Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden des globalen sekundären Index-Schreib-Shardings für selektive Tabellenabfragen
Anwendungen müssen häufig eine kleine Teilmenge von Elementen in einer Amazon-DynamoDB-Tabelle identifizieren, die eine bestimmte Bedingung erfüllen. Wenn diese Elemente zufällig auf die Partitionsschlüssel der Tabelle verteilt werden, können Sie auf einen Tabellenscan zurückgreifen, um sie abzurufen. Diese Option kann teuer sein, funktioniert aber gut, wenn eine große Anzahl von Elementen in der Tabelle die Suchbedingung erfüllt. Wenn der Schlüsselraum jedoch groß ist und die Suchbedingung sehr selektiv ist, kann diese Strategie eine Menge unnötiger Verarbeitung verursachen.
Eine bessere Lösung ist ggf., die Daten abzufragen. Um selektive Abfragen über den gesamten Schlüsselbereich zu ermöglichen, können Sie Schreib-Sharding verwenden, indem Sie jedem Element, das Sie für den globalen sekundären Indexpartitionsschlüssel verwenden, ein Attribut hinzufügen, das einen (0-N)-Wert enthält.
Im Folgenden finden Sie ein Beispiel für ein Schema, das dies in einem kritischen Ereignisworkflow verwendet:
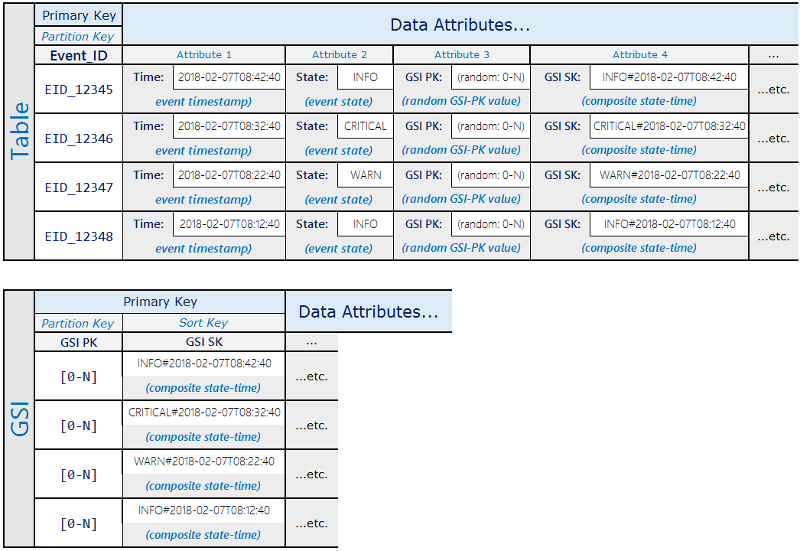
Mit diesem Schemaentwurf werden die Ereigniselemente auf 0-N-Partitionen auf der GSI verteilt, sodass ein Streulesen mithilfe einer Sortierbedingung auf dem zusammengesetzten Schlüssel alle Elemente mit einem bestimmten Status während eines bestimmten Zeitraums abgerufen werden kann.
Dieses Schemamuster liefert eine hochselektive Ergebnismenge zu minimalen Kosten, ohne dass ein Tabellenscan erforderlich ist.
