Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden globaler Sekundärindizes für materialisierte Aggregationsabfragen in DynamoDB
Die Wartung von Aggregationen, die beinahe in Echtzeit ausgeführt werden, und Schlüsselmetriken für Daten, die sich schnell verändern, wird zunehmend wichtiger für Unternehmen, um schnell Entscheidungen treffen zu können. Bei einer Musikbibliothek sollen beispielsweise die am häufigsten heruntergeladenen Titel beinahe in Echtzeit angezeigt werden.
Betrachten Sie das folgende Tabellenlayout für diese Musikbibliothek:
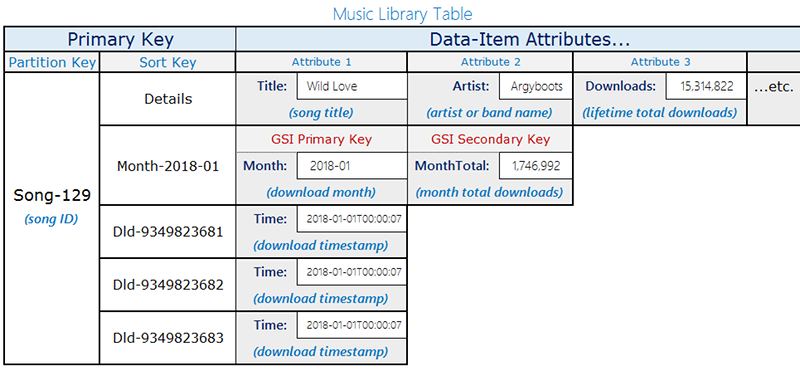
Die Tabelle in diesem Beispiel speichert Titel mit der songID als Partitionsschlüssel. Sie können für diese Tabelle Amazon DynamoDB Streams aktivieren und den Streams eine Lambda-Funktion anfügen, sodass beim Download der einzelnen Titel der Tabelle ein Eintrag mit Partition-Key=SongID und Sort-Key=DownloadID hinzugefügt wird. Wenn diese Aktualisierungen erfolgen, lösen sie in DynamoDB Streams eine Lambda-Funktion aus. Die Lambda-Funktion kann die Downloads aggregieren, nach songID gruppieren und das Element auf der obersten Ebene, Partition-Key=songID, und Sort-Key=Month aktualisieren. Beachten Sie, dass der Versuch wiederholt werden kann und der Wert mehrmals aggregiert wird, wenn eine Lambda-Ausführung unmittelbar nach dem Schreiben des neuen aggregierten Werts fehlschlägt, sodass Sie einen ungefähren Wert erhalten.
Um die Updates mit einer Latenz im einstelligen Millisekundenbereich beinahe in Echtzeit zu lesen, verwenden Sie den globalen sekundären Index mit den Abfragebedingungen Month=2018-01, ScanIndexForward=False, Limit=1.
Eine weitere hier verwendete wichtige Optimierung besteht darin, dass es sich beim globalen sekundären Index um einen Sparse Index handelt und dieser nur für die Elemente verfügbar ist, die für den Abruf der Daten in Echtzeit abgefragt werden müssen. Der globale sekundäre Index kann zusätzliche Workflows unterstützen, die Informationen zu den beliebtesten 10 Titeln oder zu den im betreffenden Monat heruntergeladenen Titeln benötigen.
