REL12-BP04 使用混沌工程測試彈性
定期在位於或盡可能鄰近生產環境的環境中執行混沌試驗,以了解您的系統因應不良狀況的能力。
預期成果:
除了以彈性測試驗證您的工作負載在某事件期間的已知預期行為以外,還可以藉由在故障注入試驗中套用混沌工程或注入非預期的負載,來定期驗證工作負載的彈性。結合混沌工程與彈性測試,您將可確信工作負載在經歷元件失敗後仍可存留,並且可在 (幾乎) 不受影響的情況下從非預期的中斷復原。
常見的反模式:
-
針對彈性進行設計,但未確認工作負載在錯誤發生時的整體運作情形。
-
未曾在真實的情況和預期的負載下試驗。
-
未將試驗視為程式碼或透過開發週期加以維護。
-
未在 CI/CD 管道中與部署以外執行混沌試驗。
-
在決定要以哪些錯誤進行試驗時,未使用過去的事故後分析。
建立此最佳實務的優勢:注入錯誤以驗證工作負載的彈性,可讓您確信在發生真正的錯誤時,彈性設計的復原程序將可發揮作用。
未建立此最佳實務時的曝險等級:中
實作指引
混沌工程可讓您的團隊有能力以受控的方式,持續在服務供應商、基礎架構、工作負載和元件層級注入真實的中斷 (模擬),且對客戶 (幾乎) 不會造成影響。它可讓您的團隊從錯誤中學習,並且觀察、測量及改善工作負載的彈性,以及驗證在事件發生時會引發提醒,且團隊會收到通知。
持續執行時,混沌工程可能會凸顯您工作負載中的缺陷,且若未解決,可能會對可用性與操作產生負面影響。
注意
混沌工程是在系統中進行試驗的專業領域,旨在建立對系統承受生產環境中紊亂情況的能力的信心。– 混沌工程的原則
如果系統能夠承受這些中斷,則應將混沌試驗視為自動化迴歸測試來維護。此時,您應在系統開發生命週期 (SDLC) 和 CI/CD 管道中執行混沌試驗。
若要確定您的工作負載可以承受元件失敗,請在試驗中注入真實事件。例如,進行遺失 Amazon EC2 執行個體或容錯移轉主要 Amazon RDS 資料庫執行個體的試驗,並驗證您的工作負載未受影響 (或僅受到些微影響)。使用元件錯誤的組合,模擬可用區域的中斷可能導致的事件。
對於應用程式層級的錯誤 (例如當機),您可以從記憶體和 CPU 用盡之類的壓力源開始著手。
為了驗證由於間歇性網路中斷導致的外部相依性的備用或容錯移轉機制
其他降級模式可能會導致功能降低和回應速度緩慢,而往往會導致服務中斷。這種降級的常見原因是關鍵服務的延遲增加和不可靠的網路通訊 (丟包)。以這些錯誤 (包括延遲、已捨棄訊息和 DNS 失敗等聯網影響) 進行的試驗,可包含無法解析名稱、無法連線到 DNS 服務,或無法建立相依服務的連線等情境。
混沌工程工具:
AWS Fault Injection Service (AWS FIS) 是用來執行故障注入試驗的全受管服務,這些試驗可作為 CD 管道的一部分,或未於管道以外。AWS FIS 很適合在混沌工程演練日期間使用。它支援跨不同類型的資源同時引入故障,包括 Amazon EC2、Amazon Elastic Container Service (Amazon ECS)、Amazon Elastic Kubernetes Service (Amazon EKS) 和 Amazon RDS。這些錯誤包括終止資源、強制執行容錯移轉、施壓於 CPU 或記憶體、限流,以及封包遺失。由於它與 Amazon CloudWatch 警示整合,因此您可以將停止條件設定為防護機制,以在試驗導致非預期的影響時將其回復。
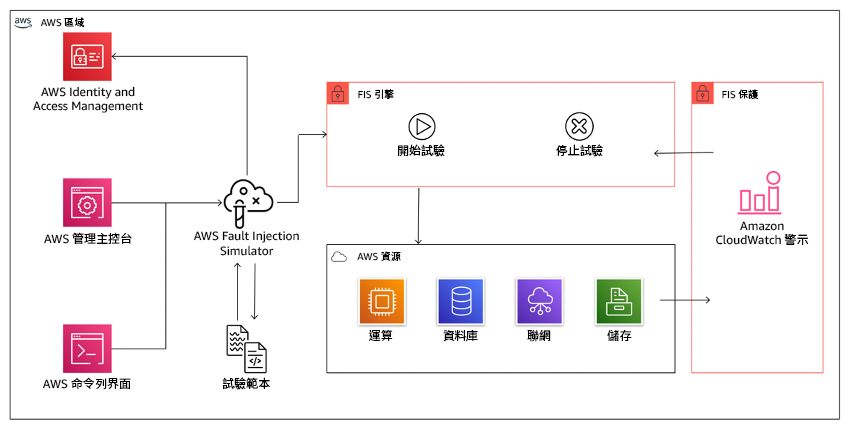
AWS Fault Injection Service 與 AWS 資源整合,讓您可對工作負載執行故障注入試驗。
故障注入試驗也有數個第三方選項。其中包括開放原始碼工具,例如 Chaos Toolkit
實作步驟
-
決定要將哪些錯誤用於試驗。
評估您的工作負載設計是否有彈性。這類設計 (使用 Well-Architected Framework 的最佳實務建立) 會根據關鍵相依性、過去的事件、已知問題和合規性要求來考量風險。列出要用來維護彈性的每個設計元素,及其依設計要減輕的錯誤。如需有關建立此類清單的詳細資訊,請參閱 Operational Readiness Review 白皮書,指導您如何建立程序以防止先前事件再次發生。Failure Modes and Effects Analysis (FMEA) 程序提供了相關架構,讓您執行失敗的元件層級分析,並說明失敗對於工作負載有何影響。Adrian Cockcroft 在 Failure Modes and Continuous Resilience
中詳盡地闡述了 FMEA。 -
指派每個錯誤的優先順序。
請從粗略的分類開始著手,例如高、中或低。若要評估優先順序,請考量錯誤的頻率,以及失敗對整體工作負載的影響。
考量特定錯誤的頻率時,請分析此工作負載過去的資料 (如果可用)。如果無法使用,請使用在類似環境中執行的其他工作負載所包含的資料。
考量特定錯誤的影響時,錯誤的範圍愈大,通常影響就愈大。另請考量工作負載的設計和用途。例如,對執行資料轉換和分析的工作負載而言,存取來源資料存放區的能力至關重要。在此情況下,您應優先執行存取錯誤以及限流存取和延遲注入的試驗。
事故後分析是您了解失敗模式的頻率與影響的理想資料來源。
請使用指派的優先順序,決定要先以哪些錯誤進行試驗,以及要以何種順序開發新的故障注入試驗。
-
對於您所執行的每個試驗,均應依循下圖中的混沌工程和連續彈性飛輪操作。
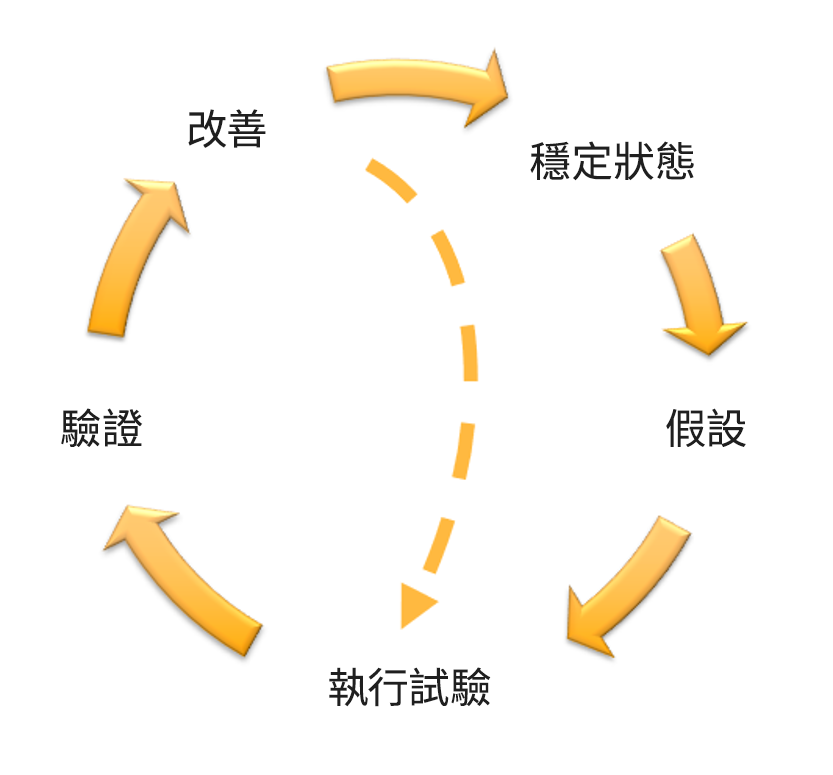
混沌工程和連續彈性飛輪,採用 Adrian Hornsby 的科學方法。
-
將穩定狀態定義為顯示出正常行為之工作負載的某種可測量輸出。
工作負載的運作若可靠且符合預期,就會呈現穩定狀態。因此,在定義穩定狀態前,請先驗證工作負載的運作狀態良好。穩定狀態不一定表示在錯誤發生時完全不會影響到工作負載,因為有特定百分比的錯誤可能會在可接受的限制內。穩定狀態是您在試驗期間將觀察到的基準,如果您在下一步定義的假設未符合預期,就會凸顯異常。
例如,支付系統的穩定狀態可定義為 300 TPS、成功率 99%、且來回時間為 500 毫秒的處理。
-
形成關於工作負載將如何回應錯誤的假設。
良好的假設奠基於工作負載應如何減輕錯誤以維護穩定狀態。假設指出,在發生特定類型的錯誤時,系統或工作負載將持續保有穩定狀態,因為工作負載設有特定緩解機制。特定類型的錯誤和緩解機制應指定於假設中。
以下是可用於假設的範本 (但也接受其他措辭):
注意
如果發生
特定錯誤,工作負載名稱工作負載將描述緩解控制措施,以維持業務或技術指標的影響。例如:
-
若 Amazon EKS 節點群組中有 20% 的節點遭到關閉,Transaction Create API 會在 100 毫秒以內繼續提供第 99 個百分位數的請求 (穩定狀態)。Amazon EKS 節點將在五分鐘內復原,而 Pod 將在試驗起始後的八分鐘內進入排程並處理流量。提醒將在三分鐘內引發。
-
單一 Amazon EC2 執行個體失敗發生時,訂單系統的 Elastic Load Balancing 運作狀態檢查將使 Elastic Load Balancing 僅將請求傳送至其餘運作狀態良好的執行個體,而 Amazon EC2 Auto Scaling 會取代失敗的執行個體,將伺服器端 (5xx) 錯誤的增量維持在 0.01% 以內 (穩定狀態)。
-
主要 Amazon RDS 資料庫執行個體失敗時,供應鏈資料收集工作負載將進行容錯移轉並連線至待命 Amazon RDS 資料庫執行個體,以維持不到 1 分鐘的資料庫讀取或寫入錯誤 (穩定狀態)。
-
-
藉由注入錯誤來執行試驗。
試驗依預設應處於安全模式,並獲得工作負載的容許。如果您確知工作負載將失敗,請不要執行試驗。混沌工程應該用來尋找已知的未知或未知的未知。已知的未知是您知道但不完全理解的事情,未知的未知是您不知道也不完全理解的事情。對您確知已失效的工作負載執行試驗,將不會為您帶來新的見解。試驗應經過審慎規劃、具有明確的影響範圍,並且提供在非預期的錯亂發生時可供套用的回復機制。如果您的盡職調查顯示工作負載應可承受試驗,請繼續執行試驗。有數種選項可用來注入錯誤。對於 AWS 上的工作負載,AWS FIS 提供許多預先定義的錯誤模擬,稱為動作。您也可以定義在 AWS FIS 中執行的自訂動作 (使用 AWS Systems Manager 文件)。
我們不鼓勵使用自訂指令碼來執行混沌試驗,除非指令碼有能力理解工作負載目前的狀態、能夠發出日誌,並且提供回復機制和停止條件 (若情況允許)。
支援混沌工程的有效架構或工具集,應追蹤試驗目前的狀態、發出日誌,並提供回復機制以支援受控制的試驗執行。請先從 AWS FIS 這類已建立的服務著手,以便能以明確定義的範圍執行試驗,並且有安全機制可在試驗導入非預期的錯亂時回復試驗。要了解更多有關使用 AWS FIS 的實驗,請參閱 Resilient and Well-Architected Apps with Chaos Engineering lab
。此外,AWS Resilience Hub 會分析您的工作負載,並建立可供您選擇在 AWS FIS 中實作並執行的試驗。 注意
對於每一項試驗,您都應明確了解其範圍與影響。我們建議,錯誤應先在非生產環境中模擬,再於生產環境中執行。
在可行的情況下,實驗應該使用 Canary 部署
在實際負載下在生產環境中執行,這可加速控制和實驗系統部署。在非尖峰時段執行試驗是很好的做法,可以減少首次在生產環境中試驗時的潛在影響。此外,如果使用實際的客戶流量會伴隨太高的風險,您可以對控制和試驗部署使用生產基礎架構上的綜合流量,來執行試驗。無法使用生產環境時,請在盡可能接近生產環境的生產前環境中執行試驗。 您必須建立防護機制並加以監控,以確定試驗不會超出可接受的限制而影響到生產流量或其他系統。請建立停止條件,以在試驗達到您定義的防護機制指標閾值時,將試驗停止。其中應包括工作負載的穩定狀態指標,以及您對其注入錯誤的元件所適用的指標。綜合監測 (也稱為使用者 Canary),是您在一般情況下應納入作為使用者代理的指標之一。AWS FIS 的停止條件被視為試驗範本的一部分受到支援,每個範本最多可啟用五個停止條件。
混沌的準則之一,是盡可能縮小試驗的範圍與影響:
儘管容許某些短期負面影響是必要的,但混沌工程師有責任和義務將試驗的副作用控制在最低限度。
驗證範圍和潛在影響的方法之一,是先在非生產環境中執行試驗,驗證停止條件的閾值在試驗期間會依預期啟動,且有可觀測性會捕捉例外狀況,而不是直接在生產環境中試驗。
執行故障注入試驗時,請驗證所有的責任方都會及時獲得通知。請與營運團隊、服務可靠性團隊和客戶支援等適當的團隊通訊,讓他們知道試驗將於何時執行,且預期會有何情況。請為這些團隊提供通訊工具,以便他們在試驗執行期間發現任何不利影響時發出通知。
您必須將工作負載及其基礎系統還原為原始的已知良好狀態。工作負載的彈性設計通常具有自癒能力。但某些錯誤設計或失敗的試驗可能會使您的工作負載處於非預期的失敗狀態。試驗結束時,您必須察覺到這一點,並還原工作負載和系統。透過 AWS FIS,您可以在動作參數內設定回復組態 (也稱為後置動作)。後置動作會將目標回復為動作執行前原有的狀態。無論是自動 (例如使用 AWS FIS) 還是手動,這些後續動作皆應為程序手冊的一部分,以說明如何偵測及處理失敗。
-
驗證假設。
混沌工程的原則
提供了下列關於如何驗證工作負載穩定狀態的指引: 著重於可測量的系統輸出,而不是系統的內部屬性。這類輸出在一段時間內的測量,會構成系統穩定狀態的代理。整體系統的輸送量、錯誤率和延遲百分位數,全都可能成為呈現穩定狀態行為的相關指標。著重於試驗期間的系統行為模式,混沌工程會驗證系統是否可運作,而非試著驗證其運作情形。
在先前的兩個範例中,我們納入了伺服器端 (5xx) 錯誤的增量低於 0.01% 的穩定狀態指標,以及資料庫讀取和寫入錯誤不到一分鐘的穩定狀態指標。
5xx 錯誤是工作負載的用戶端在失敗模式下將直接經歷的結果,因此可說是良好的指標。資料庫錯誤測量是錯誤的直接產物,因此有其效用,但應同時輔以用戶端影響測量,例如失敗的客戶請求或用戶端遇到的錯誤。此外,請在工作負載的用戶端直接存取的任何 API 或 URI 納入綜合監控 (也稱為使用者 Canary)。
-
改善工作負載設計的彈性。
如果未維持穩定狀態,請採用 AWS Well-Architected 可靠性支柱的最佳實務,調查如何改進工作負載設計來緩解故障。可以在 AWS 建置者資料中心
中找到其他指引和資源,其中包含有關如何改善運作狀態檢查 或在應用程式碼中透過輪詢進行重試 等文章。 這些變更實作完成後,請再次執行試驗 (在混沌工程飛輪中以虛線表示) 以判斷其有效性。若驗證步驟指出假設成立,則工作負載將處於穩定狀態,且週期會繼續。
-
-
請定期執行試驗。
混沌試驗是一個週期,而試驗應被視為混沌工程的一部分定期執行。當工作負載符合試驗的假設後,即應將試驗自動化,以將其視為 CI/CD 管道的迴歸部分持續執行。要了解如何執行此操作,請參閱有關如何使用 AWS CodePipeline 執行 AWS FIS 實驗
的部落格。這個關於 CI/CD 管道中的經常性 AWS FIS 實驗 的實驗室可讓您親手操作。 故障注入試驗也是演練日的一部分 (請參閱 REL12-BP05 定期進行演練日)。演練日會模擬失敗或事件,以驗證系統、程序和團隊的應變。目的是實際執行在異常事件發生時團隊將要執行的動作。
-
擷取並儲存試驗結果。
故障注入試驗的結果必須擷取並保存。請納入所有必要資料 (例如時間、工作負載和條件),以便後續能分析試驗結果和趨勢。舉例來說,結果可包括儀表板的螢幕擷取畫面、指標的資料庫產生的 CSV 傾印,或是試驗中的事件與觀察的手寫記錄。使用 AWS FIS 試驗日誌記錄可以是此資料擷取的一部分。
資源
相關的最佳實務:
相關文件:
相關影片:
相關工具:
-
AWS Marketplace:Gremlin 混沌工程平台
