本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
測量可用性
正如我們之前所看到的,為分散式系統建立前瞻性的可用性模型很難做到,而且可能無法提供所需的見解。可以提供更多實用性的是開發一致的方法來衡量工作負載的可用性。
將可用性定義為正常運行時間和停機時間將失敗表示為二進制選項,無論是工作負載已啟動還是不是。
但是,這種情況很少是這種情況。失敗會有一定程度的影響,而且通常在工作負載的某些子集中經歷,這會影響一定百分比的使用者或要求、位置百分比或延遲百分位數。這些都是部分故障模式。
雖然 MTTR 和 MTBF 對於了解驅動系統產生的可用性的原因很有用,因此,如何改進它,但它們的效用並不是作為可用性的實證衡量標準。此外,工作負載由許多元件組成。例如,像付款處理系統這樣的工作負載由許多應用程式設計介面 (API) 和子系統組成。因此,當我們想要問一個問題時,「整個工作負載的可用性是多少?」 ,這實際上是一個複雜而細微的問題。
在本節中,我們將研究以實證方式衡量可用性的三種方式:伺服器端要求成功率、用戶端要求成功率和年度停機時間。
伺服器端和用戶端要求成功率
前兩種方法非常相似,只有與測量的角度不同。您可以從服務中的檢測收集伺服器端度量。但是,它們還不完整。如果用戶端無法連線到服務,您就無法收集這些指標。為了瞭解用戶端體驗,而不是仰賴來自用戶端有關失敗要求的遙測,收集用戶端指標的更簡單方法是使用 Canaries 模擬客戶流量,而是定期偵測服務並記錄指標的軟體。
這兩種方法會將可用性計算為服務接收的有效工作單位總計,以及成功處理的工作單位 (這會忽略無效的工作單位,例如導致 404 錯誤的 HTTP 要求)。

方程式 8
對於以要求為基礎的服務,工作單位就是要求,就像 HTTP 要求一樣。對於以事件為基礎或以工作為基礎的服務,工作單位是事件或工作,例如從佇列中處理訊息。這種可用性度量在短時間間隔內是有意義的,例如一分鐘或五分鐘的時間。它也最適合在細微的角度,例如在每個 API 級別為基於請求的服務。下圖提供以這種方式計算時,隨時間推移的可用性可能會是什麼樣子的檢視。圖表上的每個資料點都是在五分鐘時段內使用方程式 (8) 計算的 (您可以選擇其他時間維度,例如一分鐘或十分鐘的間隔)。例如,資料點 10 顯示 94.5% 的可用性。這意味著,如果服務收到 1,000 個請求,則在 T+45 到 +50 的分鐘內,只有 945 個請求被成功處理。
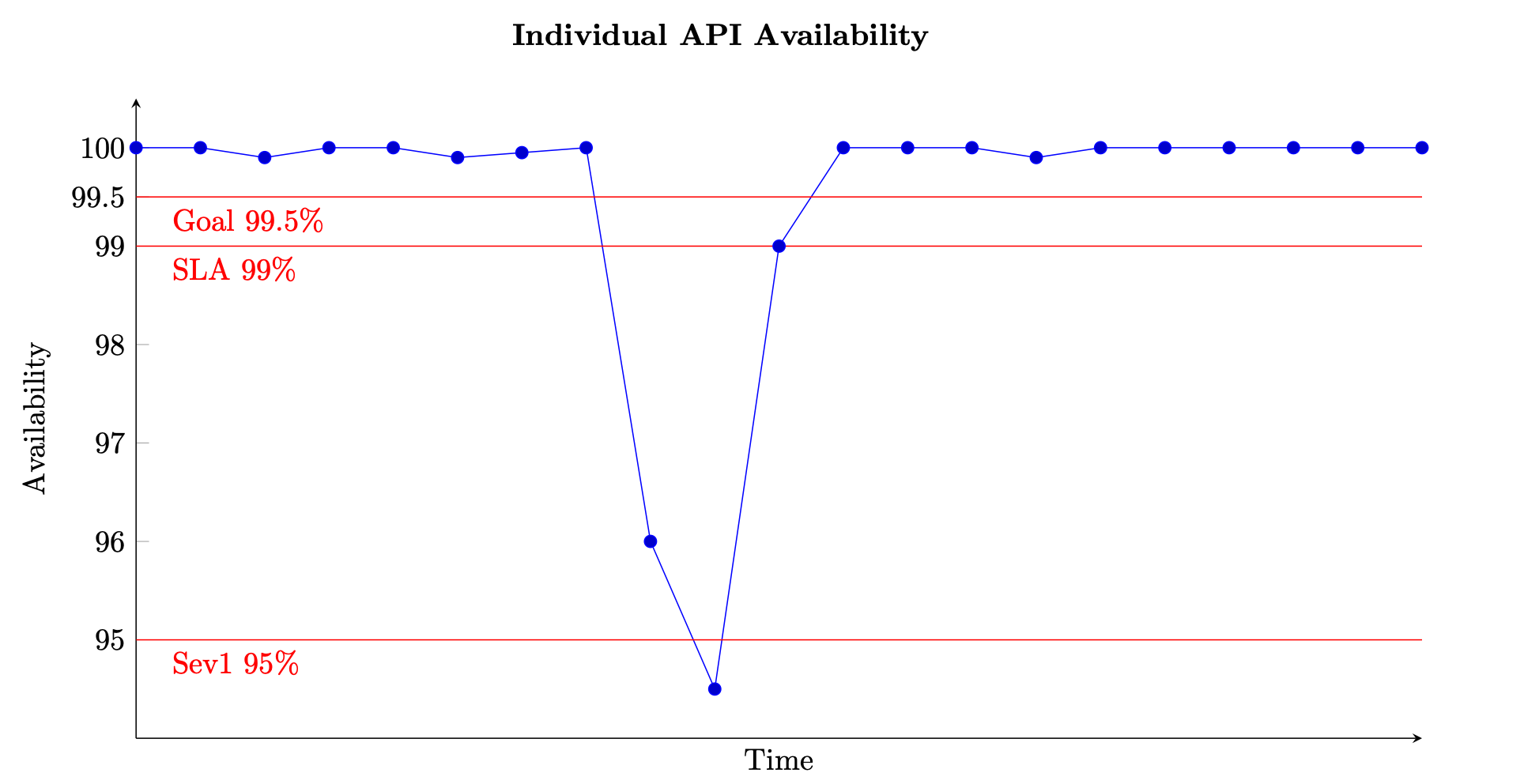
測量單一 API 隨時間變化的可用性範例
此圖表也會顯示 API 的可用性目標、99.5% 可用性、提供給客戶的服務等級協定 (SLA)、99% 的可用性,以及高嚴重性警示的臨界值 95%。如果沒有這些不同臨界值的內容,可用性圖表可能無法提供您服務運作方式的重要見解。
我們也希望能夠追蹤和描述更大型子系統的可用性,例如控制平面或整個服務。其中一種方法是取得每個子系統每五分鐘資料點的平均值。該圖看起來與前一個圖形類似,但將代表一組較大的輸入。它還為構成您的服務的所有子系統提供了相同的權重。另一種方法可能是將從服務中所有 API 接收並成功處理的所有要求加總,以便以五分鐘的間隔計算可用性。
但是,後一種方法可能會隱藏具有低吞吐量和不良可用性的單個 API。作為一個簡單的例子,考慮一個具有兩個 API 的服務。
第一個 API 在五分鐘的時間內收到 1,000,000 個要求,並成功處理其中 999,000 個要求,提供 99.9% 的可用性。第二個 API 會在相同的五分鐘時段內接收 100 個要求,而且只能成功處理其中 50 個要求,提供 50% 的可用性。
如果我們將來自每個 API 的請求加總在一起,則總共有 1,000,100 個有效請求,其中 999,050 個被成功處理,從而為整體服務提供 99.895% 的可用性。但是,如果我們平均兩個 API(前一種方法)的可用性,我們得到 74.95% 的可用性,這可能更多地說明了實際體驗。
這兩種方法都不是錯誤的,但它顯示了了解可用性指標告訴您的重要性。如果您的工作負載在每個子系統上收到類似的請求量,您可能會選擇對所有子系統加總請求。這種方法著重於「請求」及其成功作為可用性和客戶體驗的衡量標準。或者,您也可以選擇平均子系統可用性,以平均代表其重要性,儘管請求數量有所差異。此方法著重於子系統以及每個子系統作為客戶經驗代理的能力。
年度停機時
第三種方法是計算年度停機時間。這種形式的可用性量度比較適合長期目標設定和檢閱。它需要定義停機時間對您的工作負載的意義。然後,您可以根據工作負載不處於「中斷」狀況的分鐘數 (相對於指定期間內的總分鐘數) 來測量可用性。
某些工作負載可能會將停機時間定義為一分鐘或五分鐘的間隔 (發生在先前的可用性圖表中) 的單一 API 或工作負載函數 95% 以下的可用性。您也可能只考慮停機時間,因為它適用於關鍵資料平面作業的子集。例如,適用於 SQS 可用性的 Amazon 簡訊 (SQS、SNS) 服務等級協議
較大、更複雜的工作負載可能需要定義整個系統的可用性指標。對於大型電子商務網站,全系統指標可以類似於客戶訂單率。在這裡,與任何五分鐘期間的預測數量相比,訂單下降 10% 或更多可以定義停機時間。
無論哪種方法,您都可以加總所有中斷期間,以計算年度可用性。例如,如果某個日曆年度有 27 個 5 分鐘的停機時間 (定義為任何資料平面 API 的可用性降至 95% 以下),則整體停機時間為 135 分鐘 (可能是連續五分鐘的期間,其他時間隔離),代表年度可用性為 99.97%。
這種額外的測量可用性方法可提供用戶端和伺服器端度量遺失的資料和洞察力。例如,假設受損且錯誤率大幅提升的工作負載。此工作負載的客戶可能會完全停止呼叫其服務。也許他們已經激活了斷路器,或者按照災難恢復計劃
Latency (延遲)
最後,測量工作負載內工作處理單元的延遲也很重要。可用性定義的一部分是在已建立的 SLA 中執行工作。如果傳回回應所花費的時間超過用戶端逾時,則來自用戶端的看法是要求失敗且工作負載不可用。但是,在伺服器端,請求可能似乎已成功處理。
測量延遲提供另一個用於評估可用性的鏡頭。使用百分位數和修剪均值是此測量的良好統計數據。它們通常在第 50 個百分位數(P50 和 TM50)和第 99 個百分位數(P99 和 TM99)進行測量。延遲應使用 Canaries 來衡量,以代表用戶端體驗以及伺服器端指標。每當某些百分位數延遲的平均值(例如 P99 或 TM99.9)高於目標 SLA 時,您可以考慮停機時間,這有助於計算年度停機時間。
