Amazon Athena Azure Synapse connector
The Amazon Athena connector for Azure
Synapse analytics
This connector can be registered with Glue Data Catalog as a federated catalog. It supports data access controls defined in Lake Formation at the catalog, database, table, column, row, and tag levels. This connector uses Glue Connections to centralize configuration properties in Glue.
Prerequisites
Deploy the connector to your AWS account using the Athena console or the AWS Serverless Application Repository. For more information, see Create a data source connection or Use the AWS Serverless Application Repository to deploy a data source connector.
Limitations
-
Write DDL operations are not supported.
-
In a multiplexer setup, the spill bucket and prefix are shared across all database instances.
-
Any relevant Lambda limits. For more information, see Lambda quotas in the AWS Lambda Developer Guide.
-
In filter conditions, you must cast the
DateandTimestampdata types to the appropriate data type. -
To search for negative values of type
RealandFloat, use the<=or>=operator. -
The
binary,varbinary,image, androwversiondata types are not supported.
Terms
The following terms relate to the Synapse connector.
-
Database instance – Any instance of a database deployed on premises, on Amazon EC2, or on Amazon RDS.
-
Handler – A Lambda handler that accesses your database instance. A handler can be for metadata or for data records.
-
Metadata handler – A Lambda handler that retrieves metadata from your database instance.
-
Record handler – A Lambda handler that retrieves data records from your database instance.
-
Composite handler – A Lambda handler that retrieves both metadata and data records from your database instance.
-
Property or parameter – A database property used by handlers to extract database information. You configure these properties as Lambda environment variables.
-
Connection String – A string of text used to establish a connection to a database instance.
-
Catalog – A non-AWS Glue catalog registered with Athena that is a required prefix for the
connection_stringproperty. -
Multiplexing handler – A Lambda handler that can accept and use multiple database connections.
Parameters
Use the parameters in this section to configure the Synapse connector.
Note
Athena data source connectors created on December 3, 2024 and later use AWS Glue connections.
The parameter names and definitions listed below are for Athena data source connectors created prior to December 3, 2024. These can differ from their corresponding AWS Glue connection properties. Starting December 3, 2024, use the parameters below only when you manually deploy an earlier version of an Athena data source connector.
We recommend that you configure a Synapse connector by using a Glue
connections object. To do this, set the glue_connection
environment variable of the Synapse connector Lambda to the name of the Glue
connection to use.
Glue connections properties
Use the following command to get the schema for a Glue connection object. This schema contains all the parameters that you can use to control your connection.
aws glue describe-connection-type --connection-type SYNAPSE
Lambda environment properties
-
glue_connection – Specifies the name of the Glue connection associated with the federated connector.
-
casing_mode – (Optional) Specifies how to handle casing for schema and table names. The
casing_modeparameter uses the following values to specify the behavior of casing:-
none – Do not change case of the given schema and table names. This is the default for connectors that have an associated glue connection.
-
upper – Upper case all given schema and table names.
-
lower – Lower case all given schema and table names.
-
Note
-
All connectors that use Glue connections must use AWS Secrets Manager to store credentials.
-
The Synapse connector created using Glue connections does not support the use of a multiplexing handler.
-
The Synapse connector created using Glue connections only supports
ConnectionSchemaVersion2.
Connection string
Use a JDBC connection string in the following format to connect to a database instance.
synapse://${jdbc_connection_string}
Using a multiplexing handler
You can use a multiplexer to connect to multiple database instances with a single Lambda function. Requests are routed by catalog name. Use the following classes in Lambda.
| Handler | Class |
|---|---|
| Composite handler | SynapseMuxCompositeHandler |
| Metadata handler | SynapseMuxMetadataHandler |
| Record handler | SynapseMuxRecordHandler |
Multiplexing handler parameters
| Parameter | Description |
|---|---|
$ |
Required. A database instance connection string. Prefix the
environment variable with the name of the catalog used in Athena. For example,
if the catalog registered with Athena is
mysynapsecatalog, then the environment
variable name is
mysynapsecatalog_connection_string. |
default |
Required. The default connection string. This string is used
when the catalog is
lambda:${AWS_LAMBDA_FUNCTION_NAME}. |
The following example properties are for a Synapse MUX Lambda function
that supports two database instances: synapse1 (the
default), and synapse2.
| Property | Value |
|---|---|
default |
synapse://jdbc:synapse://synapse1.hostname:port;databaseName= |
synapse_catalog1_connection_string |
synapse://jdbc:synapse://synapse1.hostname:port;databaseName= |
synapse_catalog2_connection_string |
synapse://jdbc:synapse://synapse2.hostname:port;databaseName= |
Providing credentials
To provide a user name and password for your database in your JDBC connection string, you can use connection string properties or AWS Secrets Manager.
-
Connection String – A user name and password can be specified as properties in the JDBC connection string.
Important
As a security best practice, don't use hardcoded credentials in your environment variables or connection strings. For information about moving your hardcoded secrets to AWS Secrets Manager, see Move hardcoded secrets to AWS Secrets Manager in the AWS Secrets Manager User Guide.
-
AWS Secrets Manager – To use the Athena Federated Query feature with AWS Secrets Manager, the VPC connected to your Lambda function should have internet access
or a VPC endpoint to connect to Secrets Manager. You can put the name of a secret in AWS Secrets Manager in your JDBC connection string. The connector replaces the secret name with the
usernameandpasswordvalues from Secrets Manager.For Amazon RDS database instances, this support is tightly integrated. If you use Amazon RDS, we highly recommend using AWS Secrets Manager and credential rotation. If your database does not use Amazon RDS, store the credentials as JSON in the following format:
{"username": "${username}", "password": "${password}"}
Example connection string with secret name
The following string has the secret name ${secret_name}.
synapse://jdbc:synapse://hostname:port;databaseName=<database_name>;${secret_name}
The connector uses the secret name to retrieve secrets and provide the user name and password, as in the following example.
synapse://jdbc:synapse://hostname:port;databaseName=<database_name>;user=<user>;password=<password>
Using a single connection handler
You can use the following single connection metadata and record handlers to connect to a single Synapse instance.
| Handler type | Class |
|---|---|
| Composite handler | SynapseCompositeHandler |
| Metadata handler | SynapseMetadataHandler |
| Record handler | SynapseRecordHandler |
Single connection handler parameters
| Parameter | Description |
|---|---|
default |
Required. The default connection string. |
The single connection handlers support one database instance and must provide a
default connection string parameter. All other connection
strings are ignored.
The following example property is for a single Synapse instance supported by a Lambda function.
| Property | Value |
|---|---|
default |
synapse://jdbc:sqlserver://hostname:port;databaseName= |
Configuring Active Directory authentication
The Amazon Athena Azure Synapse connector supports Microsoft Active Directory Authentication. Before you begin, you must configure an administrative user in the Microsoft Azure portal and then use AWS Secrets Manager to create a secret.
To set the Active Directory administrative user
-
Using an account that has administrative privileges, sign in to the Microsoft Azure portal at https://portal.azure.com/
. -
In the search box, enter Azure Synapse Analytics, and then choose Azure Synapse Analytics.

-
Open the menu on the left.

-
In the navigation pane, choose Azure Active Directory.
-
On the Set admin tab, set Active Directory admin to a new or existing user.
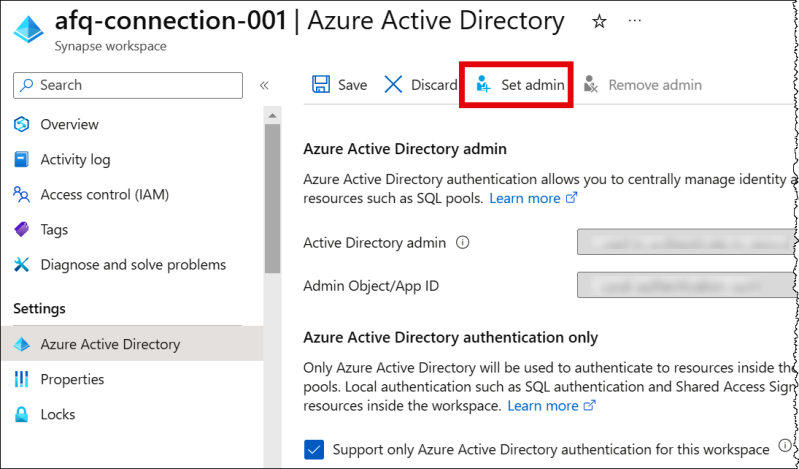
-
In AWS Secrets Manager, store the admin username and password credentials. For information on creating a secret in Secrets Manager, see Create an AWS Secrets Manager secret.
To view your secret in Secrets Manager
Open the Secrets Manager console at https://console.aws.amazon.com/secretsmanager/
. -
In the navigation pane, choose Secrets.
-
On the Secrets page, choose the link to your secret.
-
On the details page for your secret, choose Retrieve secret value.
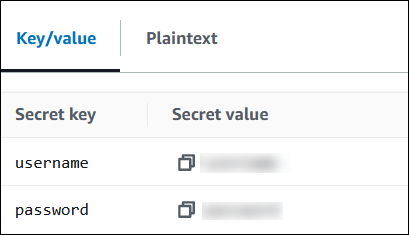
Modifying the connection string
To enable Active Directory Authentication for the connector, modify the connection string using the following syntax:
synapse://jdbc:synapse://hostname:port;databaseName=database_name;authentication=ActiveDirectoryPassword;{secret_name}
Using ActiveDirectoryServicePrincipal
The Amazon Athena Azure Synapse connector also supports
ActiveDirectoryServicePrincipal. To enable this, modify the
connection string as follows.
synapse://jdbc:synapse://hostname:port;databaseName=database_name;authentication=ActiveDirectoryServicePrincipal;{secret_name}
For secret_name, specify the application or client ID as the
username and the secret of a service principal identity in the
password.
Spill parameters
The Lambda SDK can spill data to Amazon S3. All database instances accessed by the same Lambda function spill to the same location.
| Parameter | Description |
|---|---|
spill_bucket |
Required. Spill bucket name. |
spill_prefix |
Required. Spill bucket key prefix. |
spill_put_request_headers |
(Optional) A JSON encoded map of request headers and values for
the Amazon S3 putObject request that is used for spilling
(for example, {"x-amz-server-side-encryption" :
"AES256"}). For other possible headers, see PutObject
in the Amazon Simple Storage Service API Reference. |
Data type support
The following table shows the corresponding data types for Synapse and Apache Arrow.
| Synapse | Arrow |
|---|---|
| bit | TINYINT |
| tinyint | SMALLINT |
| smallint | SMALLINT |
| int | INT |
| bigint | BIGINT |
| decimal | DECIMAL |
| numeric | FLOAT8 |
| smallmoney | FLOAT8 |
| money | DECIMAL |
| float[24] | FLOAT4 |
| float[53] | FLOAT8 |
| real | FLOAT4 |
| datetime | Date(MILLISECOND) |
| datetime2 | Date(MILLISECOND) |
| smalldatetime | Date(MILLISECOND) |
| date | Date(DAY) |
| time | VARCHAR |
| datetimeoffset | Date(MILLISECOND) |
| char[n] | VARCHAR |
| varchar[n/max] | VARCHAR |
| nchar[n] | VARCHAR |
| nvarchar[n/max] | VARCHAR |
Partitions and splits
A partition is represented by a single partition column of type varchar.
Synapse supports range partitioning, so partitioning is implemented by extracting the
partition column and partition range from Synapse metadata tables. These range values
are used to create the splits.
Performance
Selecting a subset of columns significantly slows down query runtime. The connector shows significant throttling due to concurrency.
The Athena Synapse connector performs predicate pushdown to decrease the data scanned by the query. Simple predicates and complex expressions are pushed down to the connector to reduce the amount of data scanned and decrease query execution run time.
Predicates
A predicate is an expression in the WHERE clause of a SQL query that
evaluates to a Boolean value and filters rows based on multiple conditions. The
Athena Synapse connector can combine these expressions and push them directly to
Synapse for enhanced functionality and to reduce the amount of data scanned.
The following Athena Synapse connector operators support predicate pushdown:
-
Boolean: AND, OR, NOT
-
Equality: EQUAL, NOT_EQUAL, LESS_THAN, LESS_THAN_OR_EQUAL, GREATER_THAN, GREATER_THAN_OR_EQUAL, NULL_IF, IS_NULL
-
Arithmetic: ADD, SUBTRACT, MULTIPLY, DIVIDE, MODULUS, NEGATE
-
Other: LIKE_PATTERN, IN
Combined pushdown example
For enhanced querying capabilities, combine the pushdown types, as in the following example:
SELECT * FROM my_table WHERE col_a > 10 AND ((col_a + col_b) > (col_c % col_d)) AND (col_e IN ('val1', 'val2', 'val3') OR col_f LIKE '%pattern%');
Passthrough queries
The Synapse connector supports passthrough queries. Passthrough queries use a table function to push your full query down to the data source for execution.
To use passthrough queries with Synapse, you can use the following syntax:
SELECT * FROM TABLE( system.query( query => 'query string' ))
The following example query pushes down a query to a data source in Synapse. The query
selects all columns in the customer table, limiting the results to 10.
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
License information
By using this connector, you acknowledge the inclusion of third party components, a list
of which can be found in the pom.xml
Additional resources
-
For an article that shows how to use QuickSight and Amazon Athena Federated Query to build dashboards and visualizations on data stored in Microsoft Azure Synapse databases, see Perform multi-cloud analytics using QuickSight, Amazon Athena Federated Query, and Microsoft Azure Synapse
in the AWS Big Data Blog. For the latest JDBC driver version information, see the pom.xml
file for the Synapse connector on GitHub.com. For additional information about this connector, visit the corresponding site
on GitHub.com.
