Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden globaler sekundärer Indizes in DynamoDB
Einige Anwendungen müssen u. U. viele Arten von Abfragen ausführen und verwenden dabei eine Vielzahl von verschiedenen Attributen als Abfragekriterien. Um diese Anforderungen zu unterstützen, können Sie eine oder mehrere globale sekundäre Indizes erstellen und Query-Anforderungen für diese Indizes in Amazon DynamoDB generieren.
Themen
Datensynchronisierung zwischen Tabellen und globalen sekundären Indizes
Überlegungen im Hinblick auf die bereitgestellte Durchsatzkapazität für globale sekundäre Indizes
Erkennen und Korrigieren von Verletzungen von Indexschlüsseln in DynamoDB
Arbeiten mit globalen Sekundärindizes in DynamoDB mithilfe von AWS CLI
Schritt 6: Verwenden eines globalen sekundären Indexes
Betrachten wir ein Beispiel zur Veranschaulichung. Eine Tabelle mit dem Namen GameScores erfasst die Benutzer und Punktzahlen für eine mobile Gaming-Anwendung. Jedes Element in GameScores wird anhand eines Partitionsschlüssels (UserId) und eines Sortierschlüssels (GameTitle) identifiziert. Das folgende Diagramm zeigt, wie die Elemente in der Tabelle organisiert wären. (Es werden nicht alle Attribute angezeigt.)
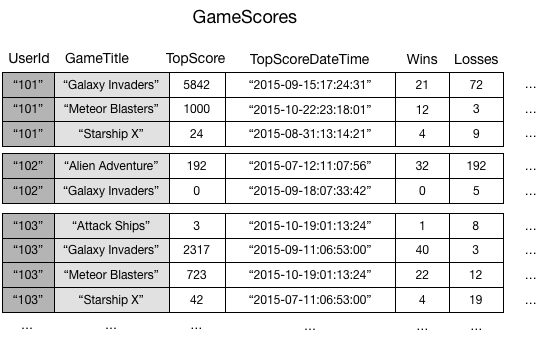
Angenommen, Sie möchten eine Bestenlisten-Anwendung für die Anzeige der höchsten Punktzahlen für jedes Spiel entwickeln. Eine Abfrage, die die Schlüsselattribute (UserId und GameTitle) angibt, wäre äußerst effizient. Wenn die Anwendung Daten aus GameScores nur basierend auf GameTitle abrufen muss, muss sie eine Scan-Operation verwenden. Wenn immer mehr Elemente der Tabelle hinzugefügt werden, werden die Scans aller Daten langsam und ineffizient. Dadurch wird die Beantwortung von folgenden Fragen erschwert:
-
Was ist die höchste Punktzahl, die für das Spiel Meteor Blaster jemals erfasst wurde?
-
Welche Benutzer hatte die höchste Punktzahl für Galaxy Invaders?
-
Wie war das höchste Verhältnis zwischen gewonnen und verlorenen Spielen?
Zum Beschleunigen von Abfragen auf der Basis von Nicht-Schlüsselattributen können Sie einen globalen sekundären Index erstellen. Ein globaler sekundärer Index enthält eine Auswahl von Attributen aus der Basistabelle. Diese sind jedoch nach einem Primärschlüssel organisiert, der sich von dem Schlüssel der Tabelle unterscheidet. Der Indexschlüssel benötigt keinen der Schlüsselattribute aus der Tabelle. Er muss nicht einmal über dasselbe Schlüsselschema verfügen wie eine Tabelle.
Sie können beispielsweise einen globalen sekundären Index mit dem Namen GameTitleIndex mit einem Partitionsschlüssel GameTitle und einem Sortierschlüssel TopScore erstellen. Da die Primärschlüsselattribute der Basistabelle immer in einen Index projiziert werden, ist das Attribut UserId ebenfalls vorhanden. Das folgende Diagramm veranschaulicht, wie der Index GameTitleIndex aussehen würde.

Jetzt können Sie GameTitleIndex abfragen und die Punktzahlen für Meteor Blasters einfach erhalten. Die Ergebnisse werden nach den Sortierschlüsselwerten TopScore sortiert. Wenn Sie den Parameter ScanIndexForward auf False festlegen, werden die Ergebnisse in der absteigender Reihenfolge mit der höchsten Punktzahl zuerst zurückgegeben.
Jeder globale sekundäre Index muss über einen Partitionsschlüssel verfügen und kann einen optionalen Sortierschlüssel besitzen. Das Indexschlüsselschema kann sich vom Basistabellenschema unterscheiden. Sie können eine Tabelle mit einem einfachen Primärschlüssel (Partitionsschlüssel) vorliegen haben und einen globalen sekundären Index mit einem zusammengesetzten Primärschlüssel (Partitions- und Sortierschlüssel) erstellen oder umgekehrt. Die Indexschlüsselattribute können aus beliebigen Top-Level-Attributen vom Typ String, Number oder Binary der Basistabelle bestehen. Andere Skalar-, Dokument- und Satztypen sind nicht zulässig.
Sie können andere Basistabellenattribute in den Index projizieren, wenn Sie möchten. Wenn Sie den Index abfragen, kann DynamoDB diese projizierten Attribute effizient abrufen. Globale sekundäre Index-Abfragen können jedoch keine Attribute aus der Basistabelle abrufen. Wenn Sie beispielsweise GameTitleIndex wie im Diagramm oben veranschaulicht abgefragt haben, kann die Abfrage nicht auf Nicht-Schlüsselattribute außer TopScore zugreifen (die Schlüsselattribute GameTitle und UserId werden allerdings automatisch projiziert).
In einer DynamoDB-Tabelle, muss jeder Schlüsselwert eindeutig sein. Die Schlüsselwerte in einem globalen sekundären Index müssen jedoch nicht eindeutig sein. Beispiel: Angenommen, ein Spiel mit dem Namen Comet Quest ist besonders schwierig. Viele neue Benutzer probieren es aus, schaffen es aber nicht, eine Punktzahl über Null zu erreichen. Im Folgenden finden Sie einige der Daten, die dies veranschaulichen.
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
Wenn diese Daten der Tabelle GameScores hinzugefügt werden, verteilt DynamoDB sie auf GameTitleIndex. Wenn wir dann den Index mit Comet Quest für GameTitle und mit 0 für TopScore abfragen, werden die folgenden Daten zurückgegeben.
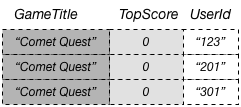
Es werden nur die Elemente mit den angegebenen Schlüsselwerten in der Antwort angezeigt. Innerhalb dieser Datengruppe werden die Elemente nicht in einer bestimmten Reihenfolge angezeigt.
Ein globaler sekundärer Index verfolgt nur Datenelemente, bei denen die Schlüsselattribute tatsächlich vorhanden sind. Angenommen, Sie haben der Tabelle GameScores ein neues Element hinzugefügt, jedoch nur die erforderlichen Primärschlüsselattribute bereitgestellt.
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
Da Sie das Attribut TopScore nicht angegeben haben, verteilt DynamoDB dieses Element nicht über GameTitleIndex. Wenn Sie GameScores für alle Comet Quest-Elemente abfragen, erhalten Sie die folgenden vier Elemente:
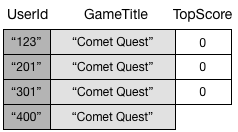
Eine ähnliche Abfrage für GameTitleIndex gibt drei Elemente statt vier zurück. Der Grund hierfür ist, dass das Element mit dem nicht vorhandenen TopScore nicht an den Index verteilt wird.
Attributprojektionen
Eine Projektion ist der Satz von Attributen, die aus einer Tabelle in einen sekundären Index kopiert werden. Der Partitionsschlüssel und der Sortierschlüssel der Tabelle werden immer in den Index projiziert. Sie können andere Attribute projizieren, um die Abfrageanforderungen Ihrer Anwendung zu unterstützen. Wenn Sie einen Index abfragen, kann Amazon DynamoDB auf jedes Attribut in der Projektion zugreifen, als ob sich diese Attribute in einer eigenen Tabelle befinden.
Wenn Sie einen sekundären Index erstellen, müssen Sie die Attribute angeben, die in den Index projiziert werden. DynamoDB bietet hierfür drei verschiedene Optionen:
-
KEYS_ONLY – Jeder Eintrag im Index besteht nur aus dem Tabellenpartitionsschlüssel und Sortierschlüsselwerten, sowie den Indexschlüsselwerten. Die Option
KEYS_ONLYführt zu dem kleinstmöglichen sekundären Index. -
INCLUDE – Zusätzlich zu den in
KEYS_ONLYbeschriebenen Attributen, enthält der sekundäre Index andere Nicht-Schlüsselattribute, die Sie angeben. -
ALL – Der sekundäre Index enthält alle Attribute der Quelltabelle. Da alle Tabellendaten im Index dupliziert werden, wird ein
ALL-Projektion führt zu dem größtmöglichen sekundären Index.
Im vorherigen Diagramm verfügt GameTitleIndex nur über ein projiziertes Attribut: UserId. Obwohl eine Anwendung die UserId der besten Ergebnisse für jedes Spiel mit GameTitle und TopScore effizient in Abfragen bestimmen kann, ist es nicht möglich, effizient die höchste Punktzahl für ein bestimmtes Spiel oder das höchste Verhältnis gewonnener und verlorener Spiele bei den besten Ergebnissen zu bestimmen. Dazu muss eine zusätzliche Abfrage der Basistabelle durchgeführt werden, um die gewonnen und verlorenen Spiele für jedes beste Ergebnis abzurufen. Abfragen für diese Daten lassen sich effizienter unterstützen, indem diese Attribute aus der Basistabelle in den globalen sekundären Index projiziert werden, wie in folgendem Diagramm dargestellt.
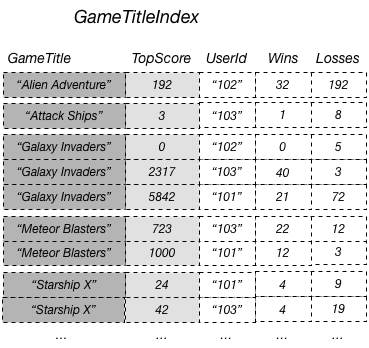
Da die Nicht-Schlüsselattribute Wins und Losses in den Index projiziert werden, kann eine Anwendung das Verhältnis zwischen Siegen und Niederlagen für jedes Spiel oder für eine beliebige Kombination aus Spiel und Benutzer-ID bestimmen.
Wenn Sie die Attribute zum Projizieren in einen globalen sekundären Index auswählen, müssen Sie die Differenz der Kosten des bereitgestellten Durchsatzes und der Speicherkosten berücksichtigen:
-
Wenn Sie nur auf wenige Attribute mit möglichst niedriger Latenz zugreifen müssen, erwägen Sie, nur diese Attribute in einen globalen sekundären Index zu projizieren. Je kleiner der Index, desto geringer die Speicher- und somit die Schreibkosten.
-
Greift Ihre Anwendung häufig auf einige Nicht-Schlüsselattribute zu, sollten Sie erwägen, diese Attribute in einen globalen sekundären Index zu projizieren. Die zusätzlichen Speicherkosten für den globalen sekundären Index wiegen die Kosten für die Durchführung häufiger Tabellen-Scans auf.
-
Wenn Sie auf die meisten Nicht-Schlüsselattribute in regelmäßigen Abständen zugreifen müssen, können Sie diese Attribute – oder sogar die gesamte Basistabelle – in einen globalen sekundären Index projizieren. Dadurch erhalten Sie maximale Flexibilität. Ihre Speicherkosten würden allerdings steigen oder sich sogar verdoppeln.
-
Wenn Ihre Anwendung eine Tabelle selten abfragen, jedoch viele Schreibvorgänge oder Updates für die Daten in der Tabelle durchführen muss, erwägen Sie das Projizieren von
KEYS_ONLY. Der globale sekundäre Index wäre nur klein, stünde aber weiterhin bei Bedarf für Abfrageaktivitäten zur Verfügung.
Lesen von Daten aus einem globalen sekundären Index
Sie können Elemente aus einem globalen sekundären Index mithilfe von Query und Scan verwenden. Die GetItem und BatchGetItem-Operationen können für einen globalen sekundären Index nicht verwendet werden.
Abfragen eines globalen sekundären Index
Sie können die Query-Operation für den Zugriff auf ein oder mehrere Elemente in einem globalen sekundären Index verwenden. Die Abfrage muss den Namen der Basistabelle und den Namen des Index, den Sie verwenden möchten, die Attribute, die in den Abfrageergebnissen zurückgegeben werden sollen, und etwaige Abfragebedingungen, die Sie anwenden möchten, angeben. DynamoDB kann Ergebnisse in auf- oder absteigender Reihenfolge liefern.
Sehen Sie sich die folgenden Daten an, die von einer Query zurückgegeben wurden, die Spieledaten für eine Bestenlisten-Anwendung abfragt.
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
Vorgänge in dieser Abfrage:
-
DynamoDB greift zu und verwendet den GameTitlePartitionsschlüssel GameTitleIndex, um die Indexelemente für Meteor Blasters zu finden. Alle Indexelemente mit diesem Schlüssel werden nebeneinander gespeichert, um ein schnelles Abrufen zu ermöglichen.
-
In diesem Spiel verwendet DynamoDB den Index, um auf alle Benutzer IDs - und Top-Scores für dieses Spiel zuzugreifen.
-
Die Ergebnisse werden in absteigender Reihenfolge sortiert zurückgegeben, da der Parameter
ScanIndexForwardauf False festgelegt ist.
Scannen eines globalen sekundären Index
Sie können die Scan-Operation zum Abrufen aller Daten aus einem globalen sekundären Index verwenden. Geben Sie dazu den Namen der Basistabelle sowie den Indexnamen in der Abfrage an. Mit einer Scan-Operation liest DynamoDB alle Daten im Index und gibt sie an die Anwendung zurück. Sie können auch anfordern, dass nur einige der Daten zurückgegeben und die verbleibenden Daten verworfen werden. Verwenden Sie dazu den Parameter FilterExpression der Scan-Operation. Weitere Informationen finden Sie unter Filterausdrücke für Scan.
Datensynchronisierung zwischen Tabellen und globalen sekundären Indizes
DynamoDB synchronisiert automatisch jeden globalen sekundären Index mit der Basistabelle. Wenn eine Anwendung Elemente in eine Tabelle schreibt oder daraus löscht, werden globale sekundäre Indizes in dieser Tabelle mit einem Eventually-Consistent-Modell asynchron aktualisiert. Anwendungen schreiben niemals direkt in einen Index. Allerdings ist es wichtig, zu wissen, welche Auswirkungen es hat, wie DynamoDB diese Indizes verwaltet.
Globale sekundäre Indizes erben den read/write Kapazitätsmodus aus der Basistabelle. Weitere Informationen finden Sie unter Überlegungen beim Wechseln der Kapazitätsmodi in DynamoDB.
Wenn Sie einen globalen sekundären Index erstellen, geben Sie ein oder mehrere Indexschlüsselattribute und deren Datentypen an. Das bedeutet, dass wenn Sie ein Element in die Basistabelle schreiben, die Datentypen für diese Attribute den Datentypen des Indexschlüsselschemas entsprechen müssen. Im Fall von GameTitleIndex wird der Partitionsschlüssel GameTitle im Index als Datentyp String definiert. Der Sortierschlüssel TopScore im Index ist vom Typ Number. Wenn Sie versuchen, der Tabelle GameScores ein Element hinzuzufügen und einen anderen Datentyp entweder für GameTitle oder TopScore anzugeben, gibt DynamoDB eine ValidationException aufgrund der fehlenden Übereinstimmung des Datentyps zurück.
Wenn Sie Elemente in eine Tabelle schreiben oder daraus löschen, werden die globalen sekundären Indizes in dieser Tabelle in Eventually Consistent-Form aktualisiert. Änderungen an den Tabellendaten werden unter normalen Bedingungen im Bruchteil einer Sekunde auf die globalen sekundären Indizes verteilt. In einigen seltenen Fehlerszenarien können längere Verzögerungen bei der Verteilung auftreten. Ihre Anwendungen sollten daher Situationen abhelfen können, in denen eine Abfrage für einen globalen sekundären Index Ergebnisse zurückgibt, die nicht auf dem neuesten Stand sind.
Wenn Sie ein Element in eine Tabelle schreiben, müssen Sie keine Attribute für globale sekundäre Index-Sortierschlüssel angeben. Bei GameTitleIndex müssen Sie z. B. keinen Wert für das Attribut TopScore angeben, um ein neues Element in die Tabelle GameScores zu schreiben. In diesem Fall schreibt DynamoDB keine Daten in den Index für dieses bestimmte Element.
Eine Tabelle mit vielen globalen sekundären Indizes verursacht höhere Kosten für Schreibaktivitäten als Tabellen mit weniger Indizes. Weitere Informationen finden Sie unter Überlegungen im Hinblick auf die bereitgestellte Durchsatzkapazität für globale sekundäre Indizes.
Tabellenklassen mit globalen sekundären Indizes
Ein globaler sekundärer Index verwendet immer dieselbe Tabellenklasse wie seine Basistabelle. Jedes Mal, wenn ein neuer globaler sekundärer Index für eine Tabelle hinzugefügt wird, verwendet der neue Index dieselbe Tabellenklasse wie seine Basistabelle. Wenn die Tabellenklasse einer Tabelle aktualisiert wird, werden auch alle zugehörigen globalen sekundären Indizes aktualisiert.
Überlegungen im Hinblick auf die bereitgestellte Durchsatzkapazität für globale sekundäre Indizes
Wenn Sie einen globalen sekundären Index für eine Tabelle mit dem Modus bereitgestellter Kapazität erstellen, müssen Sie Lese- und Schreibkapazitätseinheiten für den erwarteten Workload dieses Indexes angeben. Die Einstellungen für den bereitgestellten Durchsatz eines globalen sekundären Indizes sind getrennt von denen der Basistabelle. Eine Query-Operation auf einem globalen sekundären Index verbraucht Lesekapazitätseinheiten des Index und nicht der Basistabelle. Wenn Sie Elemente in eine Tabelle schreiben, sie aktualisieren oder aus der Tabelle löschen, werden die globalen sekundären Indizes in dieser Tabelle in Eventually Consistent-Form aktualisiert. Diese Indexaktualisierungen verbrauchen Kapazitätseinheiten des Indexes und nicht der Basistabelle.
Wenn Sie beispielsweise eine Query-Operation für einen ausführen und die bereitgestellte Lesekapazität überschreiten, wird die Anforderung gedrosselt. Wenn Sie viele Schreibaktivitäten für die Tabelle ausführen, ein globaler sekundärer Index dieser Tabelle jedoch über nicht genügend Schreibkapazität verfügt, dann wird die Schreibaktivität der Tabelle gedrosselt.
Wichtig
Damit es zu keiner Ablehnung kommt, sollte die bereitgestellte Kapazität für Schreibvorgänge bei einem globalen sekundären Index gleich oder größer als die Kapazität für Schreibvorgänge der Basistabelle sein, da neue Aktualisierungen in die Basistabelle und den globalen sekundären Index geschrieben werden.
Verwenden Sie zum Anzeigen der Einstellungen des bereitgestellten Durchsatzes für einen globalen sekundären Index die DescribeTable-Operation. Es werden detaillierte Informationen zu globalen sekundären Indizes für die Tabelle zurückgegeben.
Lesekapazitätseinheiten
Globale sekundäre Indizes unterstützen Eventually Consistent-Lesevorgänge, die jeweils eine halbe Lesekapazitätseinheit verbrauchen. Das bedeutet, dass eine einzelne globale sekundäre Index-Abfrage bis zu 2 × 4 KB = 8 KB pro Lesekapazitätseinheit abrufen kann.
Für globale sekundäre Index-Abfragen berechnet DynamoDB die bereitgestellten Lesevorgänge auf die gleiche Weise wie für Abfragen der Tabellen. Der einzige Unterschied besteht darin, dass die Berechnung auf der Größe der Indexeinträge und nicht auf der Größe des Elements in der Basistabelle beruht. Die Anzahl der Lesekapazitätseinheiten ist die Summe aller projizierten Attributgrößen sämtlicher zurückgegebener Elemente. Das Ergebnis wird dann auf den nächsten 4 KB-Grenzwert aufgerundet. Weitere Informationen darüber, wie DynamoDB die bereitgestellte Durchsatznutzung berechnet, finden Sie unter Bereitgestellter Kapazitätsmodus von DynamoDB.
Die maximale Größe der von einer Query-Operation zurückgegebenen Ergebnisse beträgt 1MB. Diese umfasst die Größen aller Attributnamen und Werte sämtlicher zurückgegebenen Elemente.
Nehmen wir als Beispiel einen globalen sekundären Index bei dem jedes Element 2 000 Byte Daten enthält. Angenommen, Sie führen eine Query-Operation für diesen Index aus, bei der KeyConditionExpression 8 Elemente zurückgegeben werden. Die Gesamtgröße der übereinstimmenden Elemente beträgt: 2 000 Byte x 8 Elemente = 16 000 Byte. Das Ergebnis wird dann auf den nächsten 4-KB-Grenzwert aufgerundet. Da globale sekundäre Index-Abfragen Eventually Consistent ausgeführt werden, belaufen sich die Gesamtkosten auf 0,5 (16 KB/ 4 KB) oder 2 Lesekapazitätseinheiten.
Schreibkapazitätseinheiten
Wenn ein Element in einer Tabelle hinzugefügt, aktualisiert oder gelöscht wird und ein globaler sekundärer Index davon betroffen ist, dann belegt der globale sekundäre Index bereitgestellte Schreibkapazitätseinheiten für die Operation. Die Gesamtkosten für den bereitgestellten Durchsatz ergeben sich aus der Summe der Schreibkapazitätseinheiten, die durch Schreiben in die Basistabelle verbraucht wurden, und der durch Aktualisieren der globalen sekundären Indizes belegten Einheiten. Hinweis: Wenn ein Schreibvorgang in eine Tabelle keine globale sekundäre Index-Aktualisierung erfordert, wird keine Schreibkapazität vom Index verbraucht.
Damit ein Tabellenschreibvorgang erfolgreich ausgeführt wird, muss der für die Tabelle und alle zugehörigen globalen sekundären Indizes bereitgestellte Durchsatz genügend Kapazität aufweisen. Andernfalls wird der Schreibvorgang in die Tabelle gedrosselt.
Wichtig
Bei der Erstellung eines globalen sekundären Index (GSI) können Schreibvorgänge in die Basistabelle gedrosselt werden, wenn die GSI-Aktivität, die sich aus Schreibvorgängen in die Basistabelle ergibt, die bereitgestellte Schreibkapazität der GSI überschreitet. Diese Drosselung wirkt sich auf alle Schreibvorgänge aus, vom Indizierungsprozess bis hin zur möglichen Unterbrechung Ihrer Produktionsworkloads. Weitere Informationen finden Sie unter Problembehandlung bei der Drosselung in Amazon DynamoDB.
Die Kosten für das Schreiben eines Elements in einen globalen sekundären Index hängen von mehreren Faktoren ab:
-
Wenn Sie ein neues Element in die Tabelle schreiben, die ein indiziertes Attribut definiert, oder ein vorhandenes Element zum Definieren eines zuvor nicht definierten indizierten Attributs aktualisieren, ist ein Schreibvorgang erforderlich, um das Element in den Index einzufügen.
-
Wenn eine Aktualisierung der Tabelle den Wert eines indizierten Schlüsselattributs (von A in B) ändert, sind zwei Schreibvorgänge erforderlich, und zwar einer zum Löschen des vorherigen Elements aus dem Index und einer zum Schreiben des neuen Elements in den Index.
-
Wenn ein Element im Index vorhanden war, ein Schreibvorgang in der Tabelle jedoch dazu führte, dass das indizierte Attribut gelöscht wurde, ist ein Schreibvorgang erforderlich, um die alte Elementprojektion im Index zu löschen.
-
Wenn ein Element nicht im Index vorhanden ist, bevor oder nachdem das Element aktualisiert wird, fallen keine zusätzlichen Kosten für das Schreiben in den Index an.
-
Wenn durch eine Aktualisierung der Tabelle nur der Wert von projizierten Attributen im Indexschlüsselschema, nicht aber der Wert von indizierten Schlüsselattributen geändert wird, ist ein Schreibvorgang erforderlich, um die Werte der projizierten Attribute im Index zu aktualisieren.
Alle diese Faktoren setzen voraus, dass die Größe der einzelnen Elemente im Index kleiner oder gleich der 1-KB- Elementgröße für das Berechnen der Schreibkapazitätseinheiten ist. Größere Indexeinträge erfordern zusätzliche Schreibkapazitätseinheiten. Sie können Ihre Kosten für Schreibvorgänge minimieren, indem Sie überlegen, welche Attribute Ihre Abfragen zurückgeben müssen, und nur diese Attribute in den Index projizieren.
Speicherüberlegungen für globale sekundäre Indizes
Wenn eine Anwendung ein Element in eine Tabelle schreibt, kopiert DynamoDB automatisch die richtige Teilmenge der Attribute in den globalen sekundären Index, in dem diese Attribute angezeigt werden sollen. Ihr AWS Konto wird für die Speicherung des Elements in der Basistabelle und auch für die Speicherung von Attributen in allen globalen Sekundärindizes dieser Tabelle belastet.
Der Speicherplatz, der von einem Indexelement belegt wird, ergibt sich aus der Summe von folgenden Werten:
-
Die Größe in Byte des Primärschlüssels der Basistabelle (Partitionsschlüssel und Sortierschlüssel)
-
Die Größe in Byte des Indexschlüsselattributs
-
Die Größe in Byte der projizierten Attribute (sofern vorhanden)
-
100 Bytes des Overheads pro Indexelement
Zur Schätzung der Speicheranforderungen für einen globalen sekundären Index können Sie die durchschnittliche Größe eines Elements im Index schätzen und diesen Wert mit der Anzahl der Elemente in der Basistabelle multiplizieren, die die globalen sekundären Index-Schlüsselattribute besitzen.
Wenn eine Tabelle ein Element enthält, in dem ein bestimmtes Attribut nicht definiert ist, dieses Attribut aber als Indexpartitionsschlüssel festgelegt ist, schreibt DynamoDB für dieses Element keine Daten in den Index.
