Tutorial: Getting started with S3 Express One Zone
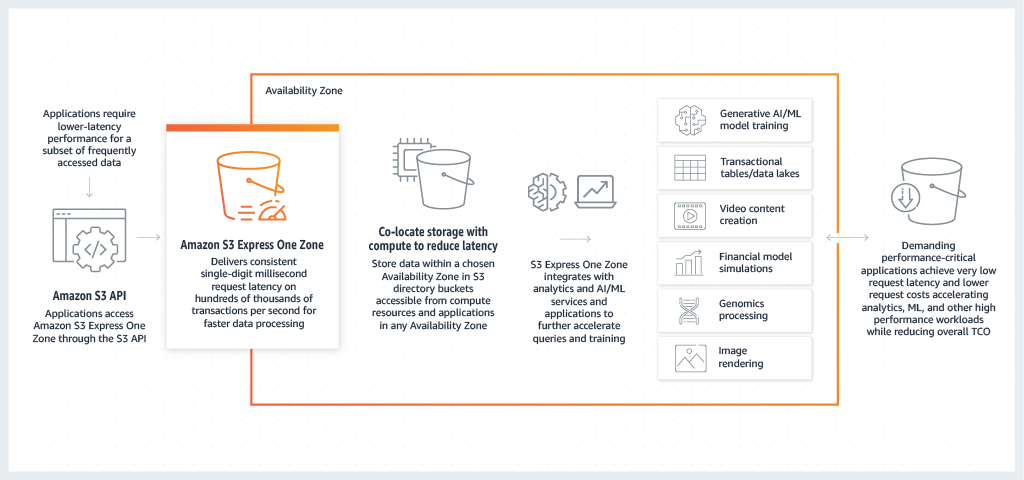
Amazon S3 Express One Zone is the first S3 storage class where you can select a single Availability Zone with the option to co-locate your object storage with your compute resources which provides the highest possible access speed. Data in S3 Express One Zone is stored in directory buckets located in Availability Zones. For more information on directory buckets, see Directory buckets.
S3 Express One Zone is ideal for any application where it's critical to minimize request latency. Such applications can be human-interactive workflows, like video editing, where creative professionals need responsive access to content from their user interfaces. S3 Express One Zone also benefits analytics and machine learning workloads that have similar responsiveness requirements from their data, especially workloads with a lot of smaller accesses or a large numbers of random accesses. S3 Express One Zone can be used with other AWS services such as Amazon EMR, Amazon Athena, AWS Glue Data Catalog and Amazon SageMaker Model Training to support analytics, artificial intelligence and machine learning (AI/ML) workloads,. You can work with the S3 Express One Zone storage class and directory buckets by using the Amazon S3 console, AWS SDKs, AWS Command Line Interface (AWS CLI), and Amazon S3 REST API. For more information, see What is S3 Express One Zone? and How is S3 Express One Zone different?.
Objective
In this tutorial, you will learn how to create a gateway endpoint, create and attach an IAM policy, create a directory bucket and then use the Import action to populate your directory bucket with objects currently stored in your general purpose bucket. Alternatively, you can manually upload objects to your directory bucket.
Topics
Prerequisites
Before you start this tutorial, you must have an AWS account that you can sign in to as an AWS Identity and Access Management (IAM) user with correct permissions.
Substeps
Create an AWS account
To complete this tutorial, you need an AWS account. When you sign up for AWS,
your AWS account is automatically signed up for all services in AWS, including
Amazon S3. You are charged only for the services that you use. For more information about
pricing, see S3
pricing
Create an IAM user in your AWS account (console)
AWS Identity and Access Management (IAM) is an AWS service that helps administrators securely control access to AWS resources. IAM administrators control who can be authenticated (signed in) and authorized (have permissions) to access objects and use directory buckets in S3 Express One Zone. You can use IAM for no additional charge.
By default, users don't have permissions to access directory buckets and perform S3 Express One Zone operations. To grant access permissions for directory buckets and S3 Express One Zone operations, you can use IAM to create users or roles and attach permissions to those identities. For more information about how to create an IAM user, see Creating IAM users (console) in the IAM User Guide. For more information about how to create an IAM role, see Creating a role to delegate permissions to an IAM user in the IAM User Guide.
For simplicity, this tutorial creates and uses an IAM user. After completing this tutorial, remember to Delete the IAM user. For production use, we recommend that you follow the Security best practices in IAM in the IAM User Guide. A best practice requires human users to use federation with an identity provider to access AWS with temporary credentials. Another best practice is to require workloads to use temporary credentials with IAM roles to access AWS. To learn more about using AWS IAM Identity Center to create users with temporary credentials, see Getting started in the AWS IAM Identity Center User Guide.
Warning
IAM users have long-term credentials, which presents a security risk. To help mitigate this risk, we recommend that you provide these users with only the permissions they require to perform the task and that you remove these users when they are no longer needed.
Create an IAM policy and attach it to an IAM user or role (console)
By default, users don't have permissions for directory buckets and S3 Express One Zone operations. To grant access permissions for directory buckets, you can use IAM to create users, groups, or roles and attach permissions to those identities. Directory buckets are the only resource that you can include in bucket policies or IAM identity policies for S3 Express One Zone access.
To use Regional endpoint API operations (bucket-level or control plane operations) with
S3 Express One Zone, you use the IAM authorization model, which doesn't involve session
management. Permissions are granted for actions individually. To use Zonal endpoint
API operations (object-level or data plane operations), you use CreateSession to create and manage sessions that are
optimized for low-latency authorization of data requests. To retrieve and use a
session token, you must allow the s3express:CreateSession action for
your directory bucket in an identity-based policy or a bucket policy. If you're
accessing S3 Express One Zone in the Amazon S3 console, through the AWS Command
Line Interface (AWS CLI), or by using the AWS SDKs, S3 Express One Zone creates
a session on your behalf. For more information, see CreateSession authorization and AWS Identity and Access Management (IAM) for S3 Express One Zone .
To create an IAM policy and attach the policy to an IAM user (or role)
Sign in to the AWS Management Console and open the IAM Management Console.
In the navigation pane, choose Policies.
Choose Create Policy.
Select JSON.
Copy the policy below into the Policy editor window. Before you can create directory buckets or use S3 Express One Zone, you must grant the necessary permissions to your AWS Identity and Access Management (IAM) role or users. This example policy allows access to the
CreateSessionAPI operation (for use with other Zonal or object-level API operations) and all of the Regional endpoint (bucket-level) API operations. This policy allows theCreateSessionAPI operation for use with all directory buckets, but the Regional endpoint API operations are allowed only for use with the specified directory bucket. To use this example policy, replace theuser input placeholdersChoose Next.
Name the policy.
Note
Bucket tags are not supported for S3 Express One Zone.
-
Select Create policy.
-
Now that you've created an IAM policy, you can attach it to an IAM user. In the navigation pane, choose Policies.
In the search bar, enter the name of your policy.
From the Actions menu, select Attach.
Under Filter by Entity Type, select IAM users or Roles.
In the search field, type the name of the user or role you wish to use.
Choose Attach Policy.
Topics
Next steps
In this tutorial, you have learned how to create a directory bucket and use the S3 Express One Zone storage class. After completing this tutorial, you can explore related AWS services to use with the S3 Express One Zone storage class.
You can use the following AWS services with the S3 Express One Zone storage class to support your specific low-latency use case.
-
Amazon Elastic Compute Cloud (Amazon EC2) – Amazon EC2 provides secure and scalable computing capacity in the AWS Cloud. Using Amazon EC2 lessens your need to invest in hardware up front, so you can develop and deploy applications faster. You can use Amazon EC2 to launch as many or as few virtual servers as you need, configure security and networking, and manage storage.
-
AWS Lambda – Lambda is a compute service that lets you run code without provisioning or managing servers. You configure notification settings on a bucket, and grant Amazon S3 permission to invoke a function on the function's resource-based permissions policy.
-
Amazon Elastic Kubernetes Service (Amazon EKS) – Amazon EKS is a managed service that eliminates the need to install, operate, and maintain your own Kubernetes control plane on AWS. Kubernetes
is an open-source system that automates the management, scaling, and deployment of containerized applications. -
Amazon Elastic Container Service (Amazon ECS) – Amazon ECS is a fully managed container orchestration service that helps you easily deploy, manage, and scale containerized applications.
-
Amazon EMR – Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark on AWS to process and analyze vast amounts of data.
-
Amazon Athena – Athena is an interactive query service that makes it easy to analyze data directly in Amazon S3 by using standard SQL. You can also use Athena to interactively run data analytics by using Apache Spark without having to plan for, configure, or manage resources. When you run Apache Spark applications on Athena, you submit Spark code for processing and receive the results directly.
-
AWS Glue Data Catalog – AWS Glue is a serverless data-integration service that makes it easy for analytics users to discover, prepare, move, and integrate data from multiple sources. You can use AWS Glue for analytics, machine learning, and application development. AWS Glue Data Catalog is a centralized repository that stores metadata about your organization's data sets. It acts as an index to the location, schema, and run-time metrics of your data sources.
-
Amazon SageMaker Runtime Model Training – Amazon SageMaker Runtime is a fully managed machine learning service. With SageMaker Runtime, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment.
For more information on S3 Express One Zone, see What is S3 Express One Zone? and How is S3 Express One Zone different?.
