Array jobs
An array job is a job that shares common parameters, such as the job definition, vCPUs, and memory. It runs as a collection of related yet separate basic jobs that might be distributed across multiple hosts and might run concurrently. Array jobs are the most efficient way to run extremely parallel jobs such as Monte Carlo simulations, parametric sweeps, or large rendering jobs.
AWS Batch array jobs are submitted just like regular jobs. However, you specify an array size
(between 2 and 10,000) to define how many child jobs should run in the array. If you submit a job
with an array size of 1000, a single job runs and spawns 1000 child jobs. The array job is a
reference or pointer to manage all the child jobs. This way, you can submit large workloads with a
single query. The timeout specified in the attemptDurationSeconds parameter applies
to each child job. The parent array job does not have a timeout.
When you submit an array job, the parent array job gets a normal AWS Batch job ID. Each child
job has the same base ID. However, the array index for the child job is appended to the end of the
parent ID, such as example_job_ID:0
The parent array job can enter a SUBMITTED, PENDING,
FAILED, or SUCCEEDED status. An array parent job is updated to
PENDING when any child job is updated to RUNNABLE. For more
information about job dependencies, see Job dependencies.
At runtime, the AWS_BATCH_JOB_ARRAY_INDEX environment variable is set to the
container's corresponding job array index number. The first array job index is numbered
0, and subsequent attempts are in ascending order (for example, 1, 2, and 3). You
can use this index value to control how your array job children are differentiated. For more
information, see Use the array job index to control job differentiation.
For array job dependencies, you can specify a type for a dependency, such as
SEQUENTIAL or N_TO_N. You can specify a SEQUENTIAL type
dependency (without specifying a job ID) so that each child array job completes sequentially,
starting at index 0. For example, if you submit an array job with an array size of 100, and
specify a dependency with type SEQUENTIAL, 100 child jobs are spawned sequentially,
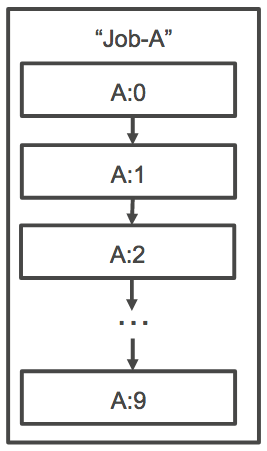
where the first child job must succeed before the next child job starts. The figure below shows
Job A, an array job with an array size of 10. Each job in Job A's child index is dependent on the
previous child job. Job A:1 can't start until job A:0 finishes.
You can also specify an N_TO_N type dependency with a job ID for array jobs.
That way, each index child of this job must wait for the corresponding index child of each
dependency to complete before it can begin. The following figure shows Job A and Job B, two array
jobs with an array size of 10,000 each. Each job in Job B's child index is dependent on the
corresponding index in Job A. Job B:1 can't start until job A:1 finishes.

If you cancel or terminate a parent array job, all the child jobs are cancelled or terminated with it. You can cancel or terminate individual child jobs (which moves them to a FAILED status) without affecting the other child jobs. However, if a child array job fails (on its own, or by manually cancelling or terminating the job), the parent job also fails. In this scenario, the parent job transitions to FAILED when all child jobs complete.
For more information about searching and filtering array jobs, see Search for jobs in a job queue.
