Amazon Athena Neptune connector
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Neptune's purpose-built, high-performance graph database engine stores billions of relationships optimally and queries graphs with a latency of only milliseconds. For more information, see the Neptune User Guide.
The Amazon Athena Neptune Connector enables Athena to communicate with your Neptune graph database instance, making your Neptune graph data accessible by SQL queries.
This connector does not use Glue Connections to centralize configuration properties in Glue. Connection configuration is done through Lambda.
If you have Lake Formation enabled in your account, the IAM role for your Athena federated Lambda connector that you deployed in the AWS Serverless Application Repository must have read access in Lake Formation to the AWS Glue Data Catalog.
Prerequisites
Using the Neptune connector requires the following three steps.
-
Setting up a Neptune cluster
-
Setting up an AWS Glue Data Catalog
-
Deploying the connector to your AWS account. For more information, see Create a data source connection or Use the AWS Serverless Application Repository to deploy a data source connector. For additional details specific to deploying the Neptune connector, see Deploy the Amazon Athena Neptune Connector
on GitHub.com.
Limitations
Currently, the Neptune Connector has the following limitation.
-
Projecting columns, including the primary key (ID), is not supported.
Setting up a Neptune cluster
If you don't have an existing Amazon Neptune cluster and property graph dataset in it that you would like to use, you must set one up.
Make sure you have an internet gateway and NAT gateway in the VPC that hosts your Neptune cluster. The private subnets that the Neptune connector Lambda function uses should have a route to the internet through this NAT Gateway. The Neptune connector Lambda function uses the NAT Gateway to communicate with AWS Glue.
For instructions on setting up a new Neptune cluster and loading it with a sample
dataset, see Sample Neptune Cluster Setup
Setting up an AWS Glue Data Catalog
Unlike traditional relational data stores, Neptune graph DB nodes and edges do not use a set schema. Each entry can have different fields and data types. However, because the Neptune connector retrieves metadata from the AWS Glue Data Catalog, you must create an AWS Glue database that has tables with the required schema. After you create the AWS Glue database and tables, the connector can populate the list of tables available to query from Athena.
Enabling case insensitive column matching
To resolve column names from your Neptune table with the correct casing even when the column names are all lower cased in AWS Glue, you can configure the Neptune connector for case insensitive matching.
To enable this feature, set the Neptune connector Lambda function environment
variable enable_caseinsensitivematch to true.
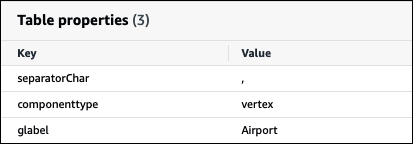
Specifying the AWS Glue glabel table parameter for cased table names
Because AWS Glue supports only lowercase table names, it is important to specify the
glabel AWS Glue table parameter when you create an AWS Glue table for
Neptune and your Neptune table name includes casing.
In your AWS Glue table definition, include the glabel parameter and set
its value to your table name with its original casing. This ensures that the correct
casing is preserved when AWS Glue interacts with your Neptune table. The following
example sets the value of glabel to the table name
Airport.
glabel = Airport
For more information on setting up a AWS Glue Data Catalog to work with Neptune, see Set up AWS Glue Catalog
Performance
The Athena Neptune connector performs predicate pushdown to decrease the data scanned by the query. However, predicates using the primary key result in query failure.
LIMIT clauses reduce the amount of data scanned, but if you don't provide a predicate, you should expect SELECT queries with a LIMIT clause to scan at least 16 MB of data. The Neptune connector is resilient to throttling due to concurrency.
Passthrough queries
The Neptune connector supports passthrough queries. You can use this feature to run Gremlin queries on property graphs and to run SPARQL queries on RDF data.
To create passthrough queries with Neptune, use the following syntax:
SELECT * FROM TABLE( system.query( DATABASE => 'database_name', COLLECTION => 'collection_name', QUERY => 'query_string' ))
The following example Neptune passthrough query filters for airports with the code
ATL. The doubled single quotes are for escaping.
SELECT * FROM TABLE( system.query( DATABASE => 'graph-database', COLLECTION => 'airport', QUERY => 'g.V().has(''airport'', ''code'', ''ATL'').valueMap()' ))
Additional resources
For additional information about this connector, visit the corresponding site
