This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Machine learning pipelines
Despite many companies going all in on ML, hiring massive teams of
highly compensated data scientists, and devoting huge amounts of
financial and other resources, their projects end up
failing
at high rates
Moving from a single laptop setup toward a scalable, production-grade, data science platform is a completely different challenge from the proof-of-concept stage, and arguably, one of the most difficult, as it involves collaborating with different teams across an organization. Accenture has devised a scalable and unique approach for the Accenture talent and skilling AI solutions discussed in this whitepaper, to go from prototype to full-scale productionized systems in a very short period of time; enhancing “speed to market” and generating value.
ML technical debt may rapidly accumulate. Without strict enforcement
of ML engineering principles (built on rigorous software engineering
principles) to data science code may result in a messy pipeline, and
managing these pipelines – detecting errors and recovering from
failures – becomes extremely difficult and costly. Comprehensive
live monitoring of system behavior in near real time, combined with
automated response, is critical for
long-term
system reliability
This and the following sections address these problems, and provide a solution.
Going from POC to large-scale deployments
The main challenges for companies looking to move beyond the realm of basic AI proof of concepts (POCs), manual data science POCs, and pilot programs to Enterprise AI, can be grouped around the need to achieve the following at Enterprise level:
-
Repeatability
-
Scalability
-
Transparency/Explainability
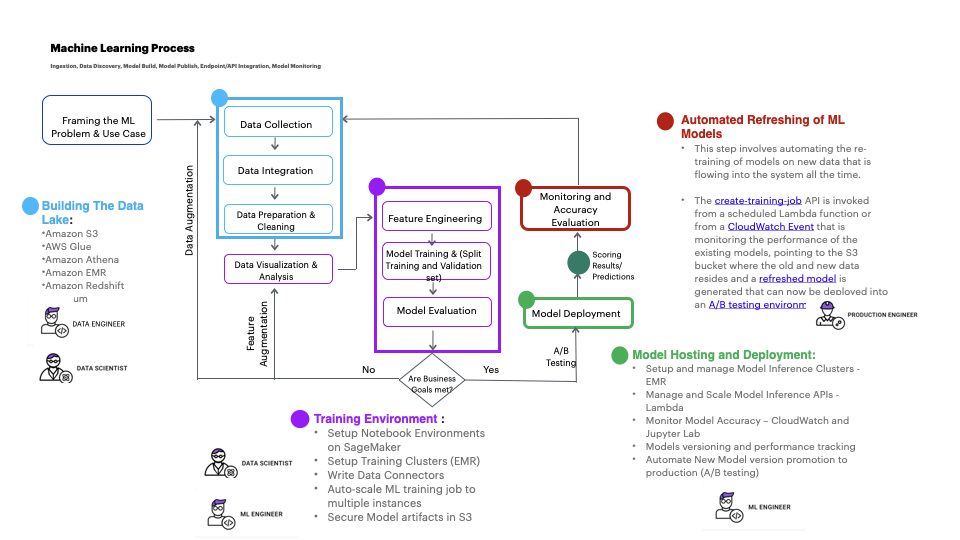
ML workflow and process with multiple teams that need to collaborate to create a complete ML solution in production
Applying software engineering principles to data science
The single biggest driving factor in making a successful project that has the fewest amount of rework is that of collaborative involvement between the ML team and the business unit. The second biggest factor to ensure success is communication within the ML teams.
Decades ago, software engineers refined their processes from large-scale waterfall implementations to a more flexible agile process. That was a game-changer in terms of bringing ideas to market faster and more efficiently. Similarly, now ML engineering seeks to define a new set of practices and tools that will optimize the whole unique realm of software development for data analysts and scientists.
The idea of ML engineering and MLOps as a paradigm is rooted in the application of similar principles that DevOps has to software development.
Machine learning automation through pipelines
For the Accenture workforce productivity and talent and skilling use cases listed in this whitepaper, you see that automated, repeatable, reproducible, parametrized data engineering and ML engineering pipelines help to track model runs, lineage, versions, and timings across all the stages, from data ingestion to feature engineering to model training and post-deployment.
Automated ML pipelines ensure one vital feature and requirement of a stable live enterprise AI platform: repeatability and reproducibility. Instead of manual ad-hoc Python scripts that may propagate data quality issues from sources, pipelines help ensure the issues are caught, handled, retried, or logged at every step of the pipeline.
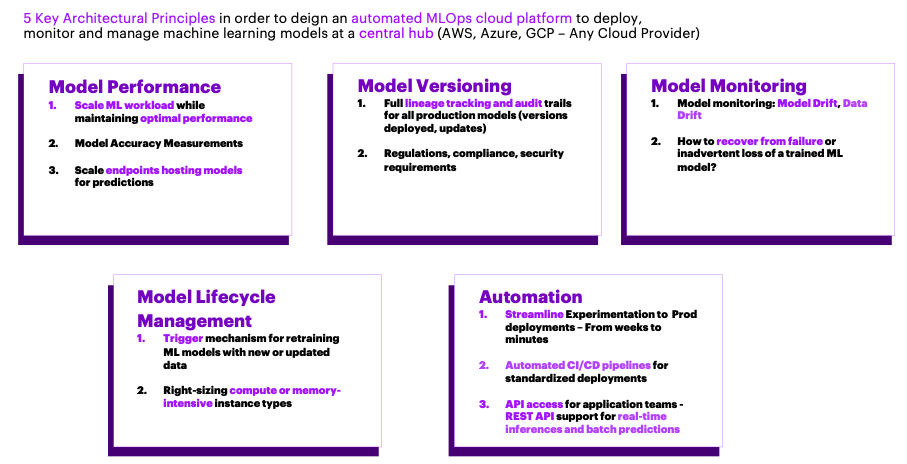
The design principles for a functioning MLOps platform
Implementing these design principles, the following diagram summarizes a modern and effective way to implement pipelines on AWS. This section describes the key ML processes, and the stages for creating a modern and performant ML pipeline on AWS.

The ML engineering process and steps to create modern and effective ML pipelines on AWS
Tracking lineage
Model artifact lineage should be recorded and tracked at every stage. This is the only way you can tie back the model to the dataset it was trained on, the features used, the validation dataset used, and the approval process and deployment history. For tracking and looking at the lineage artifacts for our processing job, you can do the following in SageMaker AI, and the same should be set up as part of the pipeline artifact lineage.
SageMaker AI Lineage Tracking API has lineage traversal, contexts, and associations among other concepts that help in creating a lineage history for all stages of SageMaker AI Pipelines, training jobs, endpoints, SageMaker AI processing jobs, and models, as shown in the following image. Lineage of feature engineering jobs can and should be tracked in the same way. Amazon SageMaker AI ML Lineage Tracking helps in storing information about all the stages of a ML workflow from data preparation to model deployment.
Tracking model lineage and pipeline lineage with Amazon SageMaker AI
