 歐幾里德空間的任何三個軸就足夠。實際上會選擇旋轉的軸作為基礎向量。這三個旋轉預期採用全球參考架構 (外部)。Ground Truth 不支援體心參考架構 (內部),該架構依附於旋轉中的物件並隨之移動。為了追蹤物件,Ground Truth 需要從所有車輛都在移動的全球參考中測量。使用 Ground Truth 3D 點雲標籤工作時,z 指定旋轉軸 (外旋轉),偏航歐拉角以弧度表示 (旋轉角度)。
姿態
Ground Truth 使用姿態資訊進行 3D 視覺化和感應器融合。您透過資訊清單檔案輸入的姿態資訊,用於計算外部矩陣。如果您已有外部矩陣,則可用來擷取感應器和相機姿態資料。
例如,在自動駕駛 KITTI 資料集內,pykittidataset.oxts[i].T_w_imu 為第 i 個影格提供 LiDAR 外部轉換,而且可以與點相乘,以轉換為世界架構 - matmul(lidar_transform_matrix,
points)。在輸入資訊清單檔案 JSON 格式中,此轉換可以變轉成 LiDAR 的位置 (平移向量) 和方位 (以四元數為單位)。第 i 個影格內 cam0 攝影機外部轉換可以透過 inv(matmul(dataset.calib.T_cam0_velo,
inv(dataset.oxts[i].T_w_imu))) 計算,並可以被轉換成 cam0 的標題和位置。
import numpy rotation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01]] origin= [1.71104606e+00, 5.80000039e-01, 9.43144935e-01] from scipy.spatial.transform import Rotation as R # position is the origin position = origin r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"pose:{position}\nheading: {heading}")
Position
在輸入資訊清單檔案中,position 是指感應器相對於世界架構的位置。如果您無法將裝置位置輸入世界座標系統中,您可以透過區域座標來使用 LiDAR 資料。同樣地,對於已安裝的攝影機,您可以採用世界座標系統來指定位置和方位。對於相機,如果您沒有位置資訊,請使用 (0, 0, 0)。
以下是 position 物件中的欄位:
-
x(浮點數) – 自駕車、感應器或攝影機位置的 x 座標 (以公尺為單位)。 -
y(浮點數) – 自駕車、感應器或攝影機位置的 y 座標 (以公尺為單位)。 -
z(浮點數) – 自駕車、感應器或攝影機位置的 z 座標 (以公尺為單位)。
以下是 position JSON 物件的範例:
{ "position": { "y": -152.77584902657554, "x": 311.21505956090624, "z": -10.854137529636024 } }
標題
在輸入資訊清單檔案中,heading 物件代表裝置相對於世界架構的方向。方位值應該為四元數。四元數(qx = 0, qy = 0, qz
= 0, qw = 1)。同樣地,對於相機,請以四元數指定方位。如果您無法獲得相機校準外部參數,請加上使用恆等四元數。
heading 物件中的欄位如下所示:
-
qx( 浮點數) - 自駕車、感應器或相機方向的 x 分量。 -
qy( 浮點數) - 自駕車、感應器或相機方向的 y 分量。 -
qz( 浮點數) - 自駕車、感應器或相機方向的 z 分量。 -
qw( 浮點數) - 自駕車、感應器或相機方向的 w 分量。
以下是 heading JSON 物件的範例:
{ "heading": { "qy": -0.7046155108831117, "qx": 0.034278837280808494, "qz": 0.7070617895701465, "qw": -0.04904659893885366 } }
如需進一步了解,請參閱 計算方向四元數和位置。
計算方向四元數和位置
Ground Truth 要求以四元數提供所有方向 (或方位) 資料。四元數
您可以從旋轉矩陣或變換矩陣來計算四元數。
如果您有採用世界坐標系統的旋轉矩陣 (由軸旋轉組成) 和平移向量 (或原點),而不是單一 4x4 剛體變換矩陣,則可以直接使用旋轉矩陣和平移向量來計算四元數。scipy
import numpy rotation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01]] origin = [1.71104606e+00, 5.80000039e-01, 9.43144935e-01] from scipy.spatial.transform import Rotation as R # position is the origin position = origin r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"position:{position}\nheading: {heading}")
3D Rotation Converter
如果您有 4x4 外部變換矩陣,請注意,變換矩陣的形式為 [R T; 0 0 0 1],其中 R 是旋轉矩陣,T 是原點平移向量。這意味著您可以從變換矩陣中擷取旋轉矩陣和平移向量,如下所示。
import numpy as np transformation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03, 1.71104606e+00], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02, 5.80000039e-01], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01, 9.43144935e-01], [ 0, 0, 0, 1]] transformation = np.array(transformation ) rotation = transformation[0:3,0:3] translation= transformation[0:3,3] from scipy.spatial.transform import Rotation as R # position is the origin translation position = translation r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"position:{position}\nheading: {heading}")
在您自己的設定中,您可以根據自駕車上的 LiDAR 感應器,使用 GPS/IMU 定位和方向 (緯度、經度、海拔,以及翻滾角、俯仰角、偏航角) 來計算外部變換矩陣。例如,您可以使用 pose = convertOxtsToPose(oxts),將 oxts 資料轉換為區域歐幾里德姿態 (由 4x4 剛體變換矩陣指定),以從 KITTI 原始資料計算姿態。然後,您可以在世界座標系統中,使用參考架構變換矩陣,將此姿態變換矩陣轉換為全球參考架構。
struct Quaternion { double w, x, y, z; }; Quaternion ToQuaternion(double yaw, double pitch, double roll) // yaw (Z), pitch (Y), roll (X) { // Abbreviations for the various angular functions double cy = cos(yaw * 0.5); double sy = sin(yaw * 0.5); double cp = cos(pitch * 0.5); double sp = sin(pitch * 0.5); double cr = cos(roll * 0.5); double sr = sin(roll * 0.5); Quaternion q; q.w = cr * cp * cy + sr * sp * sy; q.x = sr * cp * cy - cr * sp * sy; q.y = cr * sp * cy + sr * cp * sy; q.z = cr * cp * sy - sr * sp * cy; return q; }
Ground Truth 感應器融合轉換
以下各節更詳細討論使用您提供的姿態資料來執行 Ground Truth 感應器融合轉換。
LiDAR 外部
為了在 3D LiDAR 場景和 2D 攝影機影像之間來回投影,Ground Truth 使用自駕車姿態和方位,以計算剛體變換投影指標。Ground Truth 會執行一連串簡單的旋轉和平移,以計算世界座標到 3D 平面的旋轉和平移。
Ground Truth 使用方位四元數來計算旋轉指標,如下所示:
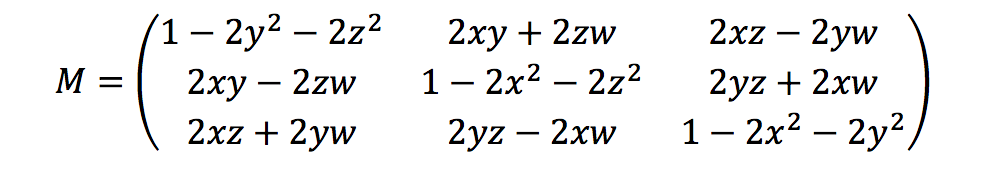
在這裡,[x, y, z, w] 會對應到 heading JSON 物件中的參數,[qx, qy, qz, qw]。Ground Truth 以 T = [poseX, poseY, poseZ] 來計算平移行向量。所以,外部指標很簡單如下所示:
LiDAR_extrinsic = [R T;0 0 0 1]
相機校準:外部、內部和失真
幾何相機校準,也稱為相機反切,可估算影像或攝影機的鏡頭和影像感應器的參數。您可以使用這些參數來校正鏡頭失真、以世界單位來測量物件的大小,或決定相機在場景中的位置。相機參數包括內部參數和失真係數。
相機外部
如果指定相機姿態,Ground Truth 會根據從 3D 平面到相機平面的剛體變換,以計算相機外部參數。計算同於 LiDAR 外部 使用的公式,差別在於 Ground Truth 使用相機姿態 (position 和 heading),並計算外部逆矩陣。
camera_inverse_extrinsic = inv([Rc Tc;0 0 0 1]) #where Rc and Tc are camera pose components
內部和失真
某些攝影機 (例如針孔或魚眼攝影機) 可能會在相片中產生明顯的失真。這種失真可以使用失真係數和攝影機焦距進行修正。如需進一步了解,請參閱 OpenCV 文件中的使用 OpenCV 校準相機
Ground Truth 可以校準的失真有兩種類型:徑向失真和正切失真。
所謂徑向失真是指接近鏡頭邊緣的光線比光學中心上更彎曲。鏡頭越小,失真越大。徑向失真是以桶形或魚眼效果呈現,Ground Truth 採用公式 1 來矯正。
公式 1:

正切失真起因於拍攝影像的鏡頭不完全平行於成像平面。這可以透過公式 2 來矯正。
公式 2:

在輸入資訊清單檔案中,您可以提供失真係數,Ground Truth 會矯正影像。所有失真係數都是浮點數。
-
k1、k2、k3、k4– 徑向失真係數。支援魚眼和針孔相機型號。 -
p1、p2– 正切失真係數。支援針孔相機型號。
如果已矯正影像,則輸入資訊清單中的所有失真係數都應該為 0。
為了正確重建矯正的影像,Ground Truth 會根據焦距對影像進行單位轉換。在上方公式中,如果兩個軸的特定長寬比使用共同焦距 (例如 1),則只有單一焦距。含有這四個參數的矩陣稱為相機校準內部矩陣。
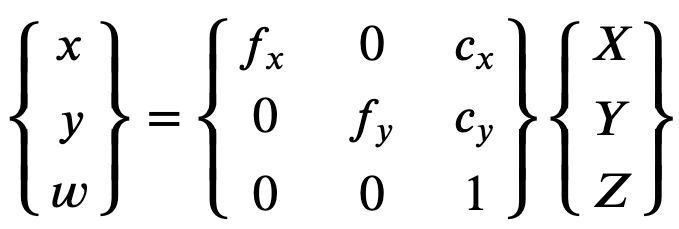
雖然不論使用何種相機解析度,失真係數都相同,但應該從校準的解析度開始,隨著目前的解析度而調整。
以下是浮點值。
-
fx- x 方向的焦距。 -
fy- y 方向的焦距。 -
cx- 主點的 x 座標。 -
cy- 主點的 y 座標。
Ground Truth 使用攝影機外部矩陣和攝影機內部矩陣來計算視圖指標,如以下程式碼區塊所示,在 3D 場景和 2D 影像之間轉換標籤。
def generate_view_matrix(intrinsic_matrix, extrinsic_matrix): intrinsic_matrix = np.c_[intrinsic_matrix, np.zeros(3)] view_matrix = np.matmul(intrinsic_matrix, extrinsic_matrix) view_matrix = np.insert(view_matrix, 2, np.array((0, 0, 0, 1)), 0) return view_matrix
