Using EXPLAIN and EXPLAIN ANALYZE in Athena
The EXPLAIN statement shows the logical or distributed execution plan of a
specified SQL statement, or validates the SQL statement. You can output the results in text
format or in a data format for rendering into a graph.
Note
You can view graphical representations of logical and distributed plans for your
queries in the Athena console without using the EXPLAIN syntax. For more
information, see View execution plans for SQL queries.
The EXPLAIN ANALYZE statement shows both the distributed execution plan of a
specified SQL statement and the computational cost of each operation in a SQL query. You can
output the results in text or JSON format.
Considerations and limitations
The EXPLAIN and EXPLAIN ANALYZE statements in Athena have the
following limitations.
-
Because
EXPLAINqueries do not scan any data, Athena does not charge for them. However, becauseEXPLAINqueries make calls to AWS Glue to retrieve table metadata, you may incur charges from Glue if the calls go above the free tier limit for glue. -
Because
EXPLAIN ANALYZEqueries are executed, they do scan data, and Athena charges for the amount of data scanned. -
Row or cell filtering information defined in Lake Formation and query stats information are not shown in the output of
EXPLAINandEXPLAIN ANALYZE.
EXPLAIN syntax
EXPLAIN [ (option[, ...]) ]statement
option can be one of the following:
FORMAT { TEXT | GRAPHVIZ | JSON } TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
If the FORMAT option is not specified, the output defaults to
TEXT format. The IO type provides information about the
tables and schemas that the query reads.
EXPLAIN ANALYZE syntax
In addition to the output included in EXPLAIN, EXPLAIN
ANALYZE output also includes runtime statistics for the specified query such
as CPU usage, the number of rows input, and the number of rows output.
EXPLAIN ANALYZE [ (option[, ...]) ]statement
option can be one of the following:
FORMAT { TEXT | JSON }
If the FORMAT option is not specified, the output defaults to
TEXT format. Because all queries for EXPLAIN ANALYZE are
DISTRIBUTED, the TYPE option is not available for
EXPLAIN ANALYZE.
statement can be one of the following:
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
EXPLAIN examples
The following examples for EXPLAIN progress from the more straightforward
to the more complex.
In the following example, EXPLAIN shows the execution plan for a
SELECT query on Elastic Load Balancing logs. The format defaults to text
output.
EXPLAIN SELECT request_timestamp, elb_name, request_ip FROM sampledb.elb_logs;
Results
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULARYou can use the Athena console to graph a query plan for you. Enter a
SELECT statement like the following into the Athena query
editor, and then choose EXPLAIN.
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey
The Explain page of the Athena query editor opens and shows you a distributed plan and a logical plan for the query. The following graph shows the logical plan for the example.
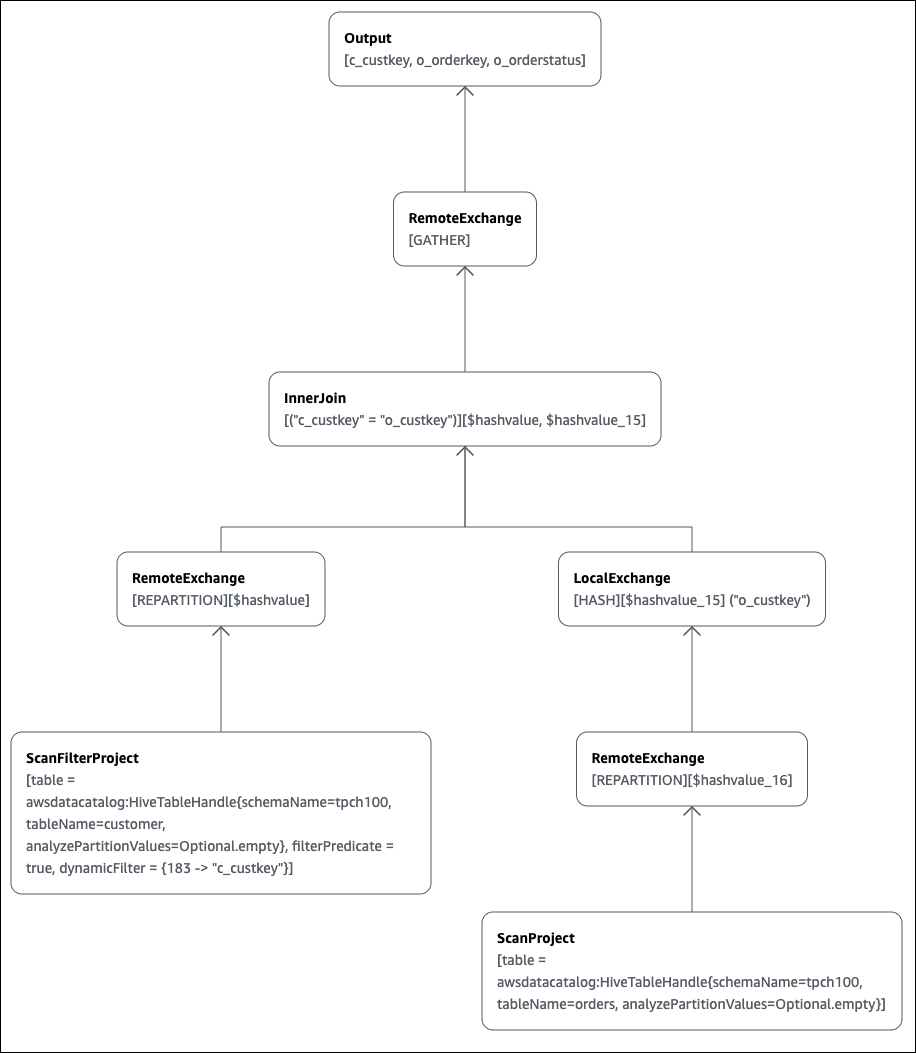
Important
Currently, some partition filters may not be visible in the nested
operator tree graph even though Athena does apply them to your query. To
verify the effect of such filters, run EXPLAIN or EXPLAIN
ANALYZE on your query and view the results.
For more information about using the query plan graphing features in the Athena console, see View execution plans for SQL queries.
When you use a filtering predicate on a partitioned key to query a partitioned table, the query engine applies the predicate to the partitioned key to reduce the amount of data read.
The following example uses an EXPLAIN query to verify partition
pruning for a SELECT query on a partitioned table. First, a
CREATE TABLE statement creates the
tpch100.orders_partitioned table. The table is partitioned on
column o_orderdate.
CREATE TABLE `tpch100.orders_partitioned`( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_totalprice` double, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) PARTITIONED BY ( `o_orderdate` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://amzn-s3-demo-bucket/<your_directory_path>/'
The tpch100.orders_partitioned table has several partitions on
o_orderdate, as shown by the SHOW PARTITIONS
command.
SHOW PARTITIONS tpch100.orders_partitioned; o_orderdate=1994 o_orderdate=2015 o_orderdate=1998 o_orderdate=1995 o_orderdate=1993 o_orderdate=1997 o_orderdate=1992 o_orderdate=1996
The following EXPLAIN query verifies partition pruning on the
specified SELECT statement.
EXPLAIN SELECT o_orderkey, o_custkey, o_orderdate FROM tpch100.orders_partitioned WHERE o_orderdate = '1995'
Results
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARThe bold text in the result shows that the predicate o_orderdate =
'1995' was applied on the PARTITION_KEY.
The following EXPLAIN query checks the SELECT
statement's join order and join type. Use a query like this to examine query
memory usage so that you can reduce the chances of getting an
EXCEEDED_LOCAL_MEMORY_LIMIT error.
EXPLAIN (TYPE DISTRIBUTED) SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
Results
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARThe example query was optimized into a cross join for better performance.
The results show that tpch100.orders will be distributed as the
BROADCAST distribution type. This implies that the
tpch100.orders table will be distributed to all nodes that
perform the join operation. The BROADCAST distribution type
will require that the all of the filtered results of the
tpch100.orders table fit into the memory of each node that
performs the join operation.
However, the tpch100.customer table is smaller than
tpch100.orders. Because tpch100.customer
requires less memory, you can rewrite the query to BROADCAST
tpch100.customer instead of tpch100.orders. This
reduces the chance of the query receiving the
EXCEEDED_LOCAL_MEMORY_LIMIT error. This strategy assumes
the following points:
-
The
tpch100.customer.c_custkeyis unique in thetpch100.customertable. -
There is a one-to-many mapping relationship between
tpch100.customerandtpch100.orders.
The following example shows the rewritten query.
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.orders o JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes. ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
You can use an EXPLAIN query to check the effectiveness of
filtering predicates. You can use the results to remove predicates that have no
effect, as in the following example.
EXPLAIN SELECT c.c_name FROM tpch100.customer c WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT) AND c.c_custkey BETWEEN 1000 AND 2000 AND c.c_custkey = 1500
Results
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULARThe filterPredicate in the results shows that the optimizer
merged the original three predicates into two predicates and changed their
order of application.
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
Because the results show that the predicate AND c.c_custkey BETWEEN
1000 AND 2000 has no effect, you can remove this predicate
without changing the query results.
For information about the terms used in the results of
EXPLAIN queries, see Understand Athena EXPLAIN statement
results.
EXPLAIN ANALYZE examples
The following examples show example EXPLAIN ANALYZE queries and
outputs.
In the following example, EXPLAIN ANALYZE shows the execution
plan and computational costs for a SELECT query on CloudFront logs. The
format defaults to text output.
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
Results
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULARThe following example shows the execution plan and computational costs for a
SELECT query on CloudFront logs. The example specifies JSON as the
output format.
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
Results
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}Additional resources
For additional information, see the following resources.
-
Trino
EXPLAINdocumentation -
Trino
EXPLAIN ANALYZEdocumentation -
Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
in the AWS Big Data Blog.
