Data modeling building blocks in DynamoDB
This section covers the building block layer to give you design patterns you can use in your application.
Topics
Composite sort key building block
When people think of NoSQL, they may also think of it as non-relational. Ultimately,
there is no reason relationships cannot be placed into a DynamoDB schema, they just look
different than relational databases and their foreign keys. One of the most critical
patterns we can use to develop a logical hierarchy of our data in DynamoDB is a composite
sort key. The most common style for designing one is with each layer of the hierarchy
(parent layer > child layer > grandchild layer) separated by a hashtag. For example,
PARENT#CHILD#GRANDCHILD#ETC.
| Partition key: PK | Sort key: SK |
|---|---|
| UserID | CART#ACTIVE#Apples |
| UserID | CART#ACTIVE#Bananas |
| UserID | CART#SAVED#Oranges |
| UserID | CART#SAVED#Pears |
| UserID | WISH#VEGGIES#Carrots |
While a partition key in DynamoDB always requires the exact value to query for data, we can apply a partial condition to the sort key from left to right similar to traversing a binary tree.
In the example above, we have an e-Commerce store with a Shopping Cart that needs to
be maintained across user sessions. Whenever the user logs in, they may want to see the
entire Shopping Cart including items saved for later. But when they enter the checkout,
only items in the active cart should be loaded for purchase. Since both of these
KeyConditions explicitly ask for CART sort keys, the additional
wishlist data is simply ignored by DynamoDB at read time. While both saved and active items
are a part of the same cart, we need to treat them differently in different parts of the
application, so applying a KeyCondition to the prefix of the sort key is
the most optimized way of retrieving only the data needed for each part of the
application.
Key features of this building block
-
Related items are stored locally to each other for effective data access
-
Using
KeyConditionexpressions, subsets of the hierarchy can be selectively retrieved meaning there are no wasted RCUs -
Different parts of the application can store their items under a specific prefix preventing overwritten items or conflicting writes
Multi-tenancy building block
Many customers use DynamoDB to host data for their multi-tenant applications. For these scenarios, we want to design the schema in a way that keeps all data from a single tenant in its own logical partition of the table. This leverages the concept of an Item Collection, which is a term for all items in a DynamoDB table with the same partition key. For more information on how DynamoDB approaches multitenancy, see Multitenancy on DynamoDB.
| Partition key: PK | Sort key: SK | ImageURL |
|---|---|---|
| UserOne | PhotoID1 | https://s3.amazonaws.com/[BUCKET-NAME]/[FILE-NAME].[FILE-TYPE] |
| UserOne | PhotoID2 | https://s3.amazonaws.com/[BUCKET-NAME]/[FILE-NAME].[FILE-TYPE] |
| UserTwo | PhotoID3 | https://s3.amazonaws.com/[BUCKET-NAME]/[FILE-NAME].[FILE-TYPE] |
| UserTwo | PhotoID4 | https://s3.amazonaws.com/[BUCKET-NAME]/[FILE-NAME].[FILE-TYPE] |
| UserThree | PhotoID5 | https://s3.amazonaws.com/[BUCKET-NAME]/[FILE-NAME].[FILE-TYPE] |
For this example, we are running a photo hosting site with potentially thousands of users. Each user will only upload photos to their own profile initially, but by default we will not allow a user to see the photos of any other user. An additional level of isolation would ideally be added to the authorization of each user's call to your API to ensure they are only requesting data from their own partition, but at the schema level, unique partition keys is adequate.
Key features of this building block
-
The amount of data read by any one user or tenant can only be as much as the total amount of items in their partition
-
Removal of a tenant's data due to an account closure or compliance request can be done tactfully and cheaply. Simply run a query where the partition key equals their tenant ID, then execute a
DeleteItemoperation for each primary key returned
Note
Designed with multi-tenancy in mind, you can use different encryption key providers across a single table to safely isolate data. AWS Database Encryption SDK for Amazon DynamoDB enables you to include client-side encryption in your DynamoDB workloads. You can perform attribute-level encryption, enabling you to encrypt specific attribute values before storing them in your DynamoDB table and search on encrypted attributes without decrypting the entire database beforehand.
Sparse index building block
Sometimes an access pattern requires looking for items that match a rare item or an item that receives a status (which requires an escalated response). Rather than regularly query across the entire dataset for these items, we can leverage the fact that global secondary indexes (GSI) are sparsely loaded with data. This means that only items in the base table that have the attributes defined in the index will be replicated to the index.
| Partition key: DeviceID | Sort key: State#Date | Operator | Date | EscalatedTo |
|---|---|---|---|---|
| d#12345 | NORMAL#2020-04-24T14:55:00 | Liz | 2020-04-24 | |
| d#12345 | WARNING1#2020-04-24T14:45:00 | Liz | 2020-04-24 | |
| d#12345 | WARNING1#2020-04-24T14:50:00 | Liz | 2020-04-24 | |
| d#54321 | NORMAL#2020-04-11T06:00:00 | Liz | 2020-04-11 | |
| d#54321 | NORMAL#2020-04-11T09:30:00 | Sue | 2020-04-11 | |
| d#54321 | WARNING2#2020-04-11T09:25:00 | Sue | 2020-04-11 | |
| d#54321 | WARNING3#2020-04-11T05:55:00 | Liz | 2020-04-11 | |
| d#11223 | WARNING4#2020-04-27T16:10:00 | Sue | 2020-04-27 | |
| d#11223 | WARNING4#2020-04-27T16:15:00 | Sue | 2020-04-27 | Sara |
| Partition key: EscalatedTo | Sort key: State#Date | DeviceID | Operator |
|---|---|---|---|
| Sara | WARNING4#2020-04-27T16:15:00 | d#11223 | Sue |
In this example, we see an IOT use case where each device in the field is reporting
back a status on a regular basis. For the majority of the reports we expect the device
to report everything is okay, but on occasion there can be a fault and it must be
escalated to a repair technician. For reports with an escalation, the attribute
EscalatedTo is added the item, but is not present otherwise. The GSI in
this example is partitioned by EscalatedTo and since the GSI brings over
keys from the base table we can still see which DeviceID reported the fault and at what
time.
While reads are cheaper than writes in DynamoDB, sparse indexes are a very powerful tool for use cases where instances of a specific type of item is rare but reads to find them are common.
Key features of this building block
-
Write and storage costs for the sparse GSI only apply to items that match the key pattern, so the cost of the GSI can be substantially less than other GSIs that have all items replicated to them
-
A composite sort key can still be used to further narrow down the items that match the desired query, for instance, a timestamp could be used for the sort key to only view faults reported in the last X minutes (
SK > 5 minutes ago, ScanIndexForward: False)
Time to live building block
Most data have some duration of time for which it can be considered worth keeping in a primary datastore. To facilitate data aging out from DynamoDB, it has a feature called time to live (TTL). The TTL feature allows you to define a specific attribute at the table level that needs monitoring for items with an epoch timestamp (that's in the past). This allows you to delete expired records from the table for free.
Note
If you are using Global Tables version 2019.11.21 (Current) of global tables and you also use the Time to Live feature, DynamoDB replicates TTL deletes to all replica tables. The initial TTL delete does not consume write capacity in the Region in which the TTL expiry occurs. However, the replicated TTL delete to the replica table(s) consumes replicated write capacity in each of the replica Regions and applicable charges will apply.
| Partition key: PK | Sort key: MessageTimestamp | TTL | Message |
|---|---|---|---|
| UserID | 2030-06-30T12:12:12 | 1909570332 | Hello |
| UserID | 2030-06-30T12:17:22 | 1909570647 | DynamoDB |
| UserID | 2030-06-30T12:22:27 | 1909570947 | TTL |
In this example, we have an application designed to let a user create messages that are short-lived. When a message is created in DynamoDB, the TTL attribute is set to a date seven days in the future by the application code. In roughly seven days, DynamoDB will see that the epoch timestamp of these items is in the past and delete them.
Since the deletes done by TTL are free, it is strongly recommended to use this feature to remove historical data from the table. This will reduce the overall storage bill each month and will likely reduce the costs of user reads since there will be less data to be retrieved by their queries. While TTL is enabled at the table level, it is up to you which items or entities to create a TTL attribute for and how far into the future to set the epoch timestamp to.
Key features of this building block
-
TTL deletes are run behind the scenes with no impact to your table performance
-
TTL is an asynchronous process that runs roughly every six hours, but can take over 48 hours for an expired record to be deleted
-
Do not rely on TTL deletes for use cases like lock records or state management if stale data must be cleaned up in less than 48 hours
-
-
You can name the TTL attribute a valid attribute name, but the value must be a number type
Time to live for archival building block
While TTL is an effective tool for deleting older data from DynamoDB, many use cases require an archive of the data be kept for a longer period of time than the primary datastore. In this instance, we can leverage TTL's timed deletion of records to push expired records into a long-term datastore.
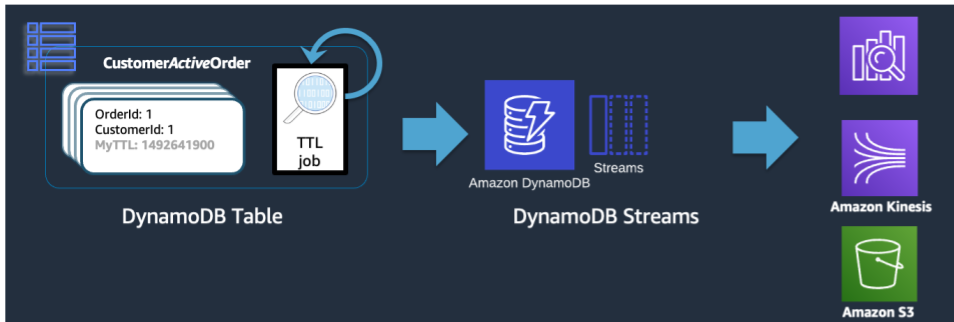
When a TTL delete is done by DynamoDB, it is still pushed into the DynamoDB Stream as a
Delete event. When DynamoDB TTL is the one who performs the delete though,
there is an attribute on the stream record of principal:dynamodb. Using a
Lambda subscriber to the DynamoDB Stream, we can apply an event-filter for only the DynamoDB
principal attribute and know that any records that match that filter are to be pushed to
an archival store like Amazon Glacier.
Key features of this building block
-
Once the low-latency reads of DynamoDB are no longer needed for the historical items, migrating them to a colder storage service like Amazon Glacier can reduce storage costs significantly while meeting the data compliance needs of your use case
-
If the data is persisted into Amazon S3, cost-efficient analytics tools like Amazon Athena or Redshift Spectrum can be used to perform historical analysis of the data
Vertical partitioning building block
Users familiar with a document model database will be familar with the idea of storing
all related data within a single JSON document. While DynamoDB supports JSON data types, it
doesn't support executing KeyConditions on nested JSON. Since
KeyConditions are what dictate how much data is read from disk and
effectively how many RCUs a query consumes, this can result in inefficiencies at scale.
To better optimize the writes and reads of DynamoDB, we recommend breaking apart the
document's individual entities into individual DynamoDB items, also referred to as
vertical partitioning.
For example, consider the following single JSON document that stores a user's profile, store, shopping cart, shipping address, and order history together:
{ "UserProfile": { "FirstName": "Paul", "LastName": "Atreides", "DateJoined": "1965-08-01" }, "Store": { "store_id": "STOREUID", "city": "Los Angeles", "zip_code": "90029" }, "ShoppingCart": [ { "Spice": { "SKU": "SpiceSKU", "CategoryID": "FictionalSpice", "DateAdded": "2019-06-11" } }, { "EspressoBeans": { "SKU": "CaffeineSKU", "CategoryID": "FOODANDDRINK", "DateAdded": "2019-06-10" } } ], "ShippingAddress": { "street_address": "1234 Arrakis Dr", "city": "Los Angeles", "zip_code": "90029", "status": "default" }, "OrderHistory#OrderUID": { "ProductA": "SKU_A", "ProductB": "SKU_B", "DateOrdered": "2018-09-28" } }
Using vertical partitioning, the single document is broken apart into individual items
that share the same partition key (UserID) but use a sort key prefix to
identify each entity. The following table shows the same data stored as separate
items:
| Partition key: UserID | Sort key: SK | Attributes |
|---|---|---|
| UserID | UserProfile | FirstName: Paul, LastName: Atreides, DateJoined: 1965-08-01 |
| UserID | Store#STOREUID | city: Los Angeles, zip_code: 90029 |
| UserID | Cart#ACTIVE#Spice | SKU: SpiceSKU, CategoryID: FictionalSpice, DateAdded: 2019-06-11 |
| UserID | Cart#ACTIVE#EspressoBeans | SKU: CaffeineSKU, CategoryID: FOODANDDRINK, DateAdded: 2019-06-10 |
| UserID | Address#default | street_address: 1234 Arrakis Dr, city: Los Angeles, zip_code: 90029, status: default |
| UserID | OrderHistory#OrderUID | ProductA: SKU_A, ProductB: SKU_B, DateOrdered: 2018-09-28 |
Vertical partitioning, as shown above, is a key example of single table design in action but can also be implemented across multiple tables if desired. Since DynamoDB bills writes in 1KB increments, you should ideally partition the document in a way that results in items under 1KB.
Key features of this building block
-
A hierarchy of data relationships is maintained via sort key prefixes so the singular document structure could be rebuilt client-side if needed
-
Singular components of the data structure can be updated independently resulting in small item updates being only 1 WCU
-
By using the sort key
BeginsWith, the application can retrieve similar data in a single query, aggregating read costs for reduced total cost/latency -
Large documents can easily be larger than the 400 KB individual item size limit in DynamoDB and vertical partitioning helps work around this limit
Write sharding building block
One of the very few hard limits DynamoDB has in place is the restriction of how much throughput a single physical partition can maintain per second (not necessarily a single partition key). These limits are presently:
-
1000 WCU (or 1000 <=1KB items written per second) and 3000 RCU (or 3000 <=4KB reads per second) strongly consistent or
-
6000 <=4KB reads per second eventually consistent
In the event requests against the table exceed either of these limits, an error is
sent back to the client SDK of ThroughputExceededException, more commonly
referred to as throttling. Use cases that require read operations beyond that limit will
mostly be served best by placing a read cache in front of DynamoDB, but write operations
require a schema level design known as write
sharding.

| Partition key: Candidate | Vote-Counter | Last-Update |
|---|---|---|
| CandidateA#1 | 10238 | 2019-09-30T11:35:53 |
| CandidateA#2 | 8452 | 2019-09-30T11:35:53 |
| CandidateA#3 | 9148 | 2019-09-30T11:35:53 |
| CandidateA#4 | 11092 | 2019-09-30T11:35:53 |
To solve this problem, we'll append a random integer onto the end of the partition key
for each contestant in the application's UpdateItem code. The range of the
random integer generator will need to have an upper bound matching or exceeding the
expected amount of writes per second for a given contestant divided by 1000. To support
20,000 votes per second, it would look like rand(0,19). Now that the data is stored
under separate logical partitions, it must be combined back together at read time. Since
vote totals doesn't need to be real time, a Lambda function scheduled to read all vote
partitions every X minutes could perform occasional aggregation for each contestant and
write it back to a single vote total record for live reads.
Key features of this building block
-
For use cases with extremely high write throughput for a given partition key that cannot be avoided, write operations can be artificially spread across multiple DynamoDB partitions
-
GSIs with a low cardinality partition key should also utilize this pattern since throttling on a GSI will apply backpressure to write operations on the base table
