HBase on Amazon S3 (Amazon S3 storage mode)
When you run HBase on Amazon EMR version 5.2.0 or later, you can enable HBase on Amazon S3, which offers the following advantages:
The HBase root directory is stored in Amazon S3, including HBase store files and table metadata. This data is persistent outside of the cluster, available across Amazon EC2 Availability Zones, and you don't need to recover using snapshots or other methods.
With store files in Amazon S3, you can size your Amazon EMR cluster for your compute requirements instead of data requirements, with 3x replication in HDFS.
Using Amazon EMR version 5.7.0 or later, you can set up a read-replica cluster, which allows you to maintain read-only copies of data in Amazon S3. You can access the data from the read-replica cluster to perform read operations simultaneously, and in the event that the primary cluster becomes unavailable.
In Amazon EMR version 6.2.0 to 7.3.0, persistent HFile Tracking uses a HBase system table called
hbase:storefileto directly track the HFile paths used for read operations. This feature is enabled by default and does not require manual migration to be performed. In versions higher than 7.3.0, HFile paths are tracked using a file tracker, storing HFile paths directly in a meta file, within the store directory.
Note
Users that are using a version of Amazon EMR before 7.4.0 and are migrating to EMR-7.4.0 and later, see Migrating from previous HBase versions and follow the upgrade documentation available to ensure a smooth transition.
The following illustration shows the HBase components relevant to HBase on Amazon S3.
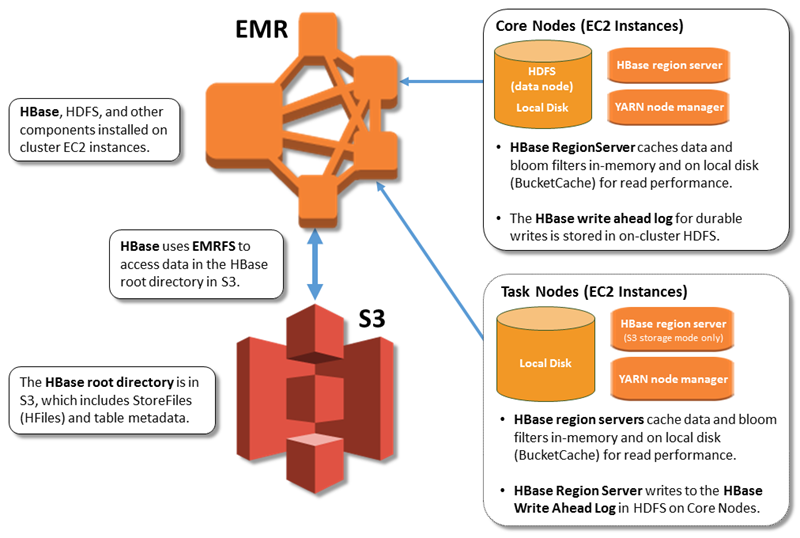
Enabling HBase on Amazon S3
You can enable HBase on Amazon S3 using the Amazon EMR console, the AWS CLI, or the Amazon EMR API. The
configuration is an option during cluster creation. When you use the console, you
choose the setting using Advanced options. When you use the
AWS CLI, use the --configurations option to provide a JSON configuration
object. Properties of the configuration object specify the storage mode and the root
directory location in Amazon S3. The Amazon S3 location that you specify should be in the same
region as your Amazon EMR cluster. Only one active cluster at a time can use the same
HBase root directory in Amazon S3. For console steps and a detailed create-cluster
example using the AWS CLI, see Creating a cluster with HBase. An example configuration object is shown in
the following JSON snippet.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
Note
If you use an Amazon S3 bucket as the rootdir for HBase, you must add a slash at the end of the Amazon S3 URI. For example, you must use "hbase.rootdir: s3://amzn-s3-demo-bucket/", instead of "hbase.rootdir: s3://amzn-s3-demo-bucket", to avoid issues.
Using a read-replica cluster
After you set up a primary cluster using HBase on Amazon S3, you can create and configure a read-replica cluster that provides read-only access to the same data as the primary cluster. This is useful when you need simultaneous access to query data or uninterrupted access if the primary cluster becomes unavailable. The read-replica feature is available with Amazon EMR version 5.7.0 and later.
The primary cluster and the read-replica cluster are set up the same way with one important difference. Both point to the same hbase.rootdir location. However, the hbase classification for the read-replica cluster includes the "hbase.emr.readreplica.enabled":"true" property.
The read-replica cluster is designed for read-only operations, and no manual compaction or write actions should be performed on it. For Amazon EMR versions earlier than 7.4.0, it's recommended to disable compaction on the read-replica cluster when you enable the read-replica feature. This precaution is necessary because, with the persistent HFile tracking feature enabled on the primary cluster, it's possible for the read-replica cluster to compact system tables, potentially causing a FileNotFoundException on the primary cluster. Disabling compaction on the read-replica cluster prevents data inconsistencies between the primary and read-replica clusters.
For example, given the JSON classification for the primary cluster as shown earlier in the topic, the configuration for a read-replica cluster for EMR versions earlier than 7.4.0 is as follows:
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
For Amazon EMR versions later than 7.3.0, we now use the Store File Tracking feature, hence there is no need to disable compactions.
Synchronizing the read replica when you add data
Because the read-replica uses HBase StoreFiles and metadata that the primary cluster writes to Amazon S3, the read-replica is only as current as the Amazon S3 data store. The following guidance can help minimize the lag time between the primary cluster and the read-replica when you write data.
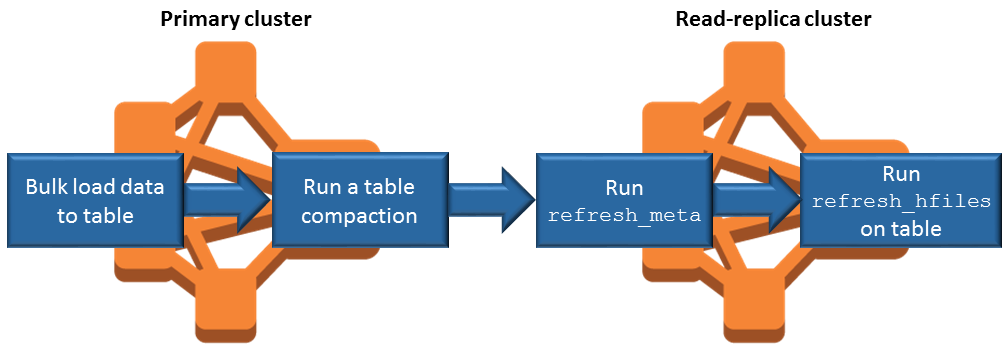
Bulk load data on the primary cluster whenever possible. For more information, see Bulk loading
in Apache HBase documentation. A flush that writes store files to Amazon S3 should occur as soon as possible after data is added. Either flush manually or tune flush settings to minimize lag time.
If compactions might run automatically, run a manual compaction to avoid inconsistencies when compactions are triggered.
On the read-replica cluster, when any metadata has changed - for example, when HBase region split or compactions occur, or when tables are added or removed - run the
refresh_metacommand.On the read-replica cluster, run the
refresh_hfilescommand when records are added to or changed in a table.
Persistent HFile tracking
Persistent HFile tracking uses a HBase system table called hbase:storefile to directly track the HFile paths used for read operations. New HFile paths are added to the table as additional data is added to HBase. This removes rename operations as a commit mechanism in the critical write path HBase operations and improves recovery time when opening a HBase region by reading from the hbase:storefile system table instead of filesystem directory listing.
This feature is enabled by default on Amazon EMR version 6.2.0 to 7.3.0 and does not require any manual migration steps.
Note
Persistent HFile tracking using the HBase storefile system table does not support the HBase region replication feature. For more information about HBase region replication, see Timeline-consistent high available reads
Disabling Persistent HFile Tracking
Persistent HFile tracking is enabled by default starting with Amazon EMR release 6.2.0. To disable persistent HFile tracking, specify the following configuration override when launching a cluster:
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
Note
When reconfiguring the Amazon EMR cluster, all instance groups must be updated.
Manually Syncing the Storefile Table
The storefile table is kept up to date as new HFile instances are created. However, if the storefile table becomes out of sync with the data files for any reason, the commands that follow can be used to manually sync the data:
Sync storefile table in an online region:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
Sync storefile table in an offline region:
Remove the storefile table znode.
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]Assign the region (run in 'hbase shell').
hbase cli> assign '<region name>'If the assignment fails.
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
Scaling the Storefile Table
The storefile table is split into four regions by default. If the storefile table is still under heavy write load, the table can be manually split further.
To split a specific hot region, use the following command (run in 'hbase shell').
hbase cli> split '<region name>'
To split the table, use the following command (run in 'hbase shell').
hbase cli> split 'hbase:storefile'
Store File Tracking
By default, we use the FileBasedStoreFileTracker implementation. This implementation creates new files directly in the
store directory, avoiding the need for rename operations. It keeps a list of committed hfile instances in memory, backed by meta files
in each store directory. Whenever a new hfile is committed, the list of tracked files in the given store is updated and a new meta file is written with the
list contents and discarding the previous meta file, which contains an outdated list. More information about Store File Tracking can be
found at Store File Tracking
The FileBasedStoreFile tracker implementation is enabled by default, starting with Amazon EMR release 7.4.0:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker" }
To disable the FileBasedStoreFileTracker implementation, specify the following configuration override when launching a cluster:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker" }
Note
When reconfiguring the Amazon EMR cluster, all instance groups must be updated.
Operational considerations
HBase region servers use BlockCache to store data reads in memory and BucketCache to store data reads on local disk. In addition, region servers use MemStore to store data writes in-memory, and use write-ahead logs to store data writes in HDFS before the data is written to HBase StoreFiles in Amazon S3. The read performance of your cluster relates to how often a record can be retrieved from the in-memory or on-disk caches. A cache miss results in the record being read from the StoreFile in Amazon S3, which has significantly higher latency and higher standard deviation than reading from HDFS. In addition, the maximum request rates for Amazon S3 are lower than what can be achieved from the local cache, so caching data may be important for read-heavy workloads. For more information about Amazon S3 performance, see Performance optimization in the Amazon Simple Storage Service User Guide.
To improve performance, we recommend that you cache as much of your dataset as possible in
EC2 instance storage. Because the BucketCache uses the region server's EC2 instance
storage, you can choose an EC2 instance type with a sufficient instance store and add
Amazon EBS storage to accommodate the required cache size. You can also increase the
BucketCache size on attached instance stores and EBS volumes using the
hbase.bucketcache.size property. The default setting is 8,192
MB.
For writes, the frequency of MemStore flushes and the number of StoreFiles present during minor and major compactions can contribute significantly to an increase in region server response times. For optimal performance, consider increasing the size of the MemStore flush and HRegion block multiplier, which increases the elapsed time between major compactions, but also increases the lag in consistency if you use a read-replica. In some cases, you may get better performance using larger file block sizes (but less than 5 GB) to trigger Amazon S3 multipart upload functionality in EMRFS. Amazon EMR's block size default 128 MB. For more information, see HDFS configuration. We rarely see customers who exceed 1 GB block size while benchmarking performance with flushes and compactions. Additionally, HBase compactions and region servers perform optimally when fewer StoreFiles need to be compacted.
Tables can take a significant amount of time to drop on Amazon S3 because large directories need to be renamed. Consider disabling tables instead of dropping.
There is an HBase cleaner process that cleans up old WAL files and store files. With Amazon EMR release version 5.17.0 and later, the cleaner is enabled globally, and the following configuration properties can be used to control cleaner behavior.
| Configuration property | Default value | Description |
|---|---|---|
|
|
1 |
The number of threads allocated to clean expired large HFiles. |
|
|
1 |
The number of threads allocated to clean expired small HFiles. |
|
|
Set to one quarter of all available cores. |
The number of threads to scan the oldWALs directories. |
|
|
2 |
The number of threads to clean the WALs under the oldWALs directory. |
With Amazon EMR 5.17.0 and earlier, the cleaner operation can affect query performance when running heavy workloads, so we recommend that you enable the cleaner only during off-peak times. The cleaner has the following HBase shell commands:
cleaner_chore_enabledqueries whether the cleaner is enabled.cleaner_chore_runmanually runs the cleaner to remove files.cleaner_chore_switchenables or disables the cleaner and returns the previous state of the cleaner. For example,cleaner_chore_switch trueenables the cleaner.
Properties for HBase on Amazon S3 performance tuning
The following parameters can be adjusted to tune the performance of your workload when you use HBase on Amazon S3.
| Configuration property | Default value | Description |
|---|---|---|
|
|
8,192 |
The amount of disk space, in MB, reserved on region server Amazon EC2 instance stores and EBS volumes for BucketCache storage. The setting applies to all region server instances. Larger BucketCache sizes generally correspond to improved performance |
|
|
134217728 |
The data limit, in bytes, at which a memstore flush to Amazon S3 is triggered. |
|
|
4 |
A multiplier that determines the MemStore upper limit at which updates are blocked. If the MemStore exceeds |
|
|
10 |
The maximum number of StoreFiles that can exist in a store before updates are blocked. |
|
|
10737418240 |
The maximum size of a region before the region is split. |
Shutting down and restoring a cluster without data loss
To shut down an Amazon EMR cluster without losing data that hasn't been written to Amazon S3, you should flush your MemStore cache to Amazon S3 to write new store files. First, you'll need to disable all tables. The following step configuration can be used when you add a step to the cluster. For more information, see Work with steps using the AWS CLI and console in the Amazon EMR Management Guide.
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
Alternatively, you can run the following bash command directly.
bash /usr/lib/hbase/bin/disable_all_tables.sh
After disabling all tables, flush the hbase:meta table using the
HBase shell and the following command.
flush 'hbase:meta'
Then, you can run a shell script provided on the Amazon EMR cluster to flush the MemStore cache. You can either add it as a step or run it directly using the on-cluster AWS CLI. The script disables all HBase tables, which causes the MemStore in each region server to flush to Amazon S3. If the script completes successfully, the data persists in Amazon S3 and the cluster can be terminated.
To restart a cluster with the same HBase data, specify the same Amazon S3 location as the
previous cluster either in the AWS Management Console or using the hbase.rootdir
configuration property.
