本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用批次轉錄作業進行語言識別
使用批次語言識別功能,自動識別媒體檔案中的語言。
如果您的媒體僅包含一種語言,您可以啟用單一語言識別功能,識別媒體檔案中所使用的優勢語言,並僅使用此語言建立文字記錄。
如果您的媒體包含一種以上的語言,您可以啟用多語言識別功能,識別媒體檔案中所使用的所有語言,並使用每種識別的語言建立您的文字記錄。請注意,會產生多語言文字記錄。您可以使用其他 服務 Amazon Translate來翻譯您的文字記錄。
請參閱支援的語言表,了解支援語言和相關語言代碼的完整清單。
為了獲得最佳結果,請確保您的媒體檔案至少包含 30 秒的語音。
如需 AWS Management Console AWS CLI和 AWS Python SDK 的使用範例,請參閱 使用語言識別與批次轉錄。
識別多語言音訊中的語言
多語言識別功能適用於多語言媒體檔案,並提供可反映媒體中所有支援語言的文字記錄。這代表如果發言者在對話中改變語言,或每個參與者說的是不同的語言,則您的轉錄輸出會正確偵測並轉錄每種語言。例如,如果您的媒體包含在美國英文 (en-US) 和印地文 (hi-IN)之間交替使用的雙語使用者,則多語言識別可以識別並將美國英文轉錄為 en-US,並將口語印地文轉錄為 hi-IN。
這與單一語言識別不同,只使用一種優勢語言以建立轉錄。在這種情況下,任何不是優勢語言的口語語言都會被錯誤轉錄。
注意
多語言識別目前不支援修訂和自訂語言模型。
注意
目前支援多語言識別:en-AB、en-AU、en-GB、en-IE、en-IN、en-NZ、en-US、en-WL、en-ZA、es-ES、es-US、fr-CA、fr-FR、zh-CN、zh-TW、pt-BR、pt-PT、de-CH、de-DE、af-ZA、ar-AE、da-DK、he-IL、hi-IN、id-ID、fa-IR、i-IT、ja-JP、ko-KR、ms-MY、nl-N、ru-RU、ta-IN、TH-IN、TH-IN、TH-
多語言文字記錄提供偵測到的語言摘要,以及媒體中每種語言的總使用時間。範例如下:
"results": { "transcripts": [ { "transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す" } ],..."language_codes": [ { "language_code": "en-US", "duration_in_seconds": 2.45 }, { "language_code": "hi-IN", "duration_in_seconds": 5.325 }, { "language_code": "ja-JP", "duration_in_seconds": 4.15 } ] }
提高語言識別準確性
使用語言識別功能,您可以選擇包含您認為可能存在於媒體中的語言清單。包含語言選項 (LanguageOptions) 限制只 Amazon Transcribe 使用您在將音訊與正確語言配對時指定的語言,這可以加快語言識別速度並改善與指派正確語言方言相關聯的準確性。
如果您選擇包含語言代碼,則必須包含至少兩個。您可以包含的語言代碼數量沒有限制,但我們建議您使用二到五個,以達到最佳的效率和準確性。
注意
如果您在請求中包含語言代碼,而且您提供的語言代碼不符合音訊中識別的語言,則 會從您指定的語言代碼 Amazon Transcribe 中選取最接近的語言。然後,它會產生該語言的文字記錄。例如,如果您的媒體是美式英文 (en-US)fr-FR,並且您提供 Amazon Transcribe 語言代碼 zh-CN、 和 de-DE, Amazon Transcribe 則 可能會將媒體與德文 (de-DE) 配對,並產生德文轉錄。語言代碼和口語語言不符可能會導致文字記錄不正確,因此我們建議您在包含語言代碼時要小心。
結合語言識別與其他 Amazon Transcribe 功能
您可以將批次語言識別與任何其他 Amazon Transcribe
功能結合使用。如果將語言識別與其他功能結合使用,則僅限於這些功能支援的語言。例如,如果使用語言識別搭配內容修訂,您僅限於美式英文 (en-US) 或美式西班牙文 (es-US),因為這僅適用於修訂的語言。請參閱 支援的語言和特定語言功能,了解詳細資訊。
重要
如果您在啟用內容修訂的情況下使用自動語言識別,且音訊包含美式英文 (en-US) 或美式西班牙文 (es-US) 以外的語言,則您的文字記錄中只會修訂美式英文或美式西班牙文內容。其他語言無法修訂,也且不回出現警告或工作失敗。
自訂語言模型,自訂詞彙和自訂詞彙篩選
如果您要在語言識別請求中新增一或多個自訂語言模型、自訂詞彙或自訂詞彙篩選,您必須加入 LanguageIdSettings 參數。然後,您可以使用對應的自訂語言模型、自訂詞彙和自訂詞彙篩選,指定語言代碼。請注意,多語言識別不支援自訂語言模型。
建議您在使用 LanguageIdSettings 時加入 LanguageOptions,以確保識別正確的語言方言。例如,如果您指定en-US自訂詞彙,但 Amazon Transcribe 判斷媒體中所使用的語言為 en-AU,則您的自訂詞彙不會套用至您的轉錄。如果您加入 LanguageOptions 並指定 en-US 為唯一的英文方言,則您的自訂詞彙會套用至您的轉錄。
如需請求中的 LanguageIdSettings 範例,請參閱 AWS CLI 和 使用語言識別與批次轉錄 一節中 AWS SDK 下拉式面板中的選項 2 。
使用語言識別與批次轉錄
您可以使用 AWS Management Console、AWS CLI 或 AWS SDK,在批次轉錄作業中使用自動語言識別;請參閱下列範例:
-
在導覽窗格中,選擇轉錄作業,然後選擇建立作業(右上角)。這會開啟指定作業詳細資訊頁面。
-
在工作設定面板中,找到語言設定區段,然後選擇自動語言識別或 自動多語言識別。
如果您知道音訊檔案中有哪些語言,您可以選擇多種語言選項 (從選擇語言下拉式方塊中)。提供語言選項可以提高準確性,但不是必需。
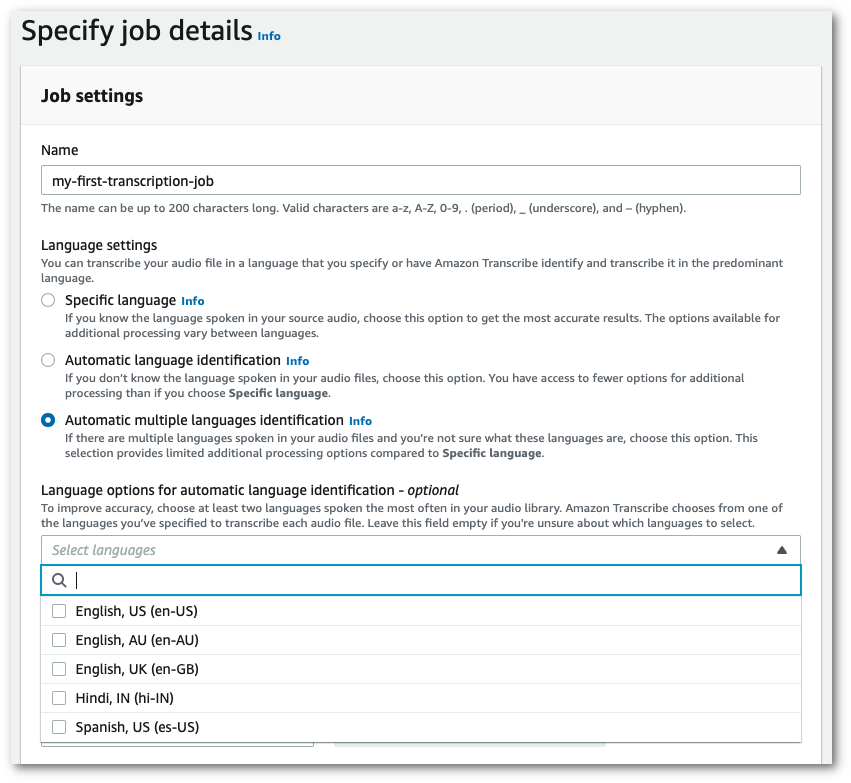
-
填入您要包含在指定作業詳細資訊頁面上的任何其他欄位,然後選擇下一步。這會引導您前往設定工作 - 選擇性頁面。

-
選擇建立作業以執行轉錄作業。
此範例使用 start-transcription-jobIdentifyLanguage 參數。如需詳細資訊,請參閱StartTranscriptionJob及LanguageIdSettings。
選項 1:沒有 language-id-settings 參數。如果您未在請求中包含自訂語言模型、自訂詞彙或自訂詞彙篩選,請使用此選項。language-options 為選用操作,但建議您採用。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
選項 2:使用 language-id-settings 參數。如果您要在請求中包含自訂語言模型、自訂詞彙或自訂詞彙篩選,請使用此選項。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
這是使用 start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
檔案 my-first-language-id-job.json 包含以下請求內文。
選項 1:沒有 LanguageIdSettings 參數。如果您未在請求中包含自訂語言模型、自訂詞彙或自訂詞彙篩選,請使用此選項。LanguageOptions 為選用操作,但建議您採用。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true), "LanguageOptions": [ "en-US", "hi-IN" ] }
選項 2:使用 LanguageIdSettings 參數。如果您要在請求中包含自訂語言模型、自訂詞彙或自訂詞彙篩選,請使用此選項。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true) "LanguageOptions": [ "en-US", "hi-IN" ], "LanguageIdSettings": { "en-US" : { "LanguageModelName": "my-en-US-language-model", "VocabularyFilterName": "my-en-US-vocabulary-filter", "VocabularyName": "my-en-US-vocabulary" }, "hi-IN": { "VocabularyName": "my-hi-IN-vocabulary", "VocabularyFilterName": "my-hi-IN-vocabulary-filter" } } }
此範例使用 適用於 Python (Boto3) 的 AWS SDK ,使用 start_transcription_jobIdentifyLanguage 引數來識別檔案的語言。如需詳細資訊,請參閱StartTranscriptionJob及LanguageIdSettings。
如需使用 AWS SDKs的其他範例,包括功能特定、案例和跨服務範例,請參閱 使用 AWS SDKs Amazon Transcribe 程式碼範例章節。
選項 1:沒有 LanguageIdSettings 參數。如果您未在請求中包含自訂語言模型、自訂詞彙或自訂詞彙篩選,請使用此選項。LanguageOptions 為選用操作,但建議您採用。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat = 'flac', IdentifyLanguage =True, (or IdentifyMultipleLanguages =True), LanguageOptions = [ 'en-US', 'hi-IN' ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
選項 2:使用 LanguageIdSettings 參數。如果您要在請求中包含自訂語言模型、自訂詞彙或自訂詞彙篩選,請使用此選項。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat='flac', IdentifyLanguage=True, (or IdentifyMultipleLanguages=True) LanguageOptions = [ 'en-US', 'hi-IN' ], LanguageIdSettings={ 'en-US': { 'VocabularyName': 'my-en-US-vocabulary', 'VocabularyFilterName': 'my-en-US-vocabulary-filter', 'LanguageModelName': 'my-en-US-language-model' }, 'hi-IN': { 'VocabularyName': 'my-hi-IN-vocabulary', 'VocabularyFilterName': 'my-hi-IN-vocabulary-filter' } } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
