DynamoDB でのデータのクエリとスキャンのベストプラクティス
このセクションでは、Amazon DynamoDB で Query オペレーションと Scan オペレーションを使用するためのベストプラクティスについて説明します。
スキャンのパフォーマンスに関する考慮事項
一般的に、Scan オペレーションは、DynamoDB の他のオペレーションよりも効率が低くなります。Scan オペレーションは常にテーブルまたはセカンダリインデックス全体をスキャンします。次に、値をフィルターして必要な結果を提供し、本質的に結果セットからデータを削除する余分なステップを追加します。
可能な場合、多くの結果を削除するフィルターを使用して大きなテーブルやインデックスで Scan オペレーションを実行することは避けるべきです。また、テーブルまたはインデックスが大きくなるにつれて、Scan オペレーションの処理速度は遅くなります。Scan オペレーションは、すべての項目でリクエストされた値を調べるので、大きなテーブルまたはインデックスに対してプロビジョニングされたスループットを 1 回のオペレーションで使い果たすことがあります。応答時間を短縮するには、アプリケーションが Scan ではなく Query を使用できるようにテーブルおよびインデックスを設計します。(テーブルの場合、GetItem API と BatchGetItem API を使用することを検討できます。)
リクエスト率への影響を最小限に抑える方法で Scan オペレーションを使用できるようアプリケーションを設計することもできます。これには、Scan オペレーションの代わりにグローバルセカンダリインデックスを使用する方が効率的な場合のモデリングが含まれる場合があります。このプロセスの詳細については、次の動画をご覧ください。
読み込みアクティビティの突然のスパイクの回避
テーブルを作成する際、読み込み容量ユニットと書き込み容量ユニットの要件を設定します。読み込みの場合、容量ユニットは、1 秒間に強い整合性のある 4 KB データ読み込みリクエストの数として表されます。結果整合性のある読み込みの場合、読み込み容量ユニットは 1 秒あたり 2 回の 4 KB 読み込みリクエストです。Scan オペレーションは、デフォルトで結果整合性のある読み込みを実行し、最大 1 MB (1 ページ) のデータを返すことができます。したがって、単一の Scan リクエストは、(1 MB ページサイズ/ 4 KB 項目サイズ)/2 (結果整合性のある読み込み) = 128 の読み込みオペレーションを使用できます。強力な整合性のある読み込みをリクエストした場合、Scan オペレーションでは、プロビジョニングされたスループット (256 回の読み込みオペレーション) が 2 倍消費されます。
これは、テーブルに設定されている読み込み容量と比較して使用量が急増することを表します。スキャンによる容量ユニットの使用により、同じテーブルに対する他の潜在的に重要なリクエストで利用可能な容量ユニットが使用できなくなります。その結果、これらのリクエストで ProvisionedThroughputExceeded 例外が発生する可能性が高くなります。
問題は、Scan が使用する容量ユニットの急激な増加だけではありません。スキャンは、パーティション上で隣り合うアイテムの読み込みをリクエストするため、同じパーティションのすべての容量ユニットを消費する可能性もあります。これは、リクエストが同じパーティションに到達し、そのすべての容量ユニットが消費され、そのパーティションへの他のリクエストがスロットリングされることを意味します。データの読み込みリクエストが複数のパーティションに分散されている場合、オペレーションは特定のパーティションをスロットリングしません。
次の図は、Query オペレーションと Scan オペレーションによって容量ユニットの使用率が急増したことによる影響、および同じテーブルに対するその他のリクエストへの影響を示しています。
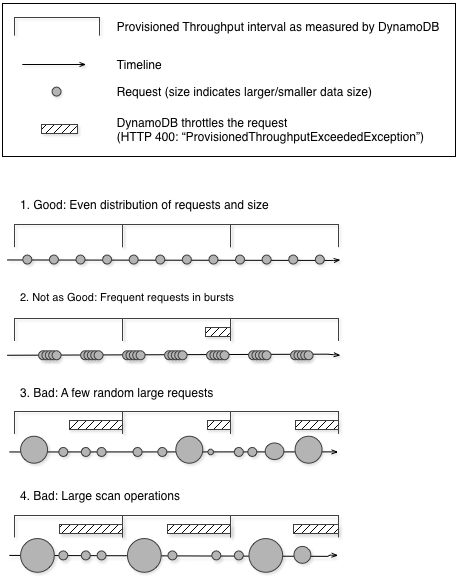
この図に示すように、使用率の急増は、テーブルのプロビジョニングされたスループットにいくつかの点で影響する可能性があります。
-
良い: リクエストとサイズの均等な分散
-
あまり良くない: バーストでの頻繁なリクエスト
-
悪い: いくつかのランダムな大きなリクエスト
-
悪い: 大規模なスキャンオペレーション
大きな Scan オペレーションを使用する代わりに、次のテクニックを使用して、テーブルのプロビジョニングされたスループットに対するスキャンの影響を最小限に抑えることができます。
-
ページサイズの削減
スキャンオペレーションはページ全体 (デフォルトでは 1 MB) を読み込むため、ページサイズを小さくすることで、スキャンオペレーションの影響を軽減できます。
Scanオペレーションは、リクエストのページサイズを設定するために使用できる Limit パラメータを提供します。同じようなページサイズの個々のQueryまたはScanリクエストでは使用される読み込みオペレーションの数が少なくなり、各リクエストの間で「一時停止」が作成されます。例えば、各項目が 4 KB で、ページサイズを 40 項目に設定するとします。Queryリクエストは、結果整合性のある読み込み操作を 20 回しか消費せず、強く整合性のある読み込み操作を 40 回しか消費しません 多くの小さいQueryまたはScanオペレーションを使用すると、他の重要なリクエストをスロットリングなしで正常に完了できます。 -
複数のスキャンオペレーションの分離
DynamoDB は、簡単にスケーリングできるように設計されています。その結果、アプリケーションは、複数の異なる目的のためにテーブルを作成することができます。場合によっては、複数のテーブル間でコンテンツを複製することも可能です。「ミッションクリティカル」なトラフィックを取らないテーブルでスキャンを実行する場合、アプリケーションによっては、2 つのテーブル間で、重要なトラフィックと記録用トラフィックなど、トラフィックを 1 時間ごとにローテーションすることで、このロードを処理します。他のアプリケーションでは、「ミッションクリティカル」なテーブルと「シャドウ」テーブルの 2 つのテーブルに対してすべての書き込みを実行することで、これを実行できます。
プロビジョニングされたスループットを超えたことを示すレスポンスコードを受け取ったリクエストを再試行するようにアプリケーションを設定します。または、UpdateTable オペレーションを使用して、テーブルのプロビジョニングされたスループットを増やします。ワークロードの一時的なスパイクが発生して、スループットがプロビジョニングされたレベルを超えた場合、エクスポネンシャルバックオフを使用してリクエストを再試行します。エクスポネンシャルバックオフの実装の詳細については、「エラーの再試行とエクスポネンシャルバックオフ」を参照してください。
並列スキャンを活用する
多くのアプリケーションでは、シーケンシャルスキャンよりも、並列 Scan オペレーションを使用することで利点が得られます。例えば、履歴データの大きなテーブルを処理するアプリケーションは、シーケンシャルデータよりもはるかに高速に並列スキャンを実行できます。バックグラウンドの「sweeper」プロセスに複数のワーカースレッドがあると、本番トラフィックに影響を与えずに、低い優先度でテーブルをスキャンできる可能性があります。これらの例では、並列 Scan は、プロビジョニングされたスループットリソースの他のアプリケーションが枯渇しないように使用されます。
並列スキャンは有益ですが、プロビジョニングされたスループットに大量のリクエストが発生する可能性があります。並列スキャンでは、アプリケーションには、Scan オペレーションが同時実行する複数のワーカーがあります。これにより、テーブルのプロビジョニングされた読み込み容量が短時間で消費されることがあります。その場合、テーブルにアクセスする必要がある他のアプリケーションでスロットリングが発生する可能性があります。
次の条件が満たされている場合、並列スキャンは正しい選択と考えられます。
テーブルのサイズが 20 GB 以上である。
テーブルのプロビジョニングされた読み込みスループットが完全に使用されていない。
シーケンシャル
Scanオペレーションが遅すぎる。
TotalSegments の選択
TotalSegments の最適な設定は、特定のデータ、テーブルのプロビジョニングされたスループット設定、およびパフォーマンス要件によって異なります。正しい設定を行うには、実験が必要な場合があります。データの 2 GB あたり 1 セグメントなど、単純な比率から始めることをお勧めします。例えば、30 GB のテーブルの場合、TotalSegments を 15 に設定してみます (30 GB/2 GB)。アプリケーションは 15 のワーカーを使用し、各ワーカーは異なるセグメントをスキャンします。
クライアントリソースに基づいて TotalSegments の値を選択することもできます。TotalSegments を 1~1000000 の任意の数に設定し、その数のセグメントを DynamoDB でスキャンできます。例えば、クライアントが同時に実行できるスレッドの数を制限している場合、アプリケーションで最高の Scan パフォーマンスを得るまで TotalSegments を段階的に増やすことができます。
並列スキャンをモニタリングして、プロビジョニングされたスループットの使用を最適化し、他のアプリケーションのリソースが不足していないことを確認します。プロビジョニングされたスループットがすべて消費されなくても Scan リクエストで引き続きスロットリングが発生する場合、TotalSegments の値を増やします。Scan リクエストが意図したものよりも多くのプロビジョニング済みスループットを消費する場合、TotalSegments の値を減らします。
