Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Aurora Aurora-Empfehlungen anzeigen
Mithilfe der RDS Amazon-Konsole können Sie Aurora-Empfehlungen für Ihre Datenbankressourcen einsehen. Für einen DB-Cluster werden die Empfehlungen für den DB-Cluster und seine Instances angezeigt.
Um die Aurora-Empfehlungen einzusehen
Melden Sie sich bei der an AWS Management Console und öffnen Sie die RDS Amazon-Konsole unter https://console.aws.amazon.com/rds/
. -
Führen Sie im Navigationsbereich einen der folgenden Schritte aus:
Wählen Sie Empfehlungen aus. Die Anzahl der aktiven Empfehlungen für Ihre Ressourcen und die Anzahl der Empfehlungen mit dem höchsten Schweregrad, die im letzten Monat generiert wurden, sind neben Empfehlungen verfügbar. Um die Anzahl der aktiven Empfehlungen für jeden Schweregrad zu ermitteln, wählen Sie die Zahl aus, die den höchsten Schweregrad anzeigt.
Standardmäßig wird auf der Seite „Empfehlungen“ eine Liste der neuen Empfehlungen des letzten Monats angezeigt. Amazon Aurora gibt Empfehlungen für alle Ressourcen in Ihrem Konto und sortiert die Empfehlungen nach ihrem Schweregrad.
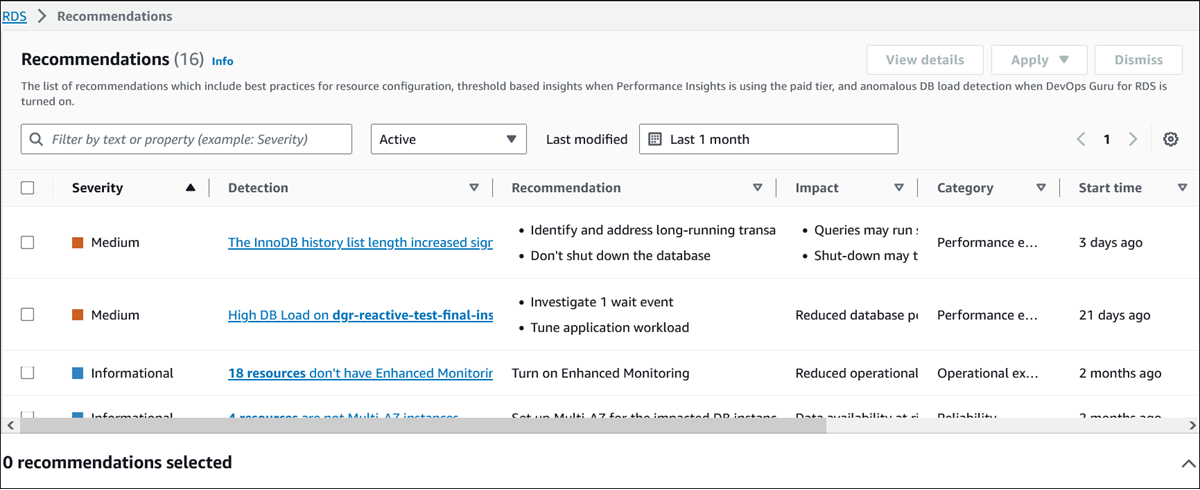
Sie können eine Empfehlung auswählen, um unten auf der Seite einen Abschnitt zu sehen, der die betroffenen Ressourcen und Einzelheiten zur Umsetzung der Empfehlung enthält.
Wählen Sie auf der Seite Datenbanken die Option Empfehlungen für eine Ressource aus.

Auf der Registerkarte Empfehlungen werden die Empfehlungen und ihre Details für die ausgewählte Ressource angezeigt.
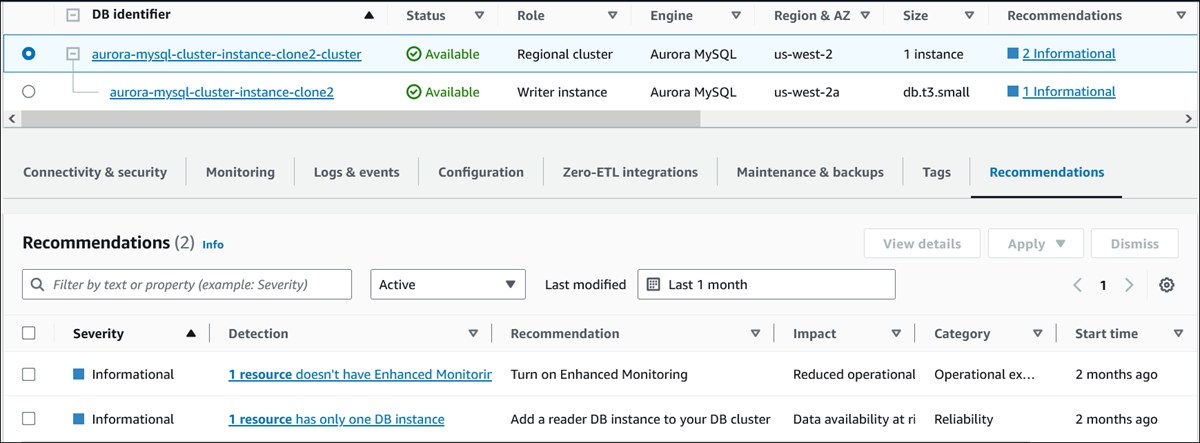
Die folgenden Informationen sind für die Empfehlungen verfügbar:
Schweregrad — Das Ausmaß der Auswirkungen des Problems. Die Schweregrade lauten „Hoch“, „Mittel“, „Niedrig“ und „Informativ“.
Erkennung — Die Anzahl der betroffenen Ressourcen und eine kurze Beschreibung des Problems. Wählen Sie diesen Link, um die Empfehlung und die Analysedetails anzuzeigen.
Empfehlung — Eine kurze Beschreibung der empfohlenen Maßnahme, die angewendet werden soll.
Auswirkung — Eine kurze Beschreibung der möglichen Auswirkungen, wenn die Empfehlung nicht angewendet wird.
Kategorie — Die Art der Empfehlung. Die Kategorien sind Leistungseffizienz, Sicherheit, Zuverlässigkeit, Kostenoptimierung, betriebliche Exzellenz und Nachhaltigkeit.
Status — Der aktuelle Status der Empfehlung. Die möglichen Status sind Alle, Aktiv, Abgelehnt, Gelöst und Ausstehend.
Startzeit — Die Zeit, zu der das Problem begann. Zum Beispiel vor 18 Stunden.
Letzte Änderung — Der Zeitpunkt, zu dem die Empfehlung aufgrund einer Änderung des Schweregrads zuletzt vom System aktualisiert wurde, oder der Zeitpunkt, zu dem Sie auf die Empfehlung geantwortet haben. Zum Beispiel vor 10 Stunden.
Endzeit — Der Zeitpunkt, zu dem das Problem beendet wurde. Bei anhaltenden Problemen wird die Uhrzeit nicht angezeigt.
Ressourcen-ID — Der Name einer oder mehrerer Ressourcen.
-
(Optional) Wählen Sie in dem Feld die Operatoren Schweregrad oder Kategorie aus, um die Liste der Empfehlungen zu filtern.
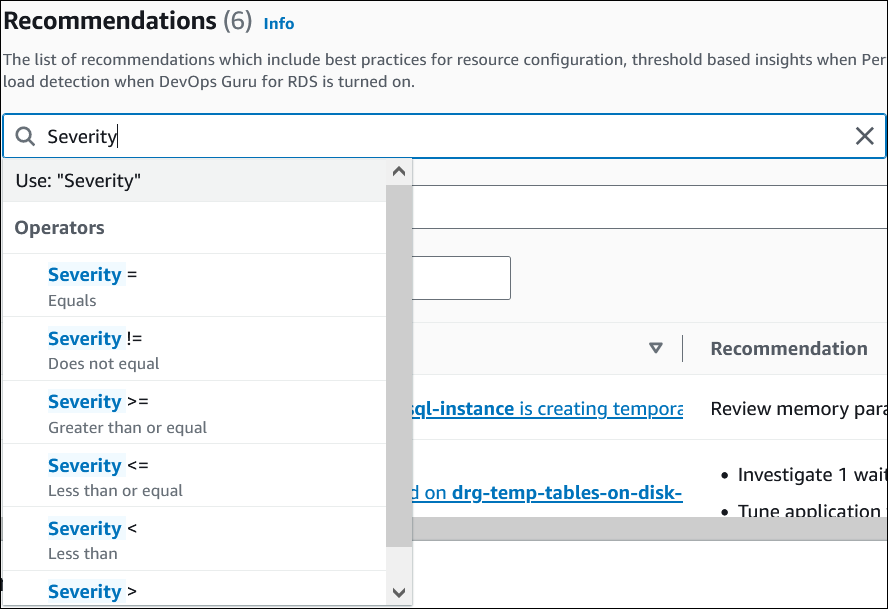
Die Empfehlungen für den ausgewählten Vorgang werden angezeigt.
-
(Optional) Wählen Sie einen der folgenden Empfehlungsstatus:
-
Aktiv (Standard) — Zeigt die aktuellen Empfehlungen an, die Sie anwenden, für das nächste Wartungsfenster planen oder ablehnen können.
-
Alle — Zeigt alle Empfehlungen mit dem aktuellen Status an.
-
Abgelehnt — Zeigt die abgelehnten Empfehlungen an.
-
Gelöst — Zeigt die Empfehlungen an, die gelöst wurden.
-
Ausstehend — Zeigt die Empfehlungen an, deren empfohlene Maßnahmen derzeit ausgeführt werden oder für das nächste Wartungsfenster geplant sind.

-
(Optional) Wählen Sie unter Letzte Änderung den relativen Modus oder den absoluten Modus, um den Zeitraum zu ändern. Auf der Seite „Empfehlungen“ werden die Empfehlungen angezeigt, die in dem Zeitraum generiert wurden. Der Standardzeitraum ist der letzte Monat. Im Modus Absolut können Sie den Zeitraum wählen oder die Uhrzeit in die Felder Startdatum und Enddatum eingeben.
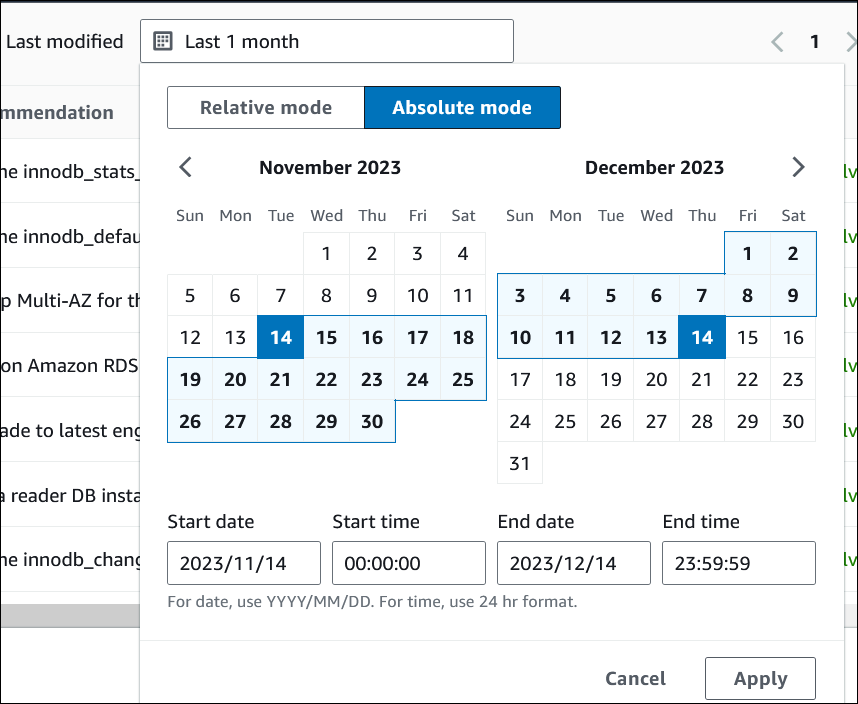
Die Empfehlungen für den eingestellten Zeitraum werden angezeigt.
Beachten Sie, dass Sie alle Empfehlungen für Ressourcen in Ihrem Konto sehen können, indem Sie den Bereich auf Alle setzen.
-
(Optional) Wählen Sie auf der rechten Seite Einstellungen aus, um die anzuzeigenden Details anzupassen. Sie können ein Seitenformat wählen, die Textzeilen umbrechen und die Spalten zulassen oder ausblenden.
(Optional) Wählen Sie eine Empfehlung und dann Details anzeigen aus.

Die Seite mit den Empfehlungsdetails wird angezeigt. Der Titel gibt die Gesamtzahl der Ressourcen an, bei denen das Problem erkannt wurde, und den Schweregrad.
Informationen zu den Komponenten auf der Detailseite für eine auf Anomalien basierende reaktive Empfehlung finden Sie unter Reaktive Anomalien anzeigen im Amazon DevOps Guru-Benutzerhandbuch.
Informationen zu den Komponenten auf der Detailseite für eine auf Schwellenwerten basierende proaktive Empfehlung finden Sie unter. Proaktive Empfehlungen von Performance Insights anzeigen
Bei den anderen automatisierten Empfehlungen werden auf der Seite mit den Empfehlungsdetails die folgenden Komponenten angezeigt:
Empfehlung — Eine Zusammenfassung der Empfehlung und der Angabe, ob Ausfallzeiten erforderlich sind, um die Empfehlung umzusetzen.
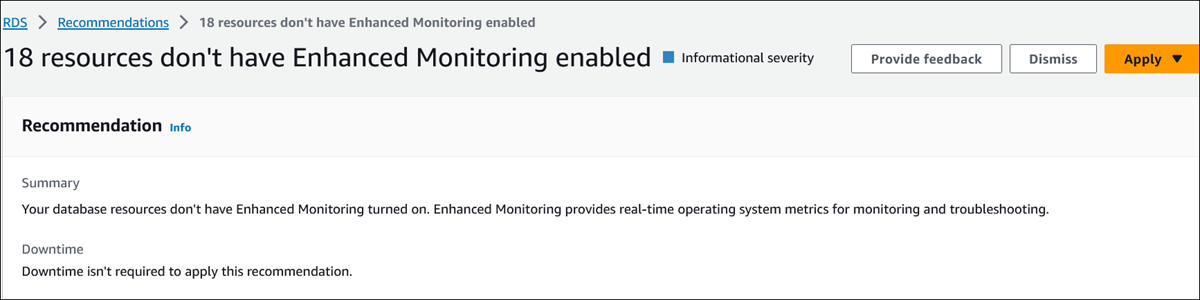
Betroffene Ressourcen — Einzelheiten zu den betroffenen Ressourcen.
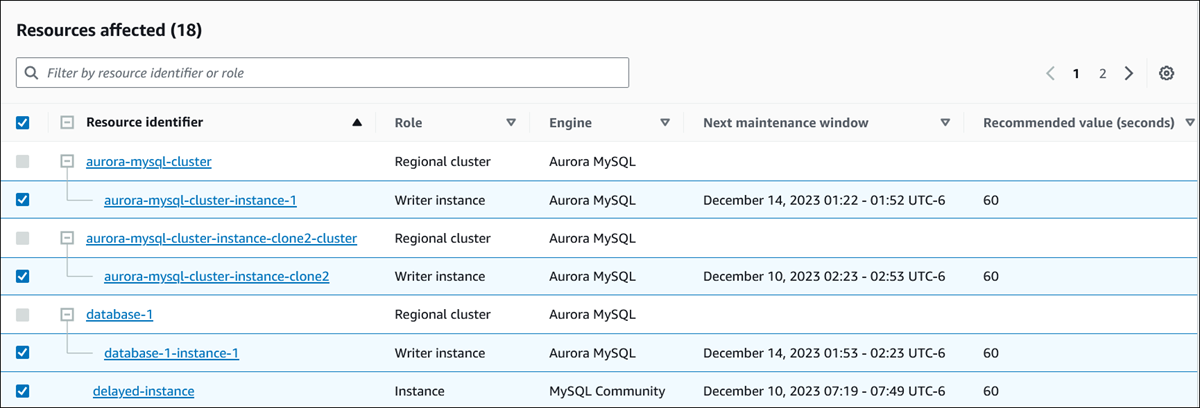
Einzelheiten zur Empfehlung — Informationen zum unterstützten Modul, alle erforderlichen Kosten für die Umsetzung der Empfehlung und Link zur Dokumentation mit weiteren Informationen.

Verwenden Sie den folgenden Befehl in, um RDS Amazon-Empfehlungen für die DB-Instances oder DB-Cluster anzuzeigen AWS CLI.
aws rds describe-db-recommendations
Verwenden Sie die escribeDBRecommendations Operation D RDS API, um RDS Amazon-Empfehlungen mithilfe von Amazon anzuzeigen.
