Elastic Beanstalk worker environments
If your AWS Elastic Beanstalk application performs operations or workflows that take a long time to complete, you can offload those tasks to a dedicated worker environment. Decoupling your web application front end from a process that performs blocking operations is a common way to ensure that your application stays responsive under load.
A long-running task is anything that substantially increases the time it takes to complete a request, such as processing images or videos, sending email, or generating a ZIP archive. These operations can take only a second or two to complete, but a delay of a few seconds is a lot for a web request that would otherwise complete in less than 500 ms.
One option is to spawn a worker process locally, return success, and process the task asynchronously. This works if your instance can keep up with all of the tasks sent to it. Under high load, however, an instance can become overwhelmed with background tasks and become unresponsive to higher priority requests. If individual users can generate multiple tasks, the increase in load might not correspond to an increase in users, making it hard to scale out your web server tier effectively.
To avoid running long-running tasks locally, you can use the AWS SDK for your programming language to send them to an Amazon Simple Queue Service (Amazon SQS) queue, and run the process that performs them on a separate set of instances. You then design these worker instances to take items from the queue only when they have capacity to run them, preventing them from becoming overwhelmed.
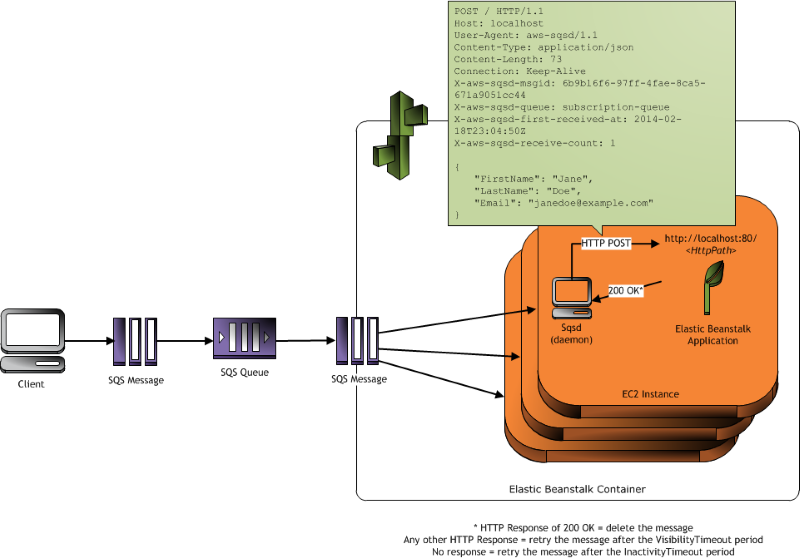
Elastic Beanstalk worker environments simplify this process by managing the Amazon SQS queue and running a daemon process on each instance that reads from the queue for
you. When the daemon pulls an item from the queue, it sends an HTTP POST request locally to
http://localhost/ on port 80 with the contents of the queue message in the body. All that
your application needs to do is perform the long-running task in response to the POST. You can
configure the daemon
to post to a different path, use a MIME type other than application/JSON, connect to an existing
queue, or customize connections (maximum concurrent requests), timeouts, and retries.
With periodic tasks, you can also configure the worker daemon to queue messages based on a cron schedule. Each periodic task can POST to a different path. Enable periodic tasks by including a YAML file in your source code that defines the schedule and path for each task.
Note
The .NET on Windows Server platform doesn't support worker environments.
Sections
The worker environment SQS daemon
Worker environments run a daemon process provided by Elastic Beanstalk. This daemon is updated regularly to add features and fix bugs. To get the latest version of the daemon, update to the latest platform version.
When the application in the worker environment returns a 200 OK response to acknowledge that it has received and successfully processed
the request, the daemon sends a DeleteMessage call to the Amazon SQS queue to delete the message from the queue. If the application
returns any response other than 200 OK, Elastic Beanstalk waits to put the message back in the queue after the configured
ErrorVisibilityTimeout period. If there is no response, Elastic Beanstalk waits to put the message back in the queue after the
InactivityTimeout period so that the message is available for another attempt at processing.
Note
The properties of Amazon SQS queues (message order, at-least-once delivery, and message sampling) can affect how you design a web application for a worker environment. For more information, see Properties of Distributed Queues in the Amazon Simple Queue Service Developer Guide.
Amazon SQS automatically deletes messages that have been in a queue for longer than the configured RetentionPeriod.
The daemon sets the following HTTP headers.
|
HTTP headers |
|
|---|---|
| Name | Value |
|
|
|
|
|
SQS message ID, used to detect message storms (an unusually high number of new messages). |
|
|
Name of the SQS queue. |
|
|
UTC time, in ISO 8601
format |
|
|
SQS message receive count. |
|
|
Custom message attributes assigned to the message being processed. The |
|
|
Mime type configuration; by default, |
Dead-letter queues
Elastic Beanstalk worker environments support Amazon Simple Queue Service (Amazon SQS) dead-letter queues. A dead-letter queue is a queue where other (source) queues can send messages that for some reason could not be successfully processed. A primary benefit of using a dead-letter queue is the ability to sideline and isolate the unsuccessfully processed messages. You can then analyze any messages sent to the dead-letter queue to try to determine why they were not successfully processed.
If you specify an autogenerated Amazon SQS queue at the time you create your worker environment tier, a dead-letter queue is enabled by default for a worker environment. If you choose an existing SQS queue for your worker environment, you must use SQS to configure a dead-letter queue independently. For information about how to use SQS to configure a dead-letter queue, see Using Amazon SQS Dead Letter Queues.
You cannot disable dead-letter queues. Messages that cannot be delivered are always eventually sent to a dead-letter queue. You can, however,
effectively disable this feature by setting the MaxRetries option to the maximum valid value of 100.
If a dead-letter queue isn't configured for your worker environment's Amazon SQS queue, Amazon SQS keeps messages on the queue until the retention period expires. For details about configuring the retention period, see Configuring worker environments.
Note
The Elastic Beanstalk MaxRetries option is equivalent to the SQS MaxReceiveCount option. If your worker environment doesn't use an
autogenerated SQS queue, use the MaxReceiveCount option in SQS to effectively disable your dead-letter queue. For more information, see
Using Amazon SQS Dead Letter Queues.
For more information about the lifecycle of an SQS message, go to Message Lifecycle.
Periodic tasks
You can define periodic tasks in a file named cron.yaml in your
source bundle to add jobs to your worker environment's queue automatically at a regular
interval.
For example, the following cron.yaml file creates two periodic tasks. The first one runs every 12 hours and the second one runs at 11 PM
UTC every day.
Example cron.yaml
version: 1
cron:
- name: "backup-job"
url: "/backup"
schedule: "0 */12 * * *"
- name: "audit"
url: "/audit"
schedule: "0 23 * * *"The name must be unique for each task. The URL is the path to which
the POST request is sent to trigger the job. The schedule is a CRON expression
When a task runs, the daemon posts a message to the environment's SQS queue with a header indicating the job that needs to be performed. Any instance in the environment can pick up the message and process the job.
Note
If you configure your worker environment with an existing SQS queue and choose an Amazon SQS FIFO queue, periodic tasks aren't supported.
Elastic Beanstalk uses leader election to determine which instance in your worker environment queues the periodic task. Each instance attempts to become leader by writing to an Amazon DynamoDB table. The first instance that succeeds is the leader, and must continue to write to the table to maintain leader status. If the leader goes out of service, another instance quickly takes its place.
For periodic tasks, the worker daemon sets the following additional headers.
|
HTTP headers |
|
|---|---|
| Name | Value |
|
|
For periodic tasks, the name of the task to perform. |
|
|
Time at which the periodic task was scheduled |
|
|
AWS account number of the sender of the message |
Use Amazon CloudWatch for automatic scaling in worker environment tiers
Together, Amazon EC2 Auto Scaling and CloudWatch monitor the CPU utilization of the running instances in the worker environment. How you configure the automatic scaling limit for CPU capacity determines how many instances the Auto Scaling group runs to appropriately manage the throughput of messages in the Amazon SQS queue. Each EC2 instance publishes its CPU utilization metrics to CloudWatch. Amazon EC2 Auto Scaling retrieves from CloudWatch the average CPU usage across all instances in the worker environment. You configure the upper and lower threshold as well as how many instances to add or terminate according to CPU capacity. When Amazon EC2 Auto Scaling detects that you have reached the specified upper threshold on CPU capacity, Elastic Beanstalk creates new instances in the worker environment. The instances are deleted when the CPU load drops back below the threshold.
Note
Messages that have not been processed at the time an instance is terminated are returned to the queue where they can be processed by another daemon on an instance that is still running.
You can also set other CloudWatch alarms, as needed, by using the Elastic Beanstalk console, CLI, or the options file. For more information, see Using Elastic Beanstalk with Amazon CloudWatch and Create an Auto Scaling group with Step Scaling Policies.
Configuring worker environments
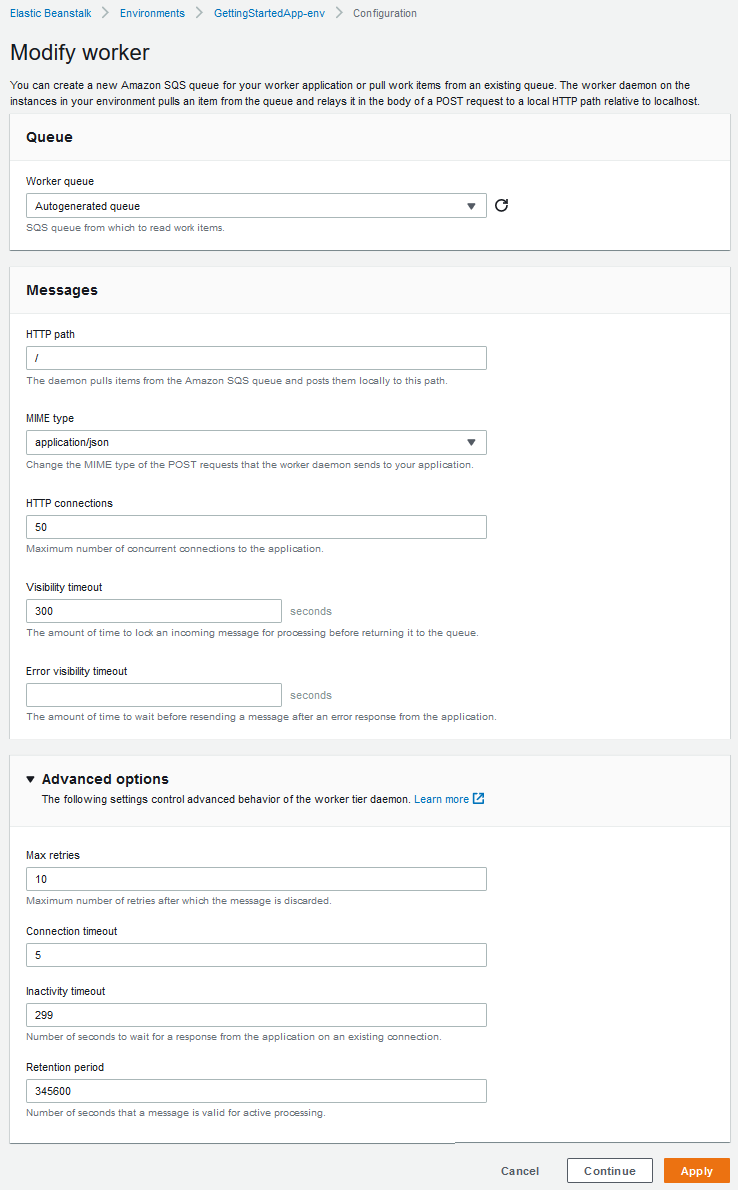
You can manage a worker environment's configuration by editing the Worker category on the Configuration page in the environment management console.
Note
You can configure the URL path for posting worker queue messages, but you can't configure the IP port. Elastic Beanstalk always posts worker queue messages on port 80. The worker environment application or its proxy must listen to port 80.
To configure the worker daemon
Open the Elastic Beanstalk console
, and in the Regions list, select your AWS Region. -
In the navigation pane, choose Environments, and then choose the name of your environment from the list.
In the navigation pane, choose Configuration.
-
In the Worker configuration category, choose Edit.
The Modify worker configuration page has the following options.
In the Queue section:
-
Worker queue – Specify the Amazon SQS queue from which the daemon reads. If you have one, you can choose an existing queue. If you choose Autogenerated queue, Elastic Beanstalk creates a new Amazon SQS queue and a corresponding Worker queue URL.
Note
When you choose Autogenerated queue, the queue that Elastic Beanstalk creates is a standard Amazon SQS queue. When you choose an existing queue, you can provide either a standard or a FIFO Amazon SQS queue. Be aware that if you provide a FIFO queue, periodic tasks aren't supported.
-
Worker queue URL – If you choose an existing Worker queue, this setting displays the URL associated with that Amazon SQS queue.
In the Messages section:
-
HTTP path – Specify the relative path to the application that will receive the data from the Amazon SQS queue. The data is inserted into the message body of an HTTP POST message. The default value is
/. -
MIME type – Indicate the MIME type that the HTTP POST message uses. The default value is
application/json. However, any value is valid because you can create and then specify your own MIME type. -
HTTP connections – Specify the maximum number of concurrent connections that the daemon can make to any application within an Amazon EC2 instance. The default is
50. You can specify1to100. -
Visibility timeout – Indicate the amount of time, in seconds, an incoming message from the Amazon SQS queue is locked for processing. After the configured amount of time has passed, the message is again made visible in the queue for another daemon to read. Choose a value that is longer than you expect your application requires to process messages, up to
43200seconds. -
Error visibility timeout – Indicate the amount of time, in seconds, that elapses before Elastic Beanstalk returns a message to the Amazon SQS queue after an attempt to process it fails with an explicit error. You can specify
0to43200seconds.
In the Advanced options section:
-
Max retries – Specify the maximum number of times Elastic Beanstalk attempts to send the message to the Amazon SQS queue before moving the message to the dead-letter queue. The default value is
10. You can specify1to100.Note
The Max retries option only applies to Amazon SQS queues that are configured with a dead-letter queue. For any Amazon SQS queues that aren't configured with a dead-letter queue, Amazon SQS retains messages in the queue and processes them until the period specified by the Retention period option expires.
-
Connection timeout – Indicate the amount of time, in seconds, to wait for successful connections to an application. The default value is
5. You can specify1to60seconds. -
Inactivity timeout – Indicate the amount of time, in seconds, to wait for a response on an existing connection to an application. The default value is
180. You can specify1to36000seconds. -
Retention period – Indicate the amount of time, in seconds, a message is valid and is actively processed. The default value is
345600. You can specify60to1209600seconds.
If you use an existing Amazon SQS queue, the settings that you configure when you create a worker environment can conflict with settings you configured
directly in Amazon SQS. For example, if you configure a worker environment with a RetentionPeriod value that is higher than the
MessageRetentionPeriod value you set in Amazon SQS, Amazon SQS deletes the message when it exceeds the MessageRetentionPeriod.
Conversely, if the RetentionPeriod value you configure in the worker environment settings is lower than the
MessageRetentionPeriod value you set in Amazon SQS, the daemon deletes the message before Amazon SQS can. For VisibilityTimeout, the
value that you configure for the daemon in the worker environment settings overrides the Amazon SQS VisibilityTimeout setting. Ensure that
messages are deleted appropriately by comparing your Elastic Beanstalk settings to your Amazon SQS settings.
